
【深度学习】用CNN的结构打败CNN(深入浅出transformer)
文章目录 1 transformer的基本结构 2 模块1:Positional Embedding 3 模块2:Multi-Head Attention 4 模块3:ADD 5 Transfomer总结 7 配置、使用transformers包 1 transformer的基本结构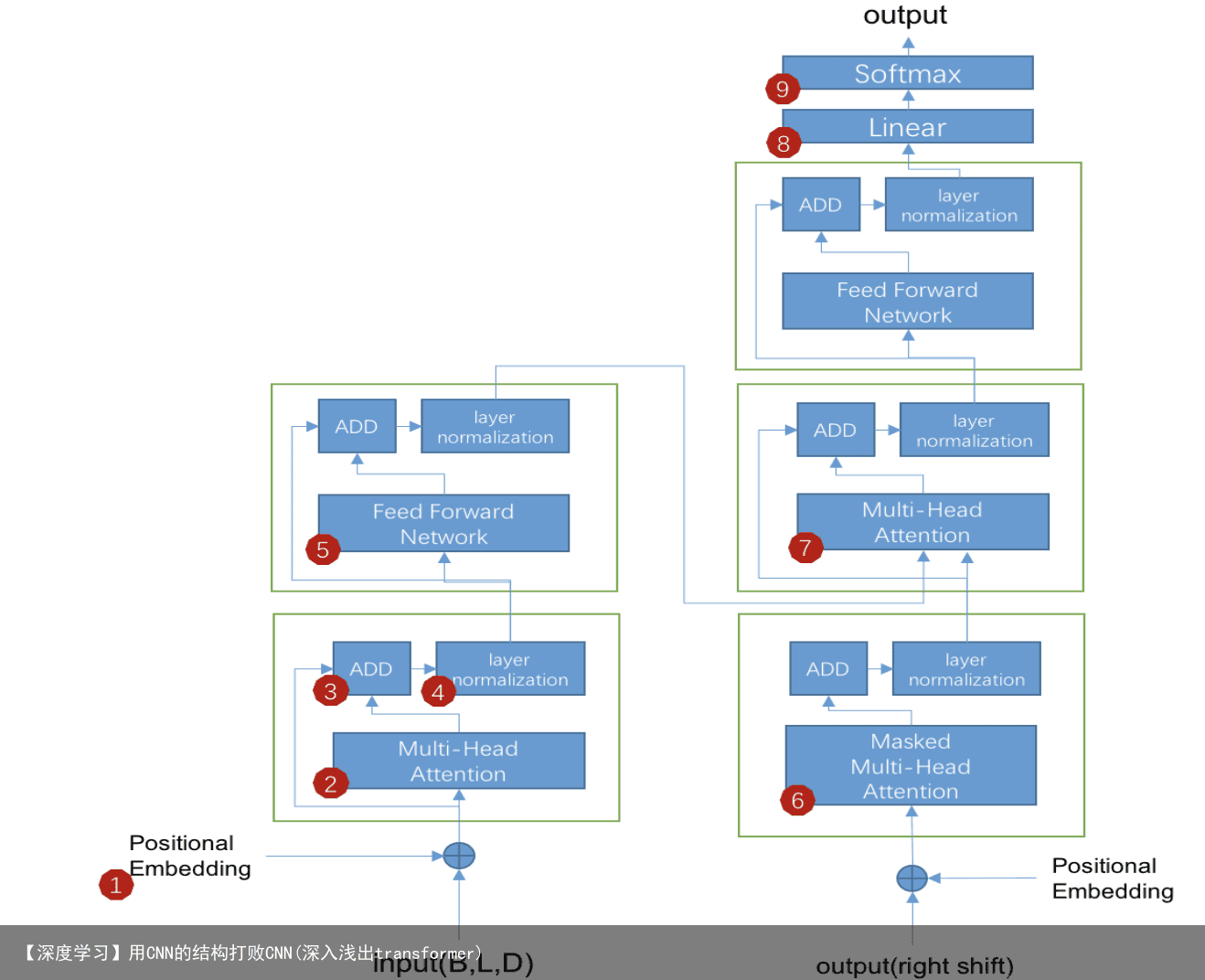
P E PEPE模块的主要做用是把位置信息加入到输入向量中,使模型知道每个字的位置信息。对于每个位置的P E PEPE是固定的,不会因为输入的句子不同而不同,且每个位置的P E PEPE大小为1 ∗ n 1 *n1∗n(n为word embedding 的dim size),transformer中使用正余弦波来计算P E PEPE,具体如下: 
这个模块是transformer的核心,我们把这块拆成两部分来理解,先讲下其中的Scaled Dot-Product Attention(缩放的点积注意力机制),再讲Multi-Head。
Scaled Dot-Product Attention 我们先看下论文中的 Scaled Dot-Product Attention 步骤,如下图: 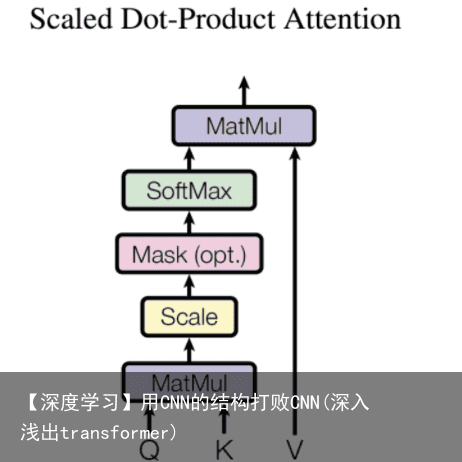 Multi-Head
