【深度学习】图像输入网络必要的处理流程

灰度转化 目的:将三通道图像(彩色图)转化为单通道图像(灰度图) 公式: 3–>1: GRAY = B 0.114 + G 0.587 + R * 0.299 1–>3: R = G = B = GRAY; A = 0 函数:cv2.cvtColor(img,flag) 参数说明:参数1:待转化图像; 参数2:flag就是转换模式,cv2.COLOR_BGR2GRAY:彩 色转灰度cv2.COLOR_GRAY2BGR:单通道转三通道 Python代码实现
#导入opencv import cv2 #读入原始图像,使用cv2.IMREAD_UNCHANGED img = cv2.imread(“girl.jpg”,cv2.IMREAD_UNCHANGED)# 读入要处理的图片,参数1为图片路径 #查看打印图像的shape shape = img.shape print(shape) #判断通道数是否为3通道或4通道 if shape[2] == 3 or shape[2] == 4 : #将彩色图转化为单通道图 img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) cv2.imshow(“gray_image”,img_gray) cv2.imshow(“image”, img) cv2.waitKey(0) cv2.destroyAllWindows()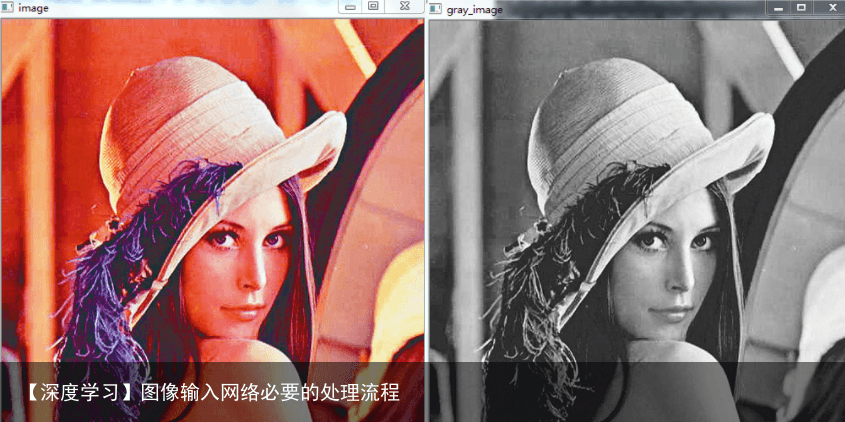
归一化就是通过一系列变换(即利用图像的不变矩寻找一组参数使其能够消除其他变换函数对图像变换的影响),将待处理的原始图像转换成相应的唯一标准形式(该标准形式图像对平移、旋转、缩放等仿射变换具有不变特性)。
基于矩的图像归一化技术基本工作原理为:首先利用图像中对仿射变换具有不变性的矩来确定变换函数的参数, 然后利用此参数确定的变换函数把原始图像变换为一个标准形式的图像(该图像与仿射变换无关)。 一般说来,基于矩的图像归一化过程包括4个步骤,即坐标中心化、x-shearing 归一化、缩放归一化和旋转归一化。
图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的。 二:为何要进行归一化
1.基本上归一化思想是利用图像的不变矩寻找一组参数使其能够消除其他变换函数对图像变换的影响。也就是转换成唯一的标准形式以抵抗仿射变换。图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的。
Matlab中的图像数据有时候必须是浮点型才能处理,而图像数据本身是0-255的UNIT型数据所以需要归一化,转换到0-1之间。 3.归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。目的是为了:
(1)避免具有不同物理意义和量纲的输入变量不能平等使用
(2)bp中常采用sigmoid函数作为转移函数,归一化能够防止净输入绝对值过大引起的神经元输出饱和现象
(3)保证输出数据中数值小的不被吞食
3.神经网络中归一化的原因:
归一化是为了加快训练网络的收敛性,可以不进行归一化处理;
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1–+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布;当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。
但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。 三:归一化的作用
