在上一篇文章中,我们将数据集的标注信息单独保存在一个变量 datas 中,这是为了在使用yolo3进行训练时,可以更好地读取图片以及图片中的目标信息。本篇文章首先介绍如何进行图像文件以及对应信息的读取。此外,我们采集的数据集较少,需要对其进行增广处理,即采用一定的手法增加数据集的数量,以达到扩充数据集的目的。
一、数据集的读取 首先我们回顾一下上一篇文章中保存的信息结构: 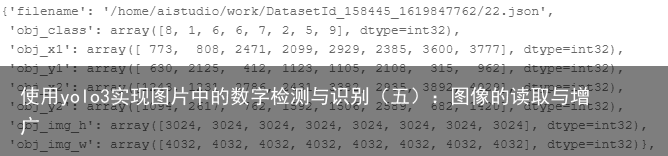 第一行是标注信息文件的路径;第二行是所有目标的标签值;第三行到第六行是每个目标的位置(使用(x1,y1,x2,y2)坐标方法);第七行和第八行是对应输入图像的尺寸。
第一行是标注信息文件的路径;第二行是所有目标的标签值;第三行到第六行是每个目标的位置(使用(x1,y1,x2,y2)坐标方法);第七行和第八行是对应输入图像的尺寸。
首先我们需要获取标注信息对应的图片路径。从文件结构中可以看到,图像数据的名称和对应的标注信息名称相同,而且二者在同一个文件夹中,因此我们只需更改标注信息文件名称的后缀即可。实现代码如下:
import os import matplotlib.pyplot as plt from matplotlib.image import imread data=datas[0] filename=data[filename] # 获取文件名称 # 替换文件后缀,获取图像路径 name_split=os.path.splitext(filename) imgname=name_split[0]+.jpeg # 显示图像文件,观察名称是否正确 img=cv2.imread(imgname) img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 因为cv2图像格式为BGR,需要将其转换为RGB plt.imshow(img)显示图像文件,观察获取的名称是否正确:  可以正常读取图像,接下来,我们读取目标类别与目标位置:
可以正常读取图像,接下来,我们读取目标类别与目标位置:
第一个目标位置坐标(坐标格式为(x1,y1,x2,y2)):
我们将此过程封装成函数,函数名为 img_read :
import os import matplotlib.pyplot as plt from matplotlib.image import imread import numpy as np # 定义一个函数,来根据标注信息读取文件中的图片,data变量存储了某一个图像的标注信息 def img_read(data): filename=data[filename] # 获取文件名称 # 替换文件后缀,获取图像路径 name_split=os.path.splitext(filename) imgname=name_split[0]+.jpeg # 读取图像 img=cv2.imread(imgname) img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 因为cv2图像格式为BGR,需要将其转换为RGB obj_class=data[obj_class] # 获取目标标签(类别) # 获取目标位置 obj_location=np.vstack((data[obj_x1],data[obj_y1],data[obj_x2],data[obj_y2])) return img,obj_class,obj_location使用该函数读取一张图片进行显示:
[img,obj_class,obj_location]=img_read(datas[10]) plt.imshow(img)显示结果为: 
我们可以通过改变图像色调(对比度、亮暗、颜色等)、缩放、裁剪等方法生成更多的图像,以达到数据集扩充的目的,下面将一一对这些方法进行介绍:
1.随机改变图像色调通过随机改变图像的对比度、亮暗以及色度可以实现图像色调的随机改变,随机改变亮度可通过如下代码实现:
# 产生一个0.5-1.5的随机数,用于表示亮度的调节程度 t=np.random.uniform(0.5,1.5) imag=Image.fromarray(img) # 进行亮度调节 imag=ImageEnhance.Brightness(imag).enhance(t) # 显示图像 plt.imshow(imag)原始图片为:  改变亮度后的图片为:
改变亮度后的图片为:  随机调节对比度的代码如下:
随机调节对比度的代码如下:
改变对比度后的图像:  随机调节色度的相关代码:
随机调节色度的相关代码:
改变后的图像:  本项目通过同时改变色度、对比度以及亮度,改变图像的色调:
本项目通过同时改变色度、对比度以及亮度,改变图像的色调:
原始图像与进行变换后的图像对比: 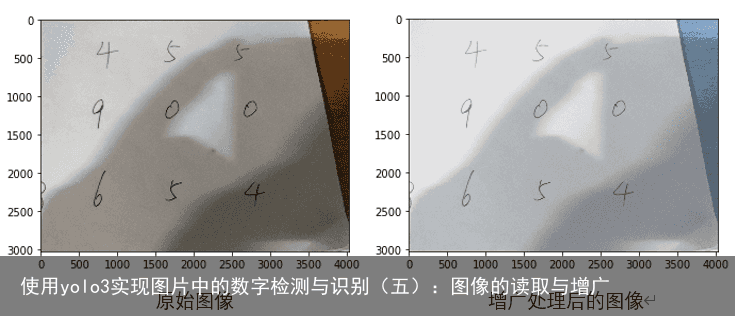 将该过程封装成函数,并包含图像的标注信息:
将该过程封装成函数,并包含图像的标注信息:
通过设置缩放比例的范围,实现随机缩放图像,相关代码如下:
import numpy as np # 产生随机数,作为缩放的比例 xy_scale=np.random.uniform(0.5,1.5) # 缩放 img=cv2.resize(img,None,fx=xy_scale, fy=xy_scale) plt.imshow(img)将上述过程封装成函数,在函数中,不仅图像被缩放,图像中目标的位置信息也随之变动:
def rand_scale(img,obj_class,obj_location): # 产生两个随机数,作为缩放的比例 xy_scale=np.random.uniform(0.5,1.5) # 缩放 img=cv2.resize(img,None,fx=xy_scale, fy=xy_scale) obj_location=np.int32(obj_location*xy_scale) return img,obj_class,obj_location 3.随机裁剪图像通过随机裁剪可以改变目标在图像中的位置以及占比,因此裁剪操作能够实现数据集的增广。通过随机设置裁切区域的起点(左上角),可以实现随机裁剪的过程。相关代码如下:
# 获取图像的尺寸 w=img.shape[0] h=img.shape[1] # 在图像中随机确定一个点作为裁剪区域的起点(左上角) x1_cut=np.random.randint(0,2*w/3) y1_cut=np.random.randint(0,2*h/3) # 设定裁剪区域长宽比例 ratio_cut=0.3 # 确定裁剪区域的宽和高 w_cut=int(w*ratio_cut) h_cut=int(h*ratio_cut) # 确定裁剪区域 x2_cut=min(x1_cut+w_cut,w) y2_cut=min(x2_cut+h_cut,h) img_cut=img[x1_cut:x2_cut,y1_cut:y2_cut] plt.imshow(img_cut)裁剪后的图像如图:  将上述过程封装成函数,其中包含图像裁剪后标注信息的改变:
将上述过程封装成函数,其中包含图像裁剪后标注信息的改变:
本文介绍了数据集的读取以及数据集的增广,增广后的数据集能够有效减少模型过拟合的现象,对于模型的训练性能有很大的提升。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:使用yolo3实现图片中的数字检测与识别(五):图像的读取与增广 https://www.yhzz.com.cn/a/12195.html