【机器学习】通俗的决策树算法讲解和应用

决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树学习通常包括 3 个步骤: 特征选择、决策树的生成和决策树的修剪。
2 决策树场景一个叫做 “二十个问题” 的游戏,游戏的规则很简单: 参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。
一个邮件分类系统,大致工作流程如下: 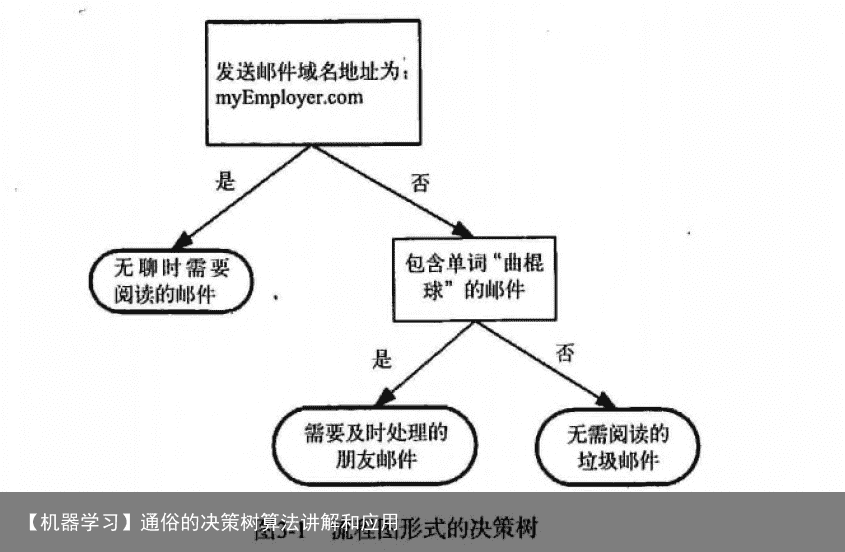 首先检测发送邮件域名地址。如果地址为 myEmployer.com, 则将其放在分类 “无聊时需要阅读的邮件”中。 如果邮件不是来自这个域名,则检测邮件内容里是否包含单词 “曲棍球” , 如果包含则将邮件归类到 “需要及时处理的朋友邮件”, 如果不包含则将邮件归类到 “无需阅读的垃圾邮件” 。 决策树的定义:
首先检测发送邮件域名地址。如果地址为 myEmployer.com, 则将其放在分类 “无聊时需要阅读的邮件”中。 如果邮件不是来自这个域名,则检测邮件内容里是否包含单词 “曲棍球” , 如果包含则将邮件归类到 “需要及时处理的朋友邮件”, 如果不包含则将邮件归类到 “无需阅读的垃圾邮件” 。 决策树的定义:
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型: 内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
用决策树对需要测试的实例进行分类: 从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。
3 决策树开发流程 收集数据: 可以使用任何方法。 准备数据: 树构造算法 (这里使用的是ID3算法,只适用于标称型数据,这就是为什么数值型数据必须离散化。 还有其他的树构造算法,比如CART) 分析数据: 可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。 训练算法: 构造树的数据结构。 测试算法: 使用训练好的树计算错误率。 使用算法: 此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。优点: 计算复杂度不高,输出结果易于理解,数据有缺失也能跑,可以处理不相关特征。 缺点: 容易过拟合。 适用数据类型: 数值型和标称型。
4 决策树的实际运用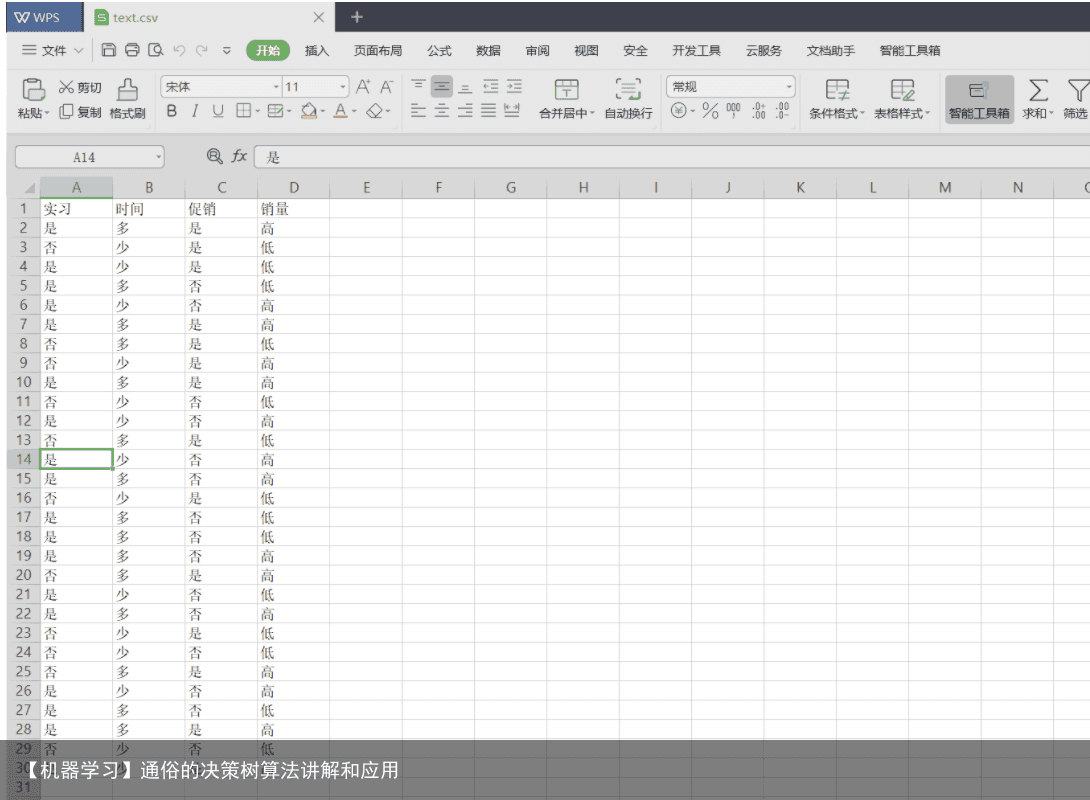 代码:
代码:
运行结果: 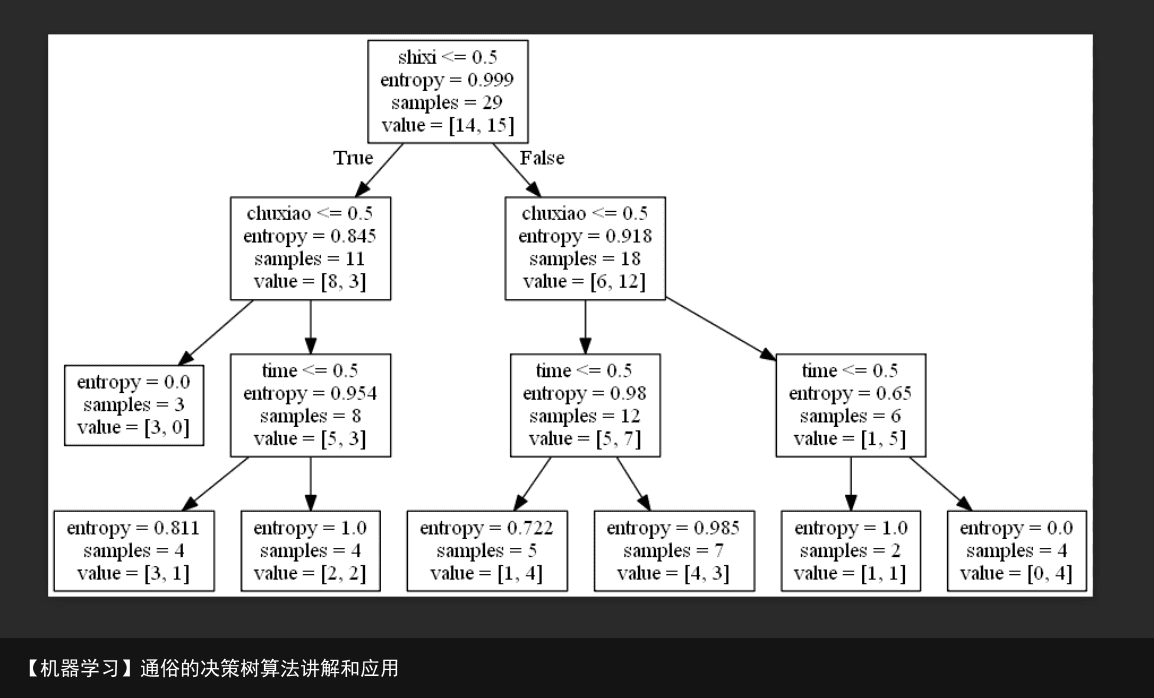 结果中的value是最终结果的类别 entropy是权值 samples是其夫节点判断结果的样本数 每一个框的第一个值是我们对数据处理后的一个判断。(就像判断一个人的年龄<30,如果是就根据指示跳到下一层,依次类推) 逐层判断,最终得到预测值
结果中的value是最终结果的类别 entropy是权值 samples是其夫节点判断结果的样本数 每一个框的第一个值是我们对数据处理后的一个判断。(就像判断一个人的年龄<30,如果是就根据指示跳到下一层,依次类推) 逐层判断,最终得到预测值
初次做NDWI需要将一个波段上大于0的值显示成一种颜色进行影像分类,搜索了很久也没找到颜色显示的方法。最终在同门的帮助下终于学会了,秉着不让其他人再次受这样的磨难我将其步足先给大家。 1.在Toolbox栏索搜tree,选择New Decision Tree.如下图所示。 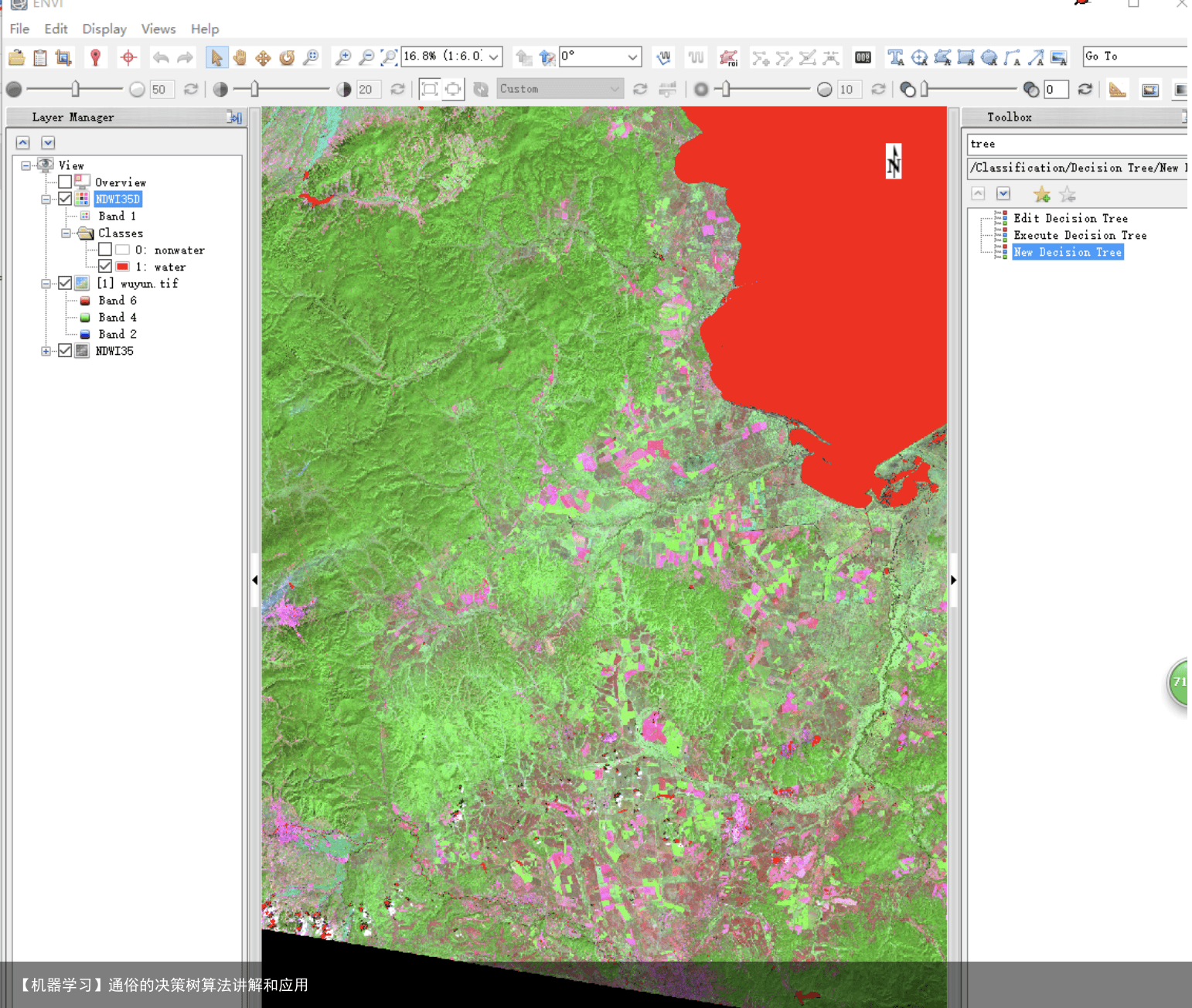