1、转换成标准模式,防止仿射变换的影响。 2、减小几何变换的影响。 3、加快梯度下降求最优解的速度。四:归一化的实现
%% 图像归一化 clc clear close all image = imread(E:\裂纹\a\3\53.bmp); image = rgb2gray(image); figure imshow(image); image = double(image); image_minGray = min(min(image)); image_maxGray = max(max(image)); image_distance = image_maxGray-image_minGray; min_Gray = 0; max_Gray = 255; image_normalization = (image-image_minGray)/image_distance; %归一化,图像的灰度值限制到(0~1)之间 figure imshow(image_normalization) image_255 = max_Gray*image_normalization +min_Gray; figure imshow(uint8(image_255)) %% 方法二直接调用matlab函数mat2gray image_norm = mat2gray(image); figure imshow(image_norm)CLAHE 是一种非常经典的直方图均衡化算法,英文全称是 Contrast Limited Adaptive Histogram Equalization,该算法源于1994年发表的论文。

如今几乎所有的图像处理软件,包括OpenCV,ImageJ,Matlab 等都支持CLAHE算法。在Matlab 中提供的命令是adapthisteq。
CLAHE算法的主要作用在于增强图像的对比度同时能够抑制噪声,典型的效果如下图所示。 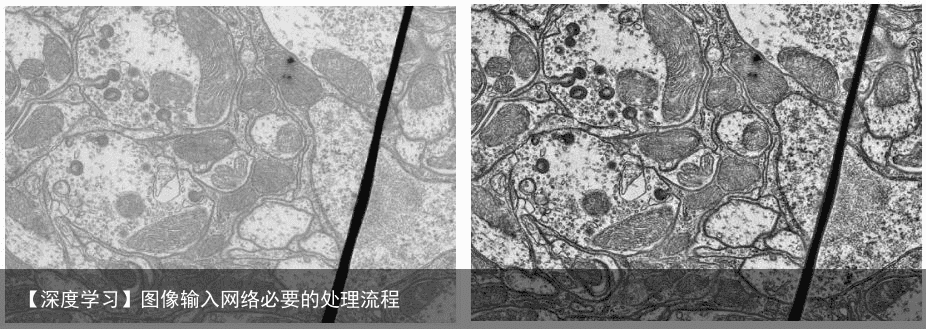 直方图 Histogram 如果你想准确地知道到底什么是直方图,百度上搜到的资料基本都是垃圾。下面是英文网站给出的直方图定义。
直方图 Histogram 如果你想准确地知道到底什么是直方图,百度上搜到的资料基本都是垃圾。下面是英文网站给出的直方图定义。
A histogram is a type of graph that has wide applications in statistics. Histograms provide a visual interpretation of numerical data by indicating the number of data points that lie within a range of values. These ranges of values are called classes or bins. The frequency of the data that falls in each class is depicted by the use of a bar.
翻译过来就是,直方图是统计学中广泛使用的一类图表,它以可视化的形式呈现统计数据,能够显示有多少数据点落在给定的数值区间内。这些数值区间称为门类(class)或桶(bin 或 bucket),取其盛纳数据的意义。每个门类对应的数据频数(frequency)用一定高度的矩形指示。
 在分析图像数据的统计特性时,有时可以抛弃图像的色度分量,只考察图像的亮度分量,此时可以引入图像的亮度直方图(Luminance Histogram),以常用的8位精度图像为例,直方图的X轴为0~255,共256个桶,每个桶刚好覆盖1个像素值,直方图的Y轴表示每个桶盛纳了多少个像素。所有桶中盛纳的像素数加到一起应等于图像的总像素数。