Multi-Head 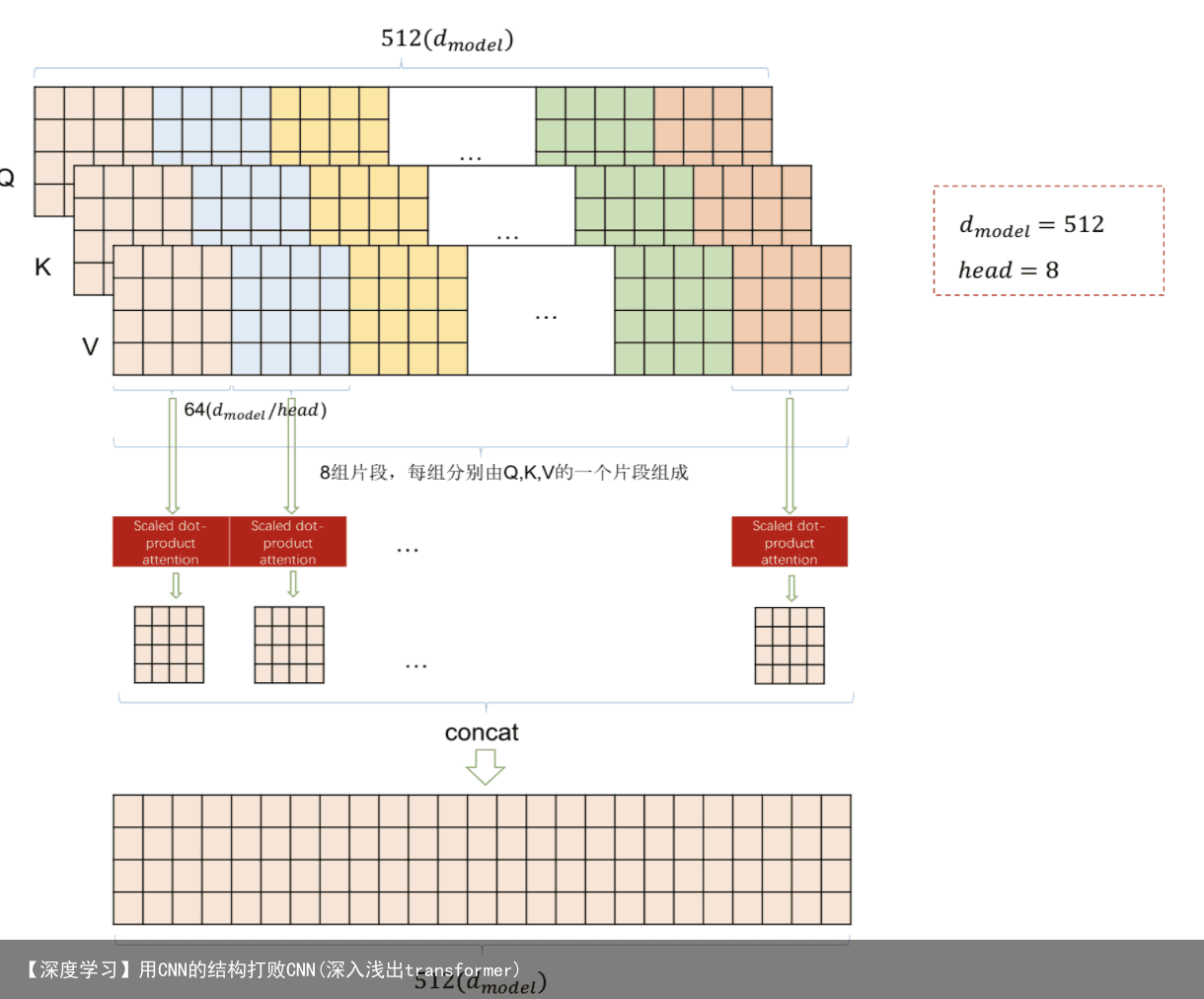
此模块做了个类似残差的操作,不同的是不是用输入减去输出,而是用输入加上输出。(指Multi-Head Attention模块的输入和输出),具体操作就是把模块2的输入矩阵与模块2的输入矩阵的对应位置做加法运算。

正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中刷新了BLEU值。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力; 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长的依赖关系,LSTM依旧无能为力。 Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
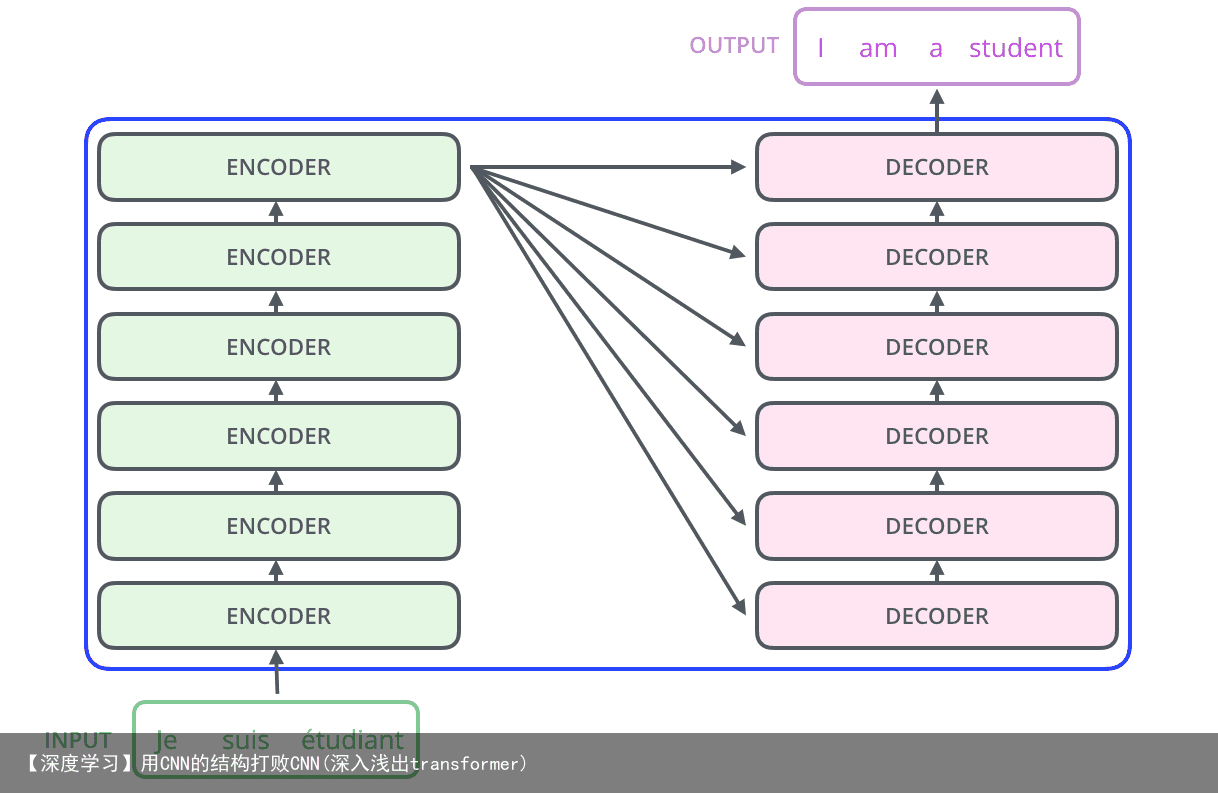 Transformer的Encoder和Decoder均由6个block堆叠而成
Transformer的Encoder和Decoder均由6个block堆叠而成
Encoder的结构如下图所示 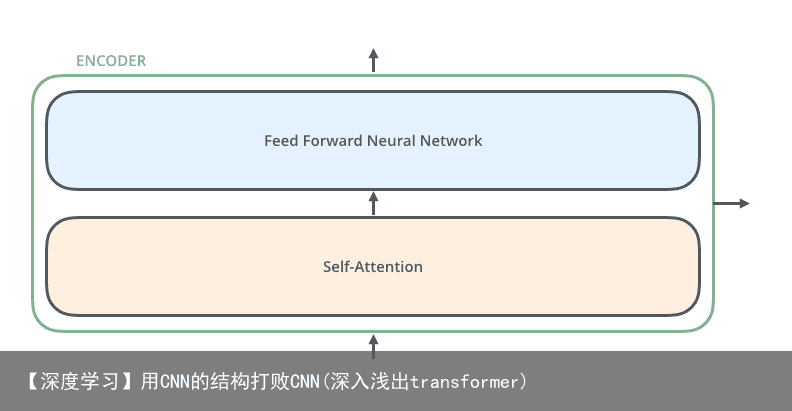 Transformer的编码器由self-attention和Feed Forward neural network组成
