【机器学习】Apriori 算法进行关联分析和FP-growth算法

关联分析是一种在大规模数据集中寻找有趣关系的任务。 这些关系可以有两种形式:
频繁项集(frequent item sets): 经常出现在一块的物品的集合。 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。 相关术语
关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者 关联规则学习(association rule learning) 。 下面是用一个 杂货店 例子来说明这两个概念,如下图所示:
 频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。
那么 频繁 的定义是什么呢?怎么样才算频繁呢? 度量它们的方法有很多种,这里我们来简单的介绍下支持度和可信度。
支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的支持度为 3/5。 可信度: 针对一条诸如 {尿布} -> {葡萄酒} 这样具体的关联规则来定义的。这条规则的 可信度 被定义为 支持度({尿布, 葡萄酒})/支持度({尿布}),从图中可以看出 支持度({尿布, 葡萄酒}) = 3/5,支持度({尿布}) = 4/5,所以 {尿布} -> {葡萄酒} 的可信度 = 3/5 / 4/5 = 3/4 = 0.75。 支持度 和 可信度 是用来量化 关联分析 是否成功的一个方法。 假设想找到支持度大于 0.8 的所有项集,应该如何去做呢? 一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品成千上万时,上述做法就非常非常慢了。 我们需要详细分析下这种情况并讨论下 Apriori 原理,该原理会减少关联规则学习时所需的计算量。
Apriori 原理
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。 所有可能的情况如下: 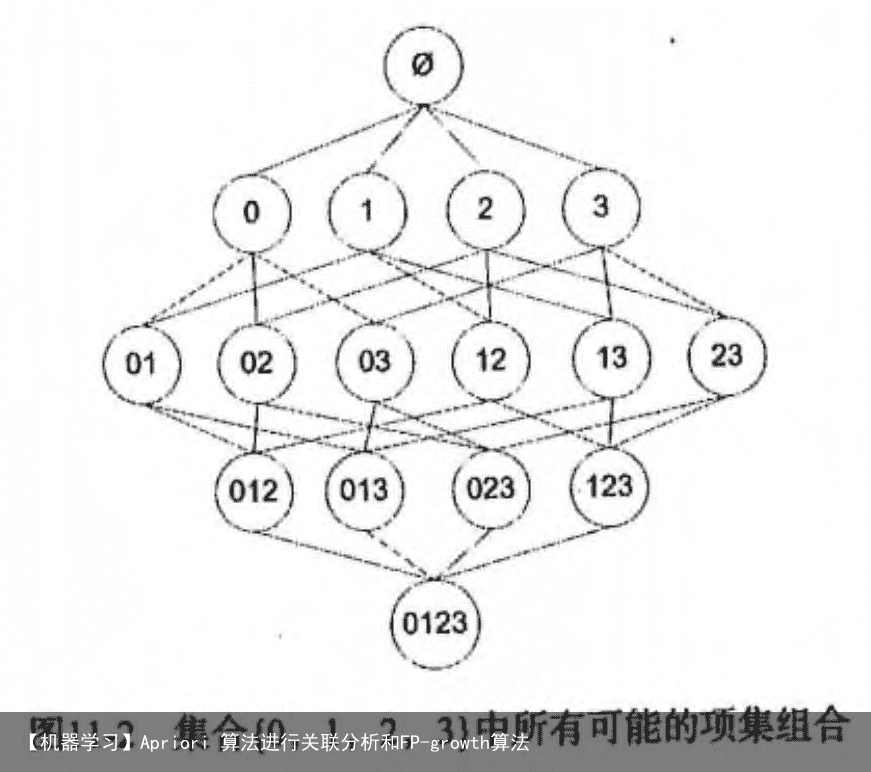 Apriori 算法优缺点
Apriori 算法优缺点
优点: 易编码实现
缺点: 在大数据集上可能较慢
适用数据类型: 数值型 或者 标称型数据。 Apriori 算法流程步骤:
收集数据: 使用任意方法。
准备数据: 任何数据类型都可以,因为我们只保存集合。
分析数据: 使用任意方法。
训练数据: 使用Apiori算法来找到频繁项集。
测试算法: 不需要测试过程。
使用算法: 用于发现频繁项集以及物品之间的关联规则。 至此就完成了Apriori算法的全部过程。
接下来python实现Apriori算法