在分析图像数据的统计特性时,有时可以抛弃图像的色度分量,只考察图像的亮度分量,此时可以引入图像的亮度直方图(Luminance Histogram),以常用的8位精度图像为例,直方图的X轴为0~255,共256个桶,每个桶刚好覆盖1个像素值,直方图的Y轴表示每个桶盛纳了多少个像素。所有桶中盛纳的像素数加到一起应等于图像的总像素数。
在分析画面的亮暗特征,人们经常把亮度区间定性地划分成暗调、阴影、中调、亮调、高光等几个区域,各区域的边界则可以根据应用特点灵活掌握。 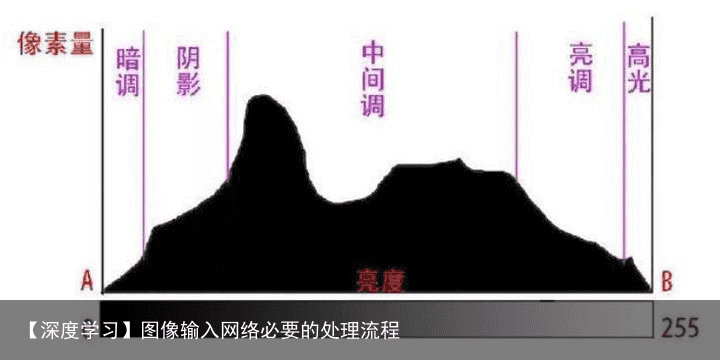 当需要分析图像的颜色特性时,可以引入通道直方图(Channel Histogram),分别对R/G/B三个颜色通道进行直方图统计。
当需要分析图像的颜色特性时,可以引入通道直方图(Channel Histogram),分别对R/G/B三个颜色通道进行直方图统计。 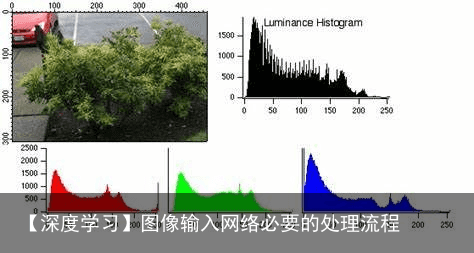 对比度 Contrast 图像对比度指的是一幅图像中最亮的白和最暗的黑之间灰度反差的大小。差异越大代表对比越大,否则对比越小。一种常用的定量度量方法是Michelson对比度,定义为 当一幅图像最白和最黑像素灰度都是128时,图像对比度最低,C=0。
对比度 Contrast 图像对比度指的是一幅图像中最亮的白和最暗的黑之间灰度反差的大小。差异越大代表对比越大,否则对比越小。一种常用的定量度量方法是Michelson对比度,定义为 当一幅图像最白和最黑像素灰度都是128时,图像对比度最低,C=0。
当一幅图像最白像素灰度=255,最黑像素灰度=0时,图像对比度最高,C=1.0。
当一幅图像最白和最黑像素灰度都在128附近浮动时,图像的直方图集中在中间的几个桶,图像看起来灰蒙蒙的,英语中使用dull描述这种效果。相反,如果图像中黑白像素的跨度较大,则图像富有通透感,英语中使用clarity描述这种效果。  下面一组图显示了直方图均衡改善图像对比度的效果。
下面一组图显示了直方图均衡改善图像对比度的效果。 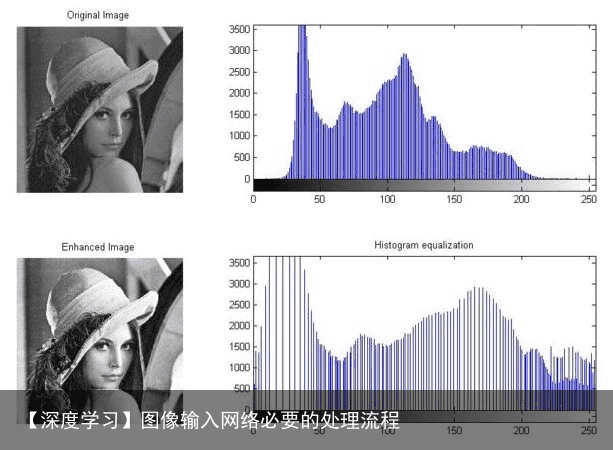
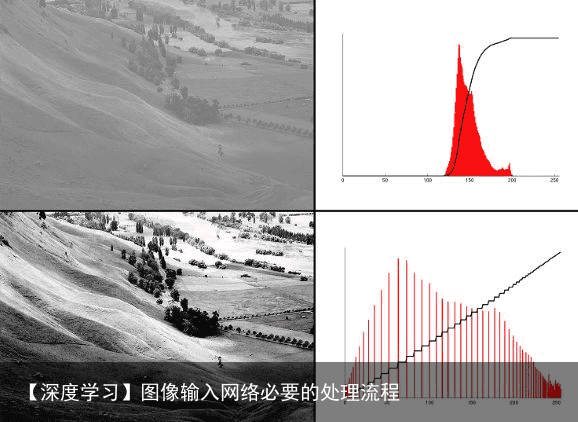 自适应直方图均衡 Adaptive Histogram Equalization(AHE) 参考人类视觉的局部性原理,人们提出了自适应直方图均衡算法(AHE),基本思想是将图像分成若干个区域(tile),比如8×8=64个tile,直方图均衡的基本单位不再是整个图像,而是对每个小区域做直方图均衡。AHE 更适合于用来改善图像的局部对比度,以及增强图像边缘信息,但是并没有解决直方图均衡会放大图像噪声的问题。
自适应直方图均衡 Adaptive Histogram Equalization(AHE) 参考人类视觉的局部性原理,人们提出了自适应直方图均衡算法(AHE),基本思想是将图像分成若干个区域(tile),比如8×8=64个tile,直方图均衡的基本单位不再是整个图像,而是对每个小区域做直方图均衡。AHE 更适合于用来改善图像的局部对比度,以及增强图像边缘信息,但是并没有解决直方图均衡会放大图像噪声的问题。
限制对比度自适应直方图均衡 CLAHE 
http://blog.csdn.net/lichengyu/article/details/20840135
本质上是关于灰度的一个幂函数,当系数gamma大于1时,低灰度值的动态范围减小,高灰度值的动态范围增大,整体的灰度值减小;gamma小于1时则相反;
人眼是遵循gamma小于1曲线对输入图像进行处理,其他方面更多应用于渲染,此处不做描述!