Transformer的编码器由self-attention和Feed Forward neural network组成
Decoder的结构如图所示,它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值
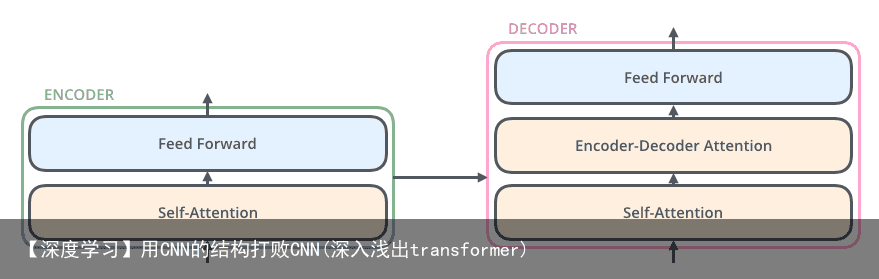 Transformer的解码器由self-attention,encoder-decoder attention以及FFNN组成 Self-Attention:当前翻译和已经翻译的前文之间的关系; Encoder-Decoder Attention:当前翻译和编码的特征向量之间的关系。
Transformer的解码器由self-attention,encoder-decoder attention以及FFNN组成 Self-Attention:当前翻译和已经翻译的前文之间的关系; Encoder-Decoder Attention:当前翻译和编码的特征向量之间的关系。
一、transformers transformers包又名pytorch-transformers或者pytorch-pretrained-bert。它提供了一些列的STOA模型的实现,包括(Bert、XLNet、RoBERTa等)。下面介绍该包的使用方法:
1、如何安装 transformers的安装十分简单,通过pip命令即可
pip install transformers 也可通过其他方式来安装,具体可以参考:https://github.com/huggingface/transformers
2、如何使用 使用transformers前需要下载好pytorch(版本>=1.0)或者tensorflow2.0。下面以pytorch为例,来演示使用方法
1、若要导入所有包可以输入:
import torch from transformers import * 2、若要导入指定的包可以输入:
import torch from transformers import BertModel 3、加载预训练权重和词表
UNCASED = ./bert-base-uncased bert = BertModel.from_pretrained(UNCASED) 注意:加载预训练权重时需要下载好预训练的权重文件,一般来说,当缓存文件中没有所需文件时(第一次使用),只要网络没有问题,就会自动下载。当网络出现问题的时候,就需要手动下载预训练权重了。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】用CNN的结构打败CNN(深入浅出transformer) https://www.yhzz.com.cn/a/12137.html