【深度学习】如何将Voting和Stacking等应用到神经网络模型

深度神经网络模型复杂的解空间中存在非常多的局部最优解
经典的SGD方法只能让网络模型收敛到其中一个局部最优解
snapshot ensemble 通过循环调整网络学习率(cyclic learning rate schedule)使网络依次收敛到不同的局部最优解
将网络学习率 ηη 设置为随模型迭代轮数tt改变的函数  η0η0: 初始学习率,一般设为0.1,0.2 t: 模型迭代轮数,mini-batch 批处理训练次数
η0η0: 初始学习率,一般设为0.1,0.2 t: 模型迭代轮数,mini-batch 批处理训练次数
T:模型总的批处理训练次数
M:学习率 循环退火(cyclic annealing) 次数,对应模型将收敛的局部最优解个数
利用cos函数的循环性来循环更新网络学习率 当经过“循环余弦退火”对学习率的调整后,每个循环结束可使模型收敛到一个不同的局部最优解 每个循环结束后保存的模型,称之为模型快照
一般挑选最后m个模型“快照”用于集成
2 多模型集成四种最常用的多模型集成方法
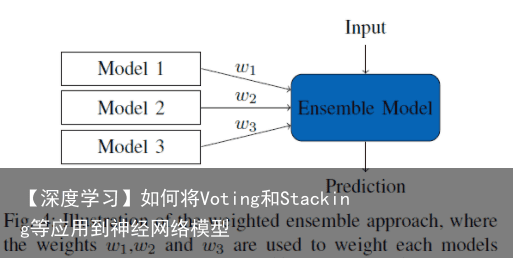
假设共有N个模型待集成,对某测试样本x,其预测结果为N个C维向量,(C为数据的标记空间大小):s1,s2,⋯,sN 直接平均 直接平均不同模型产生的类别置信度得到最后预测结果
 加权平均 在直接平均法基础上加入权重
加权平均 在直接平均法基础上加入权重
调整不同模型输出的重要程度
 wi作为第i个模型的权重,需满足:
wi作为第i个模型的权重,需满足:

高准确率的模型权重较高,低准确率模型可设置稍小权重
3 投票多数表决法(majority voting)
将各自模型返回的预测置信度 sisi 转化为预测类
若某预测类别获得一半以上模型投票,则该样本预测结果为该类别;
若对该样本无任何类别获得一半以上投票,则拒绝作出预测(称为”rejection option”)
相对多数表决法(plurality voting)
选择投票数最高的类别作为最后预测
一定会返回某个类别
4 Stacking:集成学习策略图解这种方法的思想比较简单,在不知道它之前,我们可能在设计算法的时候就会想到这种结构了,下面是我对这个算法的理解: 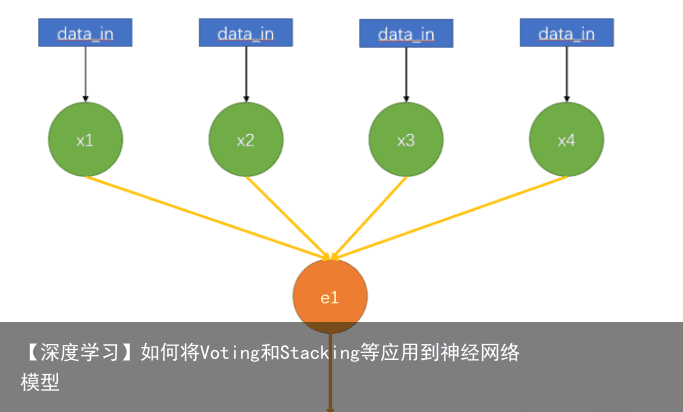 这个结构我们都很熟悉,十分像神经网络中上层神经元到它的一个下层神经元的结构。如果按这种方法,x1-x4是上层的权重,e1是这个神经元的激活函数,并输出神经元的值。不同的是,对于每个x1-x4,输入都是一样的,我们姑且称为data_in 而对于集成学习来说,我们只需要把关键的x1 – x4 以及 e1 换成模型就好了。换句话说,最终整个模型的流程如下:
这个结构我们都很熟悉,十分像神经网络中上层神经元到它的一个下层神经元的结构。如果按这种方法,x1-x4是上层的权重,e1是这个神经元的激活函数,并输出神经元的值。不同的是,对于每个x1-x4,输入都是一样的,我们姑且称为data_in 而对于集成学习来说,我们只需要把关键的x1 – x4 以及 e1 换成模型就好了。换句话说,最终整个模型的流程如下:
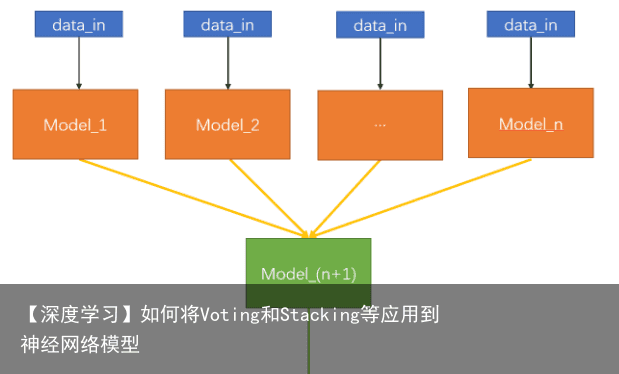
,即将所有数据使用n个模型进行预测,再将预测的结果取平均值,作为特征值输入给第n+1个模型,最终的输出由Model(n+1)决定。
首先我们需要知道机器学习中 K-Fold 的训练过程是怎样的,即把一个数据集分为K份,再将每一份作为测试集,其余作为训练集,训练K次,最终的结果的准确度或取值是这K次结果的均值,一张图表达:
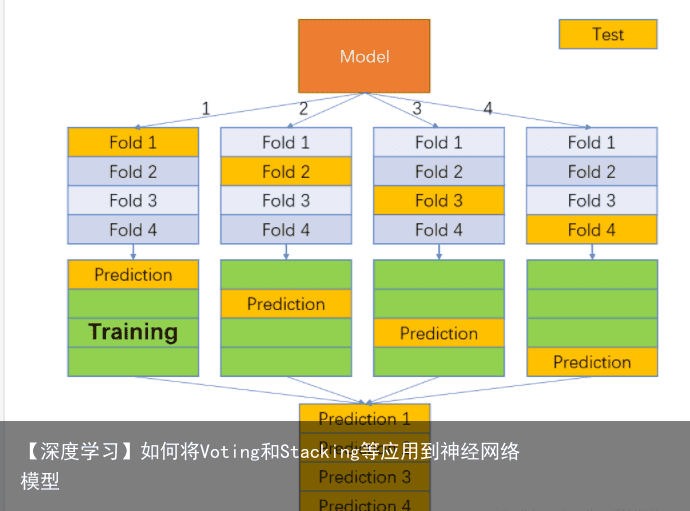
而在Stacking中,每个model都会做一个K-Fold预测,那么Stacking的训练过程也就变为了: 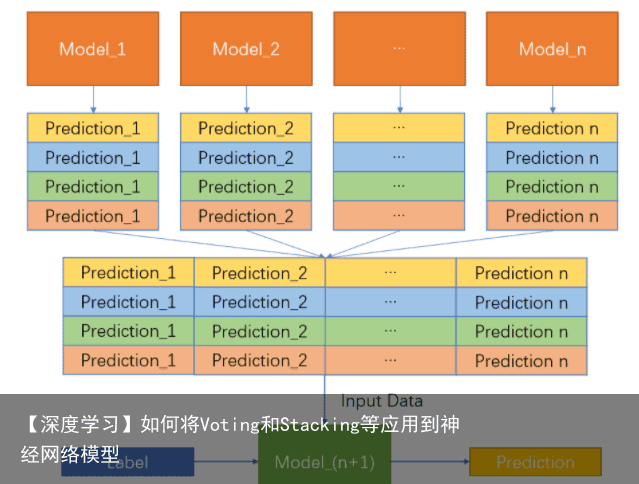
通过平均来集成的softmax概率。
增加RGB图像同深度信息是一种众所周知的方法,来有效地提升物体识别模型的准确率。 另外一种提升视觉识别模型表现的方法是集成学习(ensemble learning)。 Depth数据中包含了关于物体形状的几何信息;RGB中包含了纹理、颜色和表观信息。 此外,Depth数据对光照和颜色不敏感,具有更强的鲁棒性。 作者发现一个已经存在的多模态RGB-D物体识别模型能有效的提升识别表现,通过集成两个普通(通用)模型和一个专家(特定)模型,在Washington RGB-D Object Dataset上进行评估。 Unweighted Averaging: CNNs标准的集成方法是未加权的平均。每个模型的softmax概率进行平均,来得到最后的预测结果。
2)Weighted Averaging: 加权平均的方法和未加权的方法类似,不同点在于每个独立的模型拥有自己的权重。
 权值的确定: 网格搜索(grid search)寻找所有可能的值,所有独立的候选模型在验证集上表现来确定最后的权重大小,权值的和(sum)为1。(距离加权)
权值的确定: 网格搜索(grid search)寻找所有可能的值,所有独立的候选模型在验证集上表现来确定最后的权重大小,权值的和(sum)为1。(距离加权)