(Gamma Correction,伽玛校正):所谓伽玛校正就是对图像的伽玛曲线进行编辑,以对图像进行非线性色调编辑的方法,检出图像信号中的深色部分和浅色部分,并使两者比例增大,从而提高图像对比度效果。计算机绘图领域惯以此屏幕输出电压与对应亮度的转换关系曲线,称为伽玛曲线(Gamma Curve)。
以传统CRT(Cathode Ray Tube)屏幕的特性而言,该曲线通常是一个乘幂函数,Y=(X+e)γ,其中,Y为亮度、X为输出电压、e为补偿系数、乘幂值(γ)为伽玛值,改变乘幂 值(γ)的大小,就能改变CRT的伽玛曲线。典型的Gamma值是0.45,它会使CRT的影像亮度呈现线性。使用CRT的电视机等显示器屏幕,由于对于 输入信号的发光灰度,不是线性函数,而是指数函数,因此必需校正。 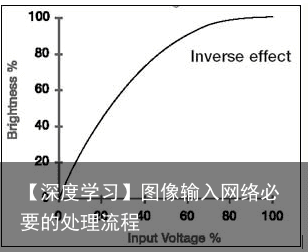
5.1 裁剪(Crop)
image.shape–([3, width, height])一个视频序列中的一帧图片,裁剪前大小不统一 bbox.shape–([4,])人体检测框,用于裁剪 x.shape–([1,13]) 人体13个关键点的所有x坐标值 y.shape–([1,13])人体13个关键点的所有y坐标值
def crop(image, bbox, x, y, length): x, y, bbox = x.astype(np.int), y.astype(np.int), bbox.astype(np.int) x_min, y_min, x_max, y_max = bbox w, h = x_max – x_min, y_max – y_min # Crop image to bbox image = image[y_min:y_min + h, x_min:x_min + w, :] # Crop joints and bbox x -= x_min y -= y_min bbox = np.array([0, 0, x_max – x_min, y_max – y_min]) # Scale to desired size side_length = max(w, h) f_xy = float(length) / float(side_length) image, bbox, x, y = Transformer.scale(image, bbox, x, y, f_xy) # Pad new_w, new_h = image.shape[1], image.shape[0] cropped = np.zeros((length, length, image.shape[2])) dx = length – new_w dy = length – new_h x_min, y_min = int(dx / 2.), int(dy / 2.) x_max, y_max = x_min + new_w, y_min + new_h cropped[y_min:y_max, x_min:x_max, :] = image x += x_min y += y_min x = np.clip(x, x_min, x_max) y = np.clip(y, y_min, y_max) bbox += np.array([x_min, y_min, x_min, y_min]) return cropped, bbox, x.astype(np.int), y.astype(np.int)5.2 缩放(Scale)
image.shape–([3, 256, 256])一个视频序列中的一帧图片,裁剪后输入网络为256*256 bbox.shape–([4,])人体检测框,用于裁剪 x.shape–([1,13]) 人体13个关键点的所有x坐标值 y.shape–([1,13])人体13个关键点的所有y坐标值 f_xy–缩放倍数
def scale(image, bbox, x, y, f_xy): (h, w, _) = image.shape h, w = int(h * f_xy), int(w * f_xy) image = resize(image, (h, w), preserve_range=True, anti_aliasing=True, mode=constant).astype(np.uint8) x = x * f_xy y = y * f_xy bbox = bbox * f_xy x = np.clip(x, 0, w) y = np.clip(y, 0, h) return image, bbox, x, y5.3 翻转(fillip)
这里是将图片围绕对称轴进行左右翻转(因为人体是左右对称的,在关键点检测中有助于防止模型过拟合)
def flip(image, bbox, x, y): image = np.fliplr(image).copy() w = image.shape[1] x_min, y_min, x_max, y_max = bbox bbox = np.array([w – x_max, y_min, w – x_min, y_max]) x = w – x x, y = Transformer.swap_joints(x, y) return image, bbox, x, y5.4 旋转(rotate)
angle–旋转角度