2.进入New Decision Tree,点击file新建New Tree 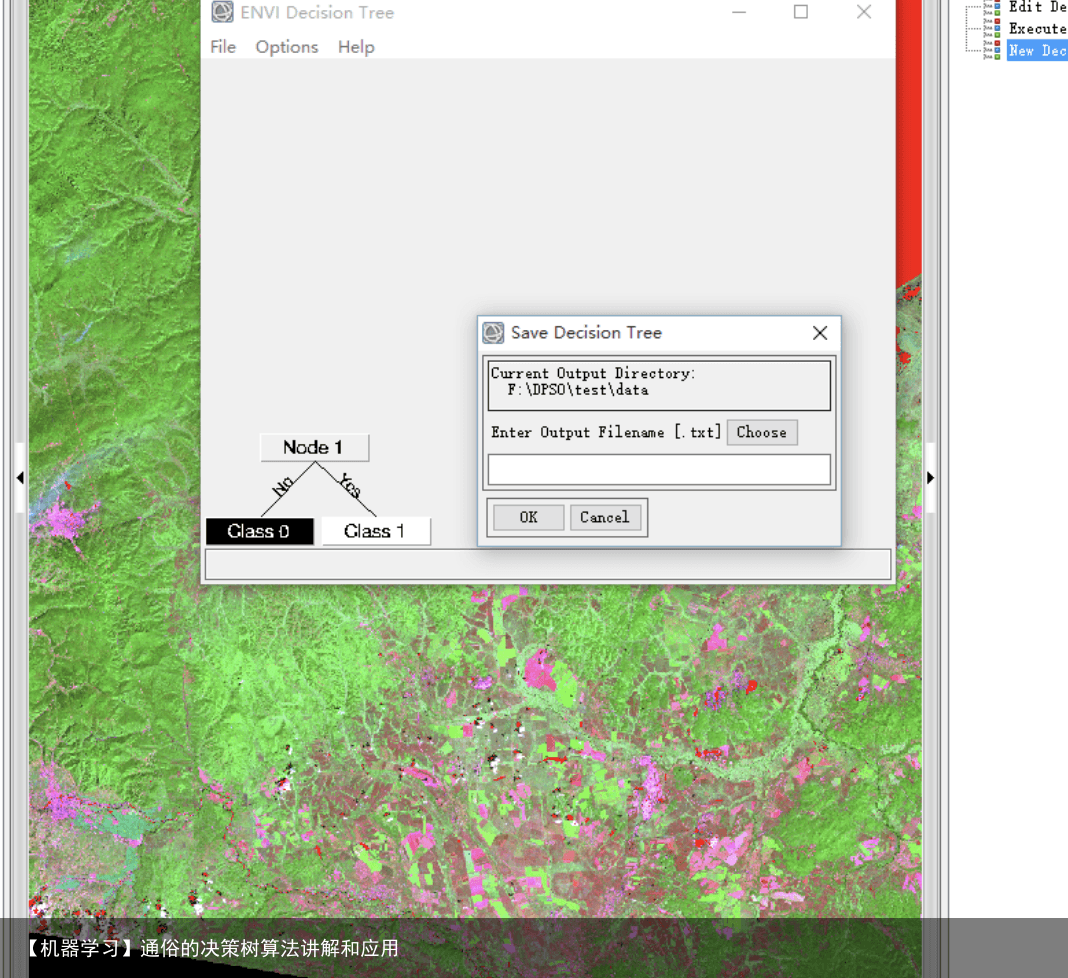
决策树是一种自上而下,对样本数据进行树形分类的算法,既可以用于分类,又可以用于回归。决策树的构建过程也对应着对特征空间的划分:从根结点开始,计算该结点所有可能特征的信息增益(比)或基尼系数,选择信息增益(比)最大或基尼系数最小的特征作为结点的特征,由该特征的不同取值对训练数据进行分割,建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益(比)很大或基尼系数很小或没有特征可以选择为止。最后每个子集都被分到叶结点上,即都有了明确的类,这就得到一个决策树。(每个内部结点表示一个特征,叶结点表示一个类。) 决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的剪枝。决策树相当于用极大似然法进行概率模型的选择,其损失函数为正则化的极大似然函数 。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【机器学习】通俗的决策树算法讲解和应用 https://www.yhzz.com.cn/a/12093.html