【深度学习】解析深度学习的集成方法

神经网络具有很高的方差,不易复现出结果,而且模型的结果对初始化参数异常敏感。 使用集成模型可以有效降低神经网络的高方差(variance)。 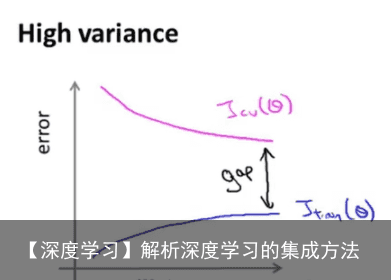
这是典型的高方差,中间的黑线部分就是高方差部分。 解决方法:(1)获取更多的训练实例,增加training set size就会发现两个函数无限的接近。(2)、尝试减少特征的数量。(3)尝试增加正则化程度。
2 使用集成模型降低方差训练多个模型,并将预测结果结合到一起,能够降低方差。 多模型集成能起到作用的前提是,每个模型有自己的特点,每个模型预测出的误差是不同的。 简单的集成方式就是将预测结果取平均,该方法起作用的原因是,不同的模型通常不会在测试集上产生相同的错误。 结合多个模型使得最终的预测结果添加了一个偏差(bias),而这个偏差又会与神经网络的方差(variance)相抵消,使得模型的预测对训练数据的细节、训练方案的选择和单次训练运行的偶然性不太敏感。 集成模型的结果会比任意单模型的结果都要好。
3 如何集成神经网络模型The oldest and still most commonly used ensembling approach for neural networks is called a “committee of networks.” 通常选择多模型的方式:多个相同配置的神经网络 + 相同的训练数据集 + 不同的参数随机初始化 集成的模型数量通常比较小,原因如下: 考虑计算复杂度。 当模型数目达到一定程度,随着数目的增加,集成模型得到的性能回报变小。 集成模型一般考虑如下三种构造方式: Trainning Data: 不同单模型使用不同的训练数据 Ensemble Models: 选择不同的单模型 Combinations: 选择不同的组合方式
3.1 Varying Training Data
一个比较简单的方法是k折交叉验证,能够得到全体训练集的k个子训练集,用每个子集单独去训练模型。最后将这k个模型做集成。 注意,每个子训练集的大小是(k−1)/k倍的全体训练集,而不是1/k倍的全体训练集。 另一种方法是用重采样(resampling)的方式构建新训练集。 重采样过程意味着每个训练数据集的组成是不同的,可能存在重复的例子,从而允许在数据集上训练的模型对样本的密度具有稍微不同的期望,并具有不同的泛化误差(generalization error)。 这种方法也叫做bootstrap aggregation,简称为bagging,被设计用于未剪枝且具有高方差低偏置(high variance and low bias)的决策树。 与上一个方法等价的采样方式为欠采样,即采样后的训练集不出现重复,且比全体数据集要少。 注意,欠采样得到的新数据未经过正规化(regularization),这样可以使得模型训练的更快(过拟合的更快)。 Other approaches may involve selecting a random subspace of the input space to allocate to each model, such as a subset of the hyper-volume in the input space or a subset of input features.
