【机器学习】集成学习与模型融合方法举例
文章目录 1 概述 1.1 什么是集成学习 2 CrossValidation 交叉验证 3 stacking 4 Voting投票器 5 Bagging 1 概述1.1 什么是集成学习
所谓“三个臭皮匠赛过诸葛亮”的道理,在机器学习数据挖掘的工程项目中,使用单一决策的弱分类器显然不是一个明智的选择,因为各种分类器在设计的时候都有自己的优势和缺点,也就是说每个分类器都有自己工作偏向,那集成学习就是平衡各个分类器的优缺点,使得我们的分类任务完成的更加优秀。 在大多数情况下,这些基本模型本身的性能并不是非常好,这要么是因为它们具有较高的偏差(例如,低自由度模型),要么是因为他们的方差太大导致鲁棒性不强(例如,高自由度模型)。集成方法的思想是通过将这些弱学习器的偏差和/或方差结合起来,从而创建一个「强学习器」(或「集成模型」),从而获得更好的性能。 集成学习的方法:
1.基于投票思想的多数票机制的集成分类器(MajorityVoteClassifier) 2.基于bagging思想的套袋集成技术(BaggingClassifier) 3.基于boosting思想的自适应增强方法(Adaboost) 4.分层模型集成框架stacking(叠加算法)
基于投票思想的多数票机制的集成分类器(MajorityVoteClassifier) 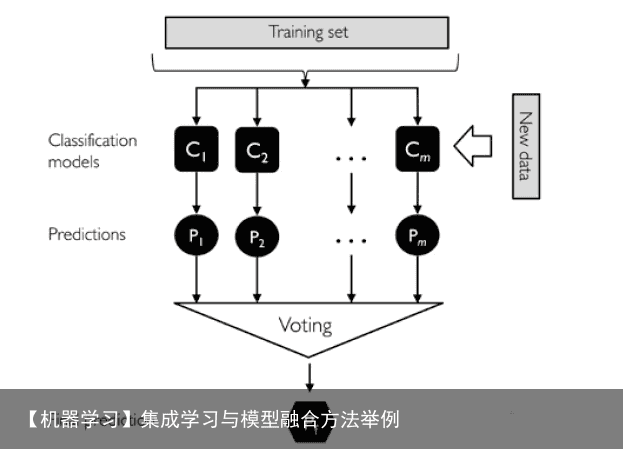
 分别训练n个弱分类器。 对每个弱分类器输出预测结果,并投票(如下图) 每个样本取投票数最多的那个预测为该样本最终分类预测。
分别训练n个弱分类器。 对每个弱分类器输出预测结果,并投票(如下图) 每个样本取投票数最多的那个预测为该样本最终分类预测。
分层模型集成框架stacking(叠加算法)
Stacking集成算法可以理解为一个两层的集成,第一层含有一个分类器,把预测的结果(元特征)提供给第二层, 而第二层的分类器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。
标准的Stacking,也叫Blending如下图: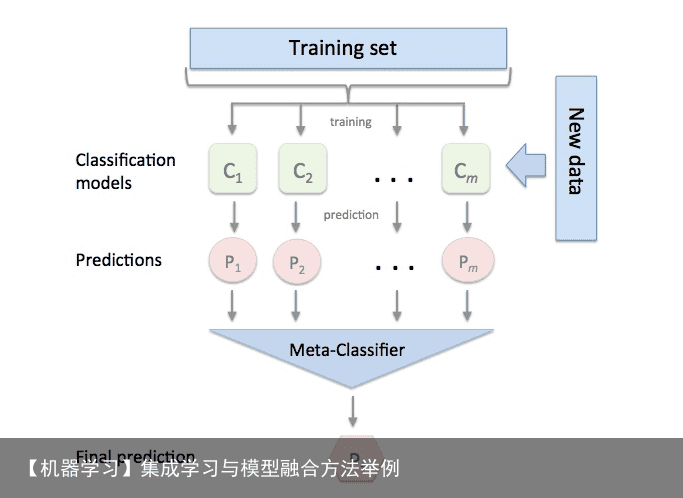
训练集,测试集,和验证集三者之间的关系:
首先要了解到我们的数据集一般分为训练集,测试集,和验证集,训练集主要是训练,验证集主要是为了验证模型的性能,从而选择不同的模型参数,测试集就是进行最终模型的测试,比如准确率是多少,这里的最终模型一般指的是经过验证集从而选择合适的参数从而得到的模型,因此三者之间的关系大概就是这样的。什么是交叉验证:
以5 折交叉验证举例(留一法等就不做介绍了),将我们的数据集平均分5份:A1,A2,A3,A4,A5,然后不断的选取其中的四份做训练集,另外一份做验证集,训练过程如下 模型M1: 在{A2,A3,A4,A5}基础上构建模型M1,并对数据集A1进行验证,将预测值与真值进行比较,在某一评价标准下,计算一个得分a1,1(代表模型M1对A1验证集的预测得分) . 在{A1,A3,A4,A5} 基础上构建模型M1,并对数据集A2进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,2 . …… 在{A1,A2,A3,A4} 基础上构建模型,并对数据集A5进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,5 . a1=a1,1+a1,2+…+a1,5/5 作为模型M1的综合得分。为什么要有交叉验证:
1、为了更好地对数据进行学习,特别是样本数据比较小的时候,这样的话样本中的全部数据都被学习过了,可以说是学习了样本的全部分布 2、在过拟合和预测误差之间做一个平衡,好的模型是对数据有精确的预测,而不是对数据进行好的拟合,也就是说我们的模型要有泛化性能,经过交叉验证的模型一般都很好的做到了这一点。 3 stacking在数据比赛中,stacking是一个很好的模型融合方法,通过融合多个模型来达到更好的效果,相当于“三个臭皮匠顶个诸葛亮”,stacking方法中用到了交叉验证,所以上述相对交叉验证进行了学习说明。