def rotate(image, bbox, x, y, angle): # image – -(256, 256, 3) # bbox – -(4,) # x – -[126 129 124 117 107 99 128 107 108 105 137 155 122 99] # y – -[209 176 136 123 178 225 65 47 46 24 44 64 49 54] # angle – –8.165648811999333 # center of image [128,128] o_x, o_y = (np.array(image.shape[:2][::-1]) – 1) / 2. width,height = image.shape[0],image.shape[1] x1 = x y1 = height – y o_x = o_x o_y = height – o_y image = rotate(image, angle, preserve_range=True).astype(np.uint8) r_x, r_y = o_x, o_y angle_rad = (np.pi * angle) /180.0 x = r_x + np.cos(angle_rad) * (x1 – o_x) – np.sin(angle_rad) * (y1 – o_y) y = r_y + np.sin(angle_rad) * (x1 – o_x) + np.cos(angle_rad) * (y1 – o_y) x = x y = height – y bbox[0] = r_x + np.cos(angle_rad) * (bbox[0] – o_x) + np.sin(angle_rad) * (bbox[1] – o_y) bbox[1] = r_y + -np.sin(angle_rad) * (bbox[0] – o_x) + np.cos(angle_rad) * (bbox[1] – o_y) bbox[2] = r_x + np.cos(angle_rad) * (bbox[2] – o_x) + np.sin(angle_rad) * (bbox[3] – o_y) bbox[3] = r_y + -np.sin(angle_rad) * (bbox[2] – o_x) + np.cos(angle_rad) * (bbox[3] – o_y) return image, bbox, x.astype(np.int), y.astype(np.int)

5.5 图像数据增强之弹性形变(Elastic Distortions)
深度学习的成功的原因主要有两点: 当前计算机的计算能力有很大提升; 随着大数据时代的到来,当前的训练样本数目有很大的提升。 然而深度学习的一大问题是,有的问题并没有大量的训练数据,而由于深度神经网络具有非常强的学习能力,如果没有大量的训练数据,会造成过拟合,训练出的模型难以应用。因此对于一些没有足够样本数量的问题,可以通过已有的样本,对其进行变化,人工增加训练样本。 对于图像而言,常用的增加训练样本的方法主要有对图像进行旋转、移位等仿射变换,也可以使用镜像变换等等,这里介绍一种常用于字符样本上的变换方法,弹性变换算法(Elastic Distortion)。 该算法最先是由Patrice等人在2003年的ICDAR上发表的《Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis》。本文主要是对论文中提出的弹性形变数据增强方法进行解读。
弹性变形的具体理论步骤如下:
step1:对图像imageA进行仿射变换(三点法),得到imageB,关于仿射变换可以看: 马同学;
step2:对imageB图像中的每个像素点随机生成一个在x和y方向的位移,△x和△y。其位移范围在(-1, 1)之间,得到一个随机位移场(random displacement fields);
step3:用服从高斯分布的N(0, δ)对step2中生成的随机位移场进行卷积操作(和CNN中的卷积操作一样,说白了就是滤波操作)。我们知道δ越大,产生的图像越平滑。下图是论文中的不同δ值对随机位移场的影响,下图左上角为原图,右上角为δ较小的情况(可以发现,位移方向非常随机),左下角和右下角为较大的不同δ值。
step4:用一个控制因子α与随机位移场相乘,用以控制其变形强度;
step5:将随机位移场施加到原图上,具体是怎么施加的呢?首先,生成一个和imageB大小一样的meshgrid网格meshB,网格中的每个值就是像素的坐标,比如说meshgrid网格大小为512×512,则meshgrid中的值为(0, 0), (0, 1), …, (511, 0), (511, 511),然后将随机位移场和meshB网格相加,这就模拟了imageB中的每个像素点在经过随机位移场的作用后,被偏移的位置,meshB与随机位移场相加后的结果记做imageC。
step6:弹性变形最终输出的imageC中每个位置的灰度值大小,组成一副变形图像,现在imageC中每个像素点存储的是(x+△x, y+△y),如下图中的A,那怎么转化成灰度值呢,依据论文,作者是根据imageB中的B位置的双线性插值灰度值作为A点的像素灰度值大小,最终将imageC输出得到变形图像。 代码效果(左边为原图,右边为变形图像):

免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】图像输入网络必要的处理流程 https://www.yhzz.com.cn/a/12161.html