3)Majority Voting: 多数表决能够被使用当集成的模型>2时。每个独立的模型给出预测的label,得票数最多的为最后的预测结果,majority voting 更依赖于所有模型的top-1准确率。
3.实验结果: 本文采用了两种集成策略A和B,在这三个模型中,对每个模型的输出概率使用加权平均来得到最优的结果。 1) Ensemble A: 由两个模型组成,权重分别为0.57和0.43。 2) Ensemble B: 由三个模型组成,权重分别为0.17,0.13和0.7,效果优于A的方法。 采用集成学习(ensemble learning)的方法来提升RGB-D物体识别的准确率,加权平均(Weighted Averaging)的方法带来提升较为明显,权值确定使用网格搜索(grid search)。
6 Softmax:将输出转换为概率Softmax如何把CNN的输出转变成概率?
如果你稍微了解一点深度学习的知识或者看过深度学习的在线课程,你就一定知道最基础的多分类问题。当中,老师一定会告诉你在全连接层后面应该加上 Softmax 函数,如果正常情况下(不正常情况指的是类别超级多的时候)用交叉熵函数作为损失函数,你就一定可以得到一个让你基本满意的结果。而且,现在很多开源的深度学习框架,直接就把各种损失函数写好了(甚至在 Pytorch中 CrossEntropyLoss 已经把 Softmax函数集合进去了),你根本不用操心怎么去实现他们,但是你真的理解为什么要这么做吗?这篇小文就将告诉你:Softmax 是如何把 CNN 的输出转变成概率, Softmax 函数接收一个 这N维向量作为输入,然后把每一维的值转换成(0,1)之间的一个实数,它的公式如下面所示:
 正如它的名字一样,Softmax 函数是一个“软”的最大值函数,它不是直接取输出的最大值那一类作为分类结果,同时也会考虑到其它相对来说较小的一类的输出。
正如它的名字一样,Softmax 函数是一个“软”的最大值函数,它不是直接取输出的最大值那一类作为分类结果,同时也会考虑到其它相对来说较小的一类的输出。
说白了,Softmax 可以将全连接层的输出映射成一个概率的分布,我们训练的目标就是让属于第k类的样本经过 Softmax 以后,第 k 类的概率越大越好。这就使得分类问题能更好的用统计学方法去解释了。
使用 Python,我们可以这么去实现 Softmax 函数:
 同样使用 Python,改进以后的 Softmax 函数可以这样写:
同样使用 Python,改进以后的 Softmax 函数可以这样写:

免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】如何将Voting和Stacking等应用到神经网络模型 https://www.yhzz.com.cn/a/12183.html