下图需结合着文字一起看 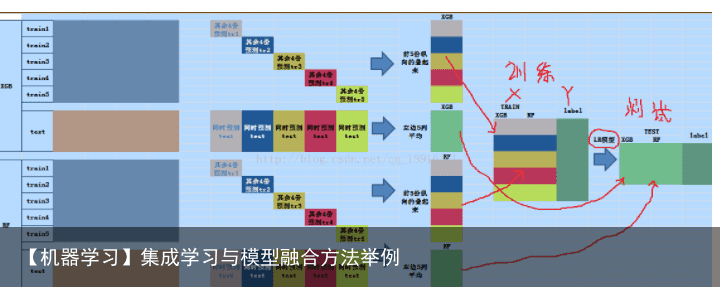 例子: XGBoost模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
例子: XGBoost模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型 测试集 的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对 testing data 数据预测的5列2000行的数据a1,a2,a3,a4,a5,对 testing set 的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个testing data的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为新的训练集+(label还是原来真实的label),B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为对应的新的测试集。
这样的话我们就可以进行新模型的搭建,比如搭建一个LR模型,A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为输入X,原来的label作为 Y ,训练模型,并且利用新的测试集进行预测。
以上即为stacking的完整步骤!
Ensemble learning 中文名叫做集成学习,它并不是一个单独的机器学习算法,而是将很多的机器学习算法结合在一起,我们把组成集成学习的算法叫做“个体学习器”。在集成学习器当中,个体学习器都相同,那么这些个体学习器可以叫做“基学习器”。
个体学习器组合在一起形成的集成学习,常常能够使得泛化性能提高,这对于“弱学习器”的提高尤为明显。弱学习器指的是比随机猜想要好一些的学习器。
在进行集成学习的时候,我们希望我们的基学习器应该是好而不同,这个思想在后面经常体现。 “好”就是说,你的基学习器不能太差,“不同”就是各个学习器尽量有差异。
集成学习有两个分类,一个是个体学习器存在强依赖关系、必须串行生成的序列化方法,以Boosting为代表。另外一种是个体学习器不存在强依赖关系、可同时生成的并行化方法,以Bagging和随机森林(Random Forest)为代表。 将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
4 Voting投票器Voting可以说是一种最为简单的模型融合方式。假如对于一个二分类模型,有3个基础模型,那么就采取投票的方式,投票多者为最终的分类。在sklearn实现如下:
from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier, VotingClassifier clf1 = LogisticRegression(random_state=1) clf2 = RandomForestClassifier(random_state=1) clf3 = GaussianNB() eclf = VotingClassifier(estimators=[(lr, clf1), (rf, clf2), (gnb, clf3)]) eclf = eclf1.fit(x_train,y_train) print(eclf1.predict(x_test)) 5 BaggingBagging的思想是利用抽样生成不同的训练集,进而训练不同的模型,将这些模型的输出结果综合(投票或平均的方式)得到最终的结果。Bagging本质上是利用了模型的多样性,改善算法整体的效果。Bagging的重点在于不同训练集的生成,这里使用了一种名为Bootstrap的方法,即有放回的重复随机抽样,从而生成不同的数据集。具体流程如下图所示: 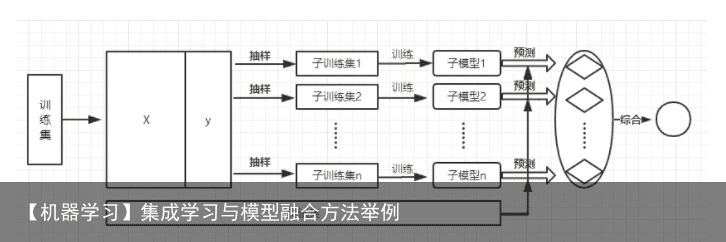
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【机器学习】集成学习与模型融合方法举例 https://www.yhzz.com.cn/a/12229.html