#-*- coding: utf-8 -*- from __future__ import print_function import pandas as pd #自定义连接函数,用于实现L_{k-1}到C_k的连接 def connect_string(x, ms): x = list(map(lambda i:sorted(i.split(ms)), x)) l = len(x[0]) r = [] for i in range(len(x)): for j in range(i,len(x)): if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]: r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]])) return r #寻找关联规则的函数 def find_rule(d, support, confidence, ms = u–): result = pd.DataFrame(index=[support, confidence]) #定义输出结果 support_series = 1.0*d.sum()/len(d) #支持度序列 column = list(support_series[support_series > support].index) #初步根据支持度筛选 k = 0 while len(column) > 1: k = k+1 print(u\n正在进行第%s次搜索… %k) column = connect_string(column, ms) print(u数目:%s… %len(column)) sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数 #创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。 d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度 column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选 support_series = support_series.append(support_series_2) column2 = [] for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B–>C还是B+C–>A还是C+A–>B? i = i.split(ms) for j in range(len(i)): column2.append(i[:j]+i[j+1:]+i[j:j+1]) cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列 for i in column2: #计算置信度序列 cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])] for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选 result[i] = 0.0 result[i][confidence] = cofidence_series[i] result[i][support] = support_series[ms.join(sorted(i.split(ms)))] result = result.T.sort_values([confidence,support], ascending = False) #结果整理,输出 print(u\n结果为:) print(result) return result结果如下 support confidence e—a 0.3 1.000000 e—c 0.3 1.000000 c—e—a 0.3 1.000000 a—e—c 0.3 1.000000 c—a 0.5 0.714286 a—c 0.5 0.714286 a—b 0.5 0.714286 c—b 0.5 0.714286 b—a 0.5 0.625000 b—c 0.5 0.625000 a—c—e 0.3 0.600000 b—c—a 0.3 0.600000 a—c—b 0.3 0.600000 a—b—c 0.3 0.600000
2 FP-growth算法理解和实现FP-growth算法理解 FP-growth(Frequent Pattern Tree, 频繁模式树),是韩家炜老师提出的挖掘频繁项集的方法,是将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或频繁项对,即常在一块出现的元素项的集合FP树。 FP-growth算法比Apriori算法效率更高,在整个算法执行过程中,只需遍历数据集2次,就能够完成频繁模式发现,其发现频繁项集的基本过程如下: (1)构建FP树 (2)从FP树中挖掘频繁项集
FP-growth的一般流程如下: 1:先扫描一遍数据集,得到频繁项为1的项目集,定义最小支持度(项目出现最少次数),删除那些小于最小支持度的项目,然后将原始数据集中的条目按项目集中降序进行排列。 2:第二次扫描,创建项头表(从上往下降序),以及FP树。 3:对于每个项目(可以按照从下往上的顺序)找到其条件模式基(CPB,conditional patten base),递归调用树结构,删除小于最小支持度的项。如果最终呈现单一路径的树结构,则直接列举所有组合;非单一路径的则继续调用树结构,直到形成单一路径即可。 示例说明 如下表所示数据清单(第一列为购买id,第二列为物品项目): 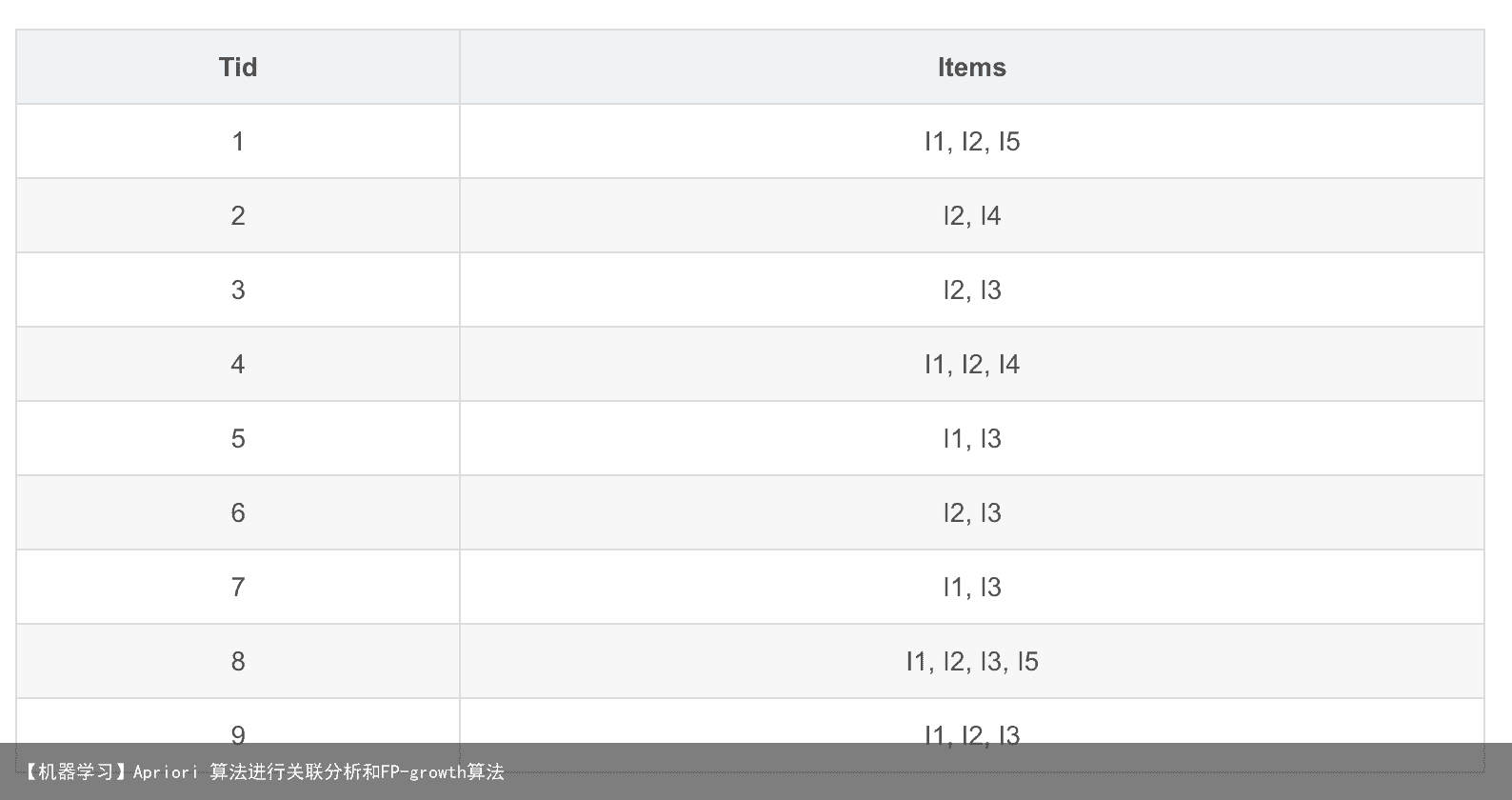 第一步:构建FP树
第一步:构建FP树
I1 I2 I3 I4 I5 6 7 6 2 2
设定最小支持度(即物品最少出现的次数)为2 按降序重新排列物品集(如果出现计数小于2的物品则需删除)I2 I1 I3 I4 I5 7 6 6 2 2
根据项目(物品)出现的次数重新调整物品清单Tid Items 1 I2, I1, I5 2 I2, I4 3 I2, I3 4 I2, I1, I4 5 I1, I3 6 I2, I3 7 I1, I3 8 I2, I1, I3, I5
3 FP增长算法的频繁项集产生FP-growth是一种以自底向上方式探索树,由FP树产生频繁项集的算法,给定上面构建的FP树,算法首先查找以e结尾的频繁项集,接下来是b,c,d,最后是a,由于每一个事务都映射到FP树中的一条路径,因为通过仅考察包含特定节点(例如e)的路径,就可以发现以e结尾的频繁项集,使用与节点e相关联的指针,可以快速访问这些路径,下图显示了所提取的路径,后面详细解释如何处理这些路径,以得到频繁项集。 