3.2 Varying Combinations
最简单的组合方式是选择所有的模型,将预测结果区平均。 稍微改进的方法是加权取平均,权重由验证集提供。这种方法有时也称为model blending。 设计一个新的模型,能够自动化学习到“加权取平均”过程中,每个单模型所占的权重大小。 这种学习新模型的方式,一般被称为model stacking, 或 stacked generalization。 model stacking是在第二层特征空间中进行学习的。 采用更加复杂的stacking方式,例如boosting(一次添加一个模型以纠正先前模型的错误)。 另一个结合方式是,先将具有相同结构的多个模型的权重取平均,以得到该模型结构的“最好成绩模型”。之后再对不同模型结构的“最好成绩模型”进行集成。
3.3 总结
以上内容,是我阅读这篇文章得到的总结,感兴趣的读者可以继续阅读原文,原文覆盖了更多的知识点,并提供了许多参考依据,具有权威性。 原文章将深度学习的集成方式总结为如下几点(本人总结了其中大部分方法):
Varying Training Data k-fold Cross-Validation Ensemble Bootstrap Aggregation (bagging) Ensemble Random Training Subset Ensemble Varying Models Multiple Training Run Ensemble Hyperparameter Tuning Ensemble Snapshot Ensemble Horizontal Epochs Ensemble Vertical Representational Ensemble Varying Combinations Model Averaging Ensemble Weighted Average Ensemble Stacked Generalization (stacking) Ensemble Boosting Ensemble Model Weight Averaging Ensemble 4 深入了解模型融合Ensemble(深度+代码)在实际工作中,单模型遇到了瓶颈,一般这个时候提升模型效果,一种是做特征,另外一种就是利用复杂模型;我在一边探索特征,一边了解了些模型融合的知识。发现了kaggle很经典的材料。原文很长,干货太多,本文以KAGGLE ENSEMBLING GUIDE为主线,整理了ensemble的多种方法,尽可能通俗的讲明白ensemble。
4.1 Voting ensembles(投票)
我们常见的投票机制,少数服从多数,针对分类模型。 这里主要解决两个问题,一个是ensemble为什么能降低误差,另一个是融合弱相关的结果效果更好。 1.为什么ensemble会取得更好的效果: 假设我们有10个样本,真实数据都是1:
样本:1111111111此外,我们通过模型A,B,C得到准确度(Accuracy)分别为80%,70%,60%的结果分别为:
A: 1111111100 = 80% accuracy B: 0111011101 = 70% accuracy C: 1000101111 = 60% accuracy通过简单的ensemble (vote:ABC同时对一个样本进行投票,投票数大于等于2的记为1,否则为0),于是得到结果Z为:
Z: 1111111101 = 90% accuracy2.选择弱相关性的融合 同上,10个样本,真实数据都是1。通过模型A,B,C得到准确度分别为80%,80%,70%的结果(单模型效果明显比之前的模型们要好),但是三个模型高度相关。通过majority vote得到结果Z:
样本:1111111111 A: 1111111100 = 80% accuracy B: 1111111100 = 80% accuracy C: 1011111100 = 70% accuracy Z: 1111111100 = 80% accuracy结果并没有提高。反而不如上三个表现较差但是弱相关的模型融合效果好.
这里的相关性使用的是皮尔逊相关性代码:correlations.py 这里介绍的是公平投票 代码:kaggle_vote.py 还可以使用带权重的投票,效果的越好的模型权重越高,比如权重为1/loss 几何权重投票,有些情况下较公平投票效果更好 代码:kaggle_geomean.py
4.2 averaging(平均)
平均法一般是针对回归问题的。字面意思理解就是对结果求平均值。代码:kaggle_avg.py 但是直接对结果求平均值会有度量上的问题,不同的方法预测的结果,融合的时候波动较小的起的作用就比较小,为了解决这个问题,提出了Rank Averaging,先将回归的值进行排序,在利用均匀分布打分。代码:kaggle_rankavg.py 一个小栗子: 模型1:
Id,Prediction 1,0.35000056 2,0.35000002 3,0.35000098 4,0.35000111 模型2:
Id,Prediction 1,0.57 2,0.04 3,0.99 4,0.96 模型1和模型2直接averaging融合的话,模型1几乎对模型2没有影响,就是我们刚才说的波动较小的模型在融合过程中起的作用较小的问题。 我们采用Rank Averaging这种方式,则有:
先将结果排序:
模型1: Id,Rank,Prediction 1,1,0.35000056 2,0,0.35000002 3,2,0.35000098 4,3,0.35000111 模型2: Id,Rank,Prediction 1,1,0.57 2,0,0.04 3,3,0.99 4,2,0.96 对排序结果进行归一化:
模型1: Id,Prediction 1,0.33 2,0.0 3,0.66 4,1.0 模型2: Id,Prediction 1,0.33 2,0.0 3,1.0 4,0.66 再对归一化后的排序结果融合打分:
Id,Prediction 1,0.33 2,0.0 3,0.83 4,0.83
5 集成学习的投票机制(Voting mechanism about ensemble learning)硬投票 如何训练多数规则分类器(硬投票):
