【深度学习】论文EMO单眼识别分析
文章目录 1 研究背景 2 所提方法 3 创新点 4 实验结果 5 结论与思考 1 研究背景情绪是一种心理和生理状态,伴随着认知过程。对情绪的研究已经存在了很长时间。近年来,随着人工智能和深度学习的发展,利用人的生理信号参数,如脑电、心电、体温等自动识别情绪已经获得较大进展,而且情感计算这一领域在医疗保健,教育,产品设计等领域具有广泛的潜在应用前景。许多研究表明存在情绪刺激的情况下,眼球运动会发生变化,而且眼动数据的采集比脑电等数据更简单,更方便快捷,研究基于眼动的情绪分类和识别具有巨大的潜在价值。在许多商用眼镜设备上已经可以使用眼动追踪相机。此外,越来越多的眼镜设备将配备眼动相机以提供智能服务。 出于两个主要原因,情感识别应用在眼镜设备上是一项艰巨的任务。首先,眼动追踪相机捕获的是眼睛区域图像而不是整个脸部图像。眼区图像具有更少的与情感相关的面部变化和肌肉运动,从而使情感识别更具挑战性。不同用户之间相同情感的差异可能大于同一用户不同情感的差异。因此,与全脸情感识别的任务不同,“一刀切”的策略不适合眼部情感识别任务。第二个挑战是在资源受限的眼镜设备上进行实时情感识别。
2 所提方法 实现了人机交互,提出并开发了EMO系统,用于单眼图像的实时情感识别,使眼镜设备具有情感识别能力。 为了减小网络的参数量,节省计算资源和训练时间,基于ResNet18设计了一种新颖的CNN架构,被用作眼部图像的特征提取器。 设计了帧采样器和快速转发器,分别利用视频帧之间的时间局部性和特征相似性。帧采样器有选择的将视频帧发送到特征提取器,快速转发器基于Siamese网络,该网络与CNN结构相同,权值共享。从而进一步节省计算资源,加快计算速度,优化连续识别的效率。 设计了基于特征匹配和K-means等算法的个性化分类器,将深度学习技术和传统机器学习结合,在真实的硬件上构建了EMO原型。 EMO系统架构的组成成分为帧采样器、特征提取器、快速转发器和个性化分类器,情感识别的整体工作流程如图2-1所示。 3 创新点
3 创新点
3.1 改进的低层特征提取网络 针对特征提取网络部分,文章首先改进了ResNet18的基本模型,设计了独特的CNN网络,将视频帧的输入大小从常规的224×224像素缩小到64×64像素,以减少计算开销。为了解决舍弃了网络部分Pooling Layer而带来的特征提取性能下降的影响,增加了CNN网络的深度,保留了特征提取能力,而资源的使用率却大大降低。如下图3-1所示,将CNN分为和两个部分,分别为红色框和绿色框部分内容,这样做的目的是为了快速转发器的插入。 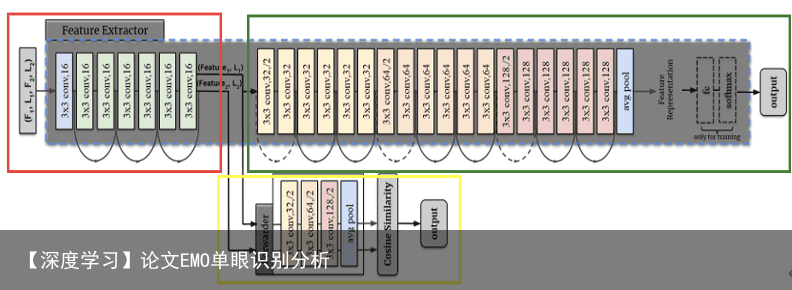
图3-1 特征提取部分的网络结构 第二,文章中设计了CNN前7层的孪生网络(Siamese Network),即图3-1的黄色框部分作为快速转发器。针对连续帧的特征向量很相似的特点,快速转发器决定是否可以在特征提取的早期阶段预测帧的最终分类结果,实时眼动追踪连续视频帧的时间特征。一旦提取到的特征向量满足条件,快速转发器将立即输出情感类别,并绕过CNN的另一部分网络。Siamese Network的结构如表3-1所示,网络的前七层与特征提取器的CNN相同,具有10个卷积层,1个池化层。在一个卷积块中包含4个小卷积块,使用平均池化,其中卷积核大小为3×3,卷积核数量成倍增长。同时,快速转发器的输入是特征提取器中CNN第七层的中间输出。 表3-1 Siamese Network的结构和参数 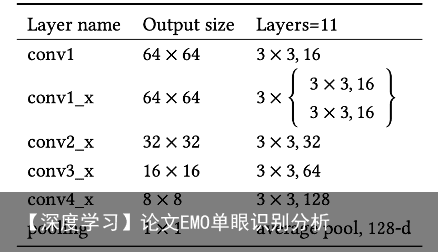
3.2 个性化分类器 现有的个性化分类方案通常为每个用户建立专有的模型,这类方法不仅需要非常高的模型训练成本,而且存在每个用户的训练数据不足的问题。此外,如果预先没有任何用户的带标签数据,模型对新用户的效果并不好,从而导致较大的部署问题。为了解决这些问题,文章采用特征提取与情感分类分开的策略,基于CNN的预测结果,每个用户都有自己的分类器。设计了基于特征匹配的分类器,而不是激活函数为SoftMax的Dense层。当佩戴者第一次使用EMO时,会在初始化过程中构建个性化分类器,而不是进行预训练,节省了大量的计算时间和资源。 3.3 数据集处理 文章在这一部分主要解决了每个用户表达自己的情感方式不同的问题,除了FER2013面部表情识别数据集外,文章中扩充的数据集是由FilmStim中的视频剪辑诱导的志愿者生成的,而不是传统的通过要求志愿者根据示例视频动作来获得的。 3.4 网路训练策略 与标准端对端网络的训练方法不同,文章在训练模型时分两个阶段,首先,采用联合训练的方式保证CNN和快速转发器特征提取的内容一致,第二,在第一阶段的基础上,使用额外的数据集进行模型微调,目的是为了让网络参数进一步适应自己数据集,更好的完成单眼区域情感识别任务。
4 实验结果4.1 对比 文章在这一部分除了与Eyemotion进行对比外,还完成了消融实验,证明个性化分类器有效提高了识别的精度。在表4-1中,是EMO模型和Eyemotion在ACC和F1得分上的对比,EMO的平均识别准确率要高于Eyemotion。 表4-1 EMO和Eyemotion识别的评价结果对比 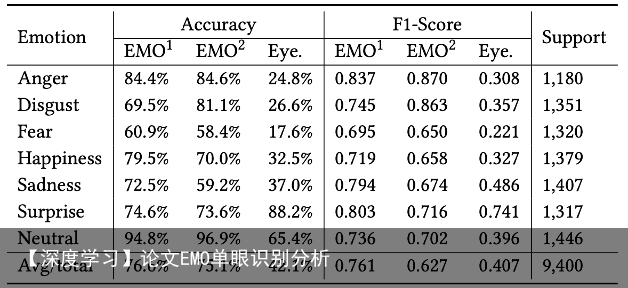
4.2 方法整体评估 在情感识别准确率层次,文章改进ResNet18网络,设计了个性化分类器,在保证高精度的情况下,减小了网络的参数量,节省计算资源和时间。在系统资源使用层次,文章设计了帧采样器和快速转发器,快速转发器基于Siamese网络,利用眼动相机连续视频帧之间的时间局部性和特征相似性来进减少识别等待时间和系统资源的使用。
5 结论与思考5.1 作者结论 文章提出并开发了EMO系统,可以从眼镜设备上的眼动相机捕获单眼图像,从而识别用户的情绪,使用通用特征提取器和个性化分类器来准确识别不同用户之间的七种情绪类型。为了优化连续视频帧的识别效率,使用帧采样器和快速转发器分别利用眼动跟踪视频的时间局部性和特征相似性。EMO在两个硬件平台上实现,能够以12.8fps的平均帧率实现连续的情感识别,平均准确度为72.2%,优于其他方法,并且消耗的系统资源更少。 5.2 我的启发 在网络结构方面,特征转发器选择Siamese网络,充分利用了特征提取任务的一致性,此外,我认为这种轻量级的网络设计是以后要重点研究的方向。该网络设计思路也可以应用在图像分割领域,现在的图像分割处理网络更多以牺牲计算资源和时间为代价换取更高的准确率,在FCN、U-Net等网络的基础上,越来越深、结构更复杂和参数量更大的改进模型不断出现。对于日常生活中的多种视觉任务,也许需要的是更简单准确的网络模型。在数据处理方面,文章充分利用了数据特性,还利用眼动相机的连续视频帧之间的时间局部性和特征相似性来进一步减少识别等待时间和系统资源的使用,我在过去的任务中,重点放在了模型结构上,但是对数据的处理方法也很大程度上决定了模型准确率。文章设计了个性化的特征分类器,将传统机器学习和深度学习技术结合,消耗的系统资源更少。 5.3 未来可以改进的方向 文章采用基于ResNet18网络改进的CNN网络,我认为Swin Transformer也许是CNN的完美替代方案,Swin Transformer的计算复杂度较低,具有输入图像线性大小计算复杂度。并且利用该网络每个stage中都是类似重复单元的特性,同样可以将Swin Transformer网络分为两个阶段,在第一阶段与Siamese网络联合训练,对于单眼情绪识别任务来说,效果会更好。 文章模型训练部分使用了交叉熵损失函数,可以改进为Lovasz-Softmax Loss(LSL),在多类别语义分割任务中,我使用过该函数,也许同样适用于情绪识别任务,模型训练的收敛速度和识别的精度会有一定提升。 文章提取FER2013数据的眼部作为网络训练集之一,我认为在数据集处理的过程中,是否可以考虑同时裁剪双眼图像,将双眼特征进行向量拼接后再输入到模型训练,这对眼部情绪的准确判断可能也有一定的帮助。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】论文EMO单眼识别分析 https://www.yhzz.com.cn/a/12141.html