#训练多数规则分类器: from sklearn import datasets from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier iris = datasets.load_iris() X,y = iris.data[:,1:3],iris.target clf1 = LogisticRegression(solver=lbfgs,multi_class=multinomial,random_state=1) # solver:逻辑回归损失函数的优化方法,拟牛顿法的一种。利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。 clf2 = RandomForestClassifier(n_estimators=50,random_state=1) clf3 = GaussianNB() eclf = VotingClassifier(estimators=[(lr,clf1),(rf,clf2),(gnb,clf3)],voting=hard) for clf,label in zip([clf1,clf2,clf3,eclf],[Logistic Regression,Random Forest,Naive Bayes,Ensemble]): scores = cross_val_score(clf,X,y,cv=5,scoring=accuracy) print(“Accuracy:均值:%0.2f,标准差:%0.2f [%s]” %(scores.mean(),scores.std(),label))软投票 下边的示例程序说明了当软投票分类器(soft VotingClassifier)是基于线性支持向量机(linear SVM)、决策树(Decision Tree)、K 近邻(K-nearest)分类器时,决策域可能的变化情况:
from sklearn import datasets import numpy as np from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from itertools import product from sklearn.ensemble import VotingClassifier import matplotlib.pyplot as plt iris = datasets.load_iris() X,y = iris.data[:,[0,2]],iris.target #???data[:,[0,2]] #Training clf1 = DecisionTreeClassifier(max_depth=4) clf2 = KNeighborsClassifier(n_neighbors=7) clf3 = SVC(gamma=scale,kernel=rbf,probability=True) #gamma:核函数系数 # kernel:算法中采用的核函数类型,‘rbf’:径像核函数/高斯核 # probability:是否启用概率估计 eclf = VotingClassifier(estimators=[(dt,clf1),(knn,clf2),(svc,clf3)], voting=soft,weights=[2,1,2]) clf1 = clf1.fit(X,y) clf2 = clf2.fit(X,y) clf3 = clf3.fit(X,y) eclf = eclf.fit(X,y) # Plotting decision regions x_min,x_max = X[:,0].min() – 1,X[:,0].max() + 1 y_min,y_max = X[:,1].min() – 1,X[:,1].max() + 1 xx,yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1)) # 生成网格点坐标矩阵: # 坐标矩阵——横坐标矩阵XX中的每个元素,与纵坐标矩阵YY中对应位置元素,共同构成一个点的完整坐标。 # 如B点坐标(X12,Y12)=(1,1)(X12,Y12)=(1,1) f, axarr = plt.subplots(2, 2, sharex=col, sharey=row, figsize=(10, 8)) # sharey‘row’ 时,每一行的子图会共享 x 或者 y 轴 for idx,clf,tt in zip(product([0,1],[0,1]), [clf1,clf2,clf3,eclf], [Decison Tree(depth=4),KNN(k=7),Kernel SVM,Soft Voting]): Z = clf.predict(np.c_[xx.ravel(),yy.ravel()]) numpy中的ravel()、flatten()、squeeze()都有将多维数组转换为一维数组的功能,区别: ravel():如果没有必要,不会产生源数据的副本 flatten():返回源数据的副本 squeeze():只能对维数为1的维度降维 另外,reshape(-1)也可以“拉平”多维数组 np.r_ 是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等,类似于 pandas 中的 concat()。 np.c_ 是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。 Z = Z.reshape(xx.shape) axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4) # contourf绘制等高线的,contour和contourf都是画三维等高线图的,不同点在于contour() 是绘制轮廓线,contourf()会填充轮廓 axarr[idx[0], idx[1]].scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor=k) axarr[idx[0], idx[1]].set_title(tt) plt.show()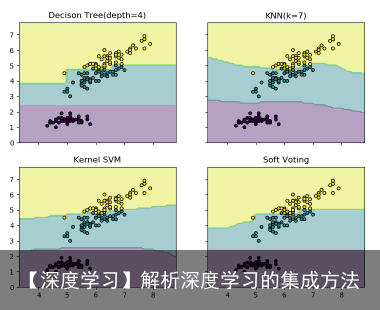
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】解析深度学习的集成方法 https://www.yhzz.com.cn/a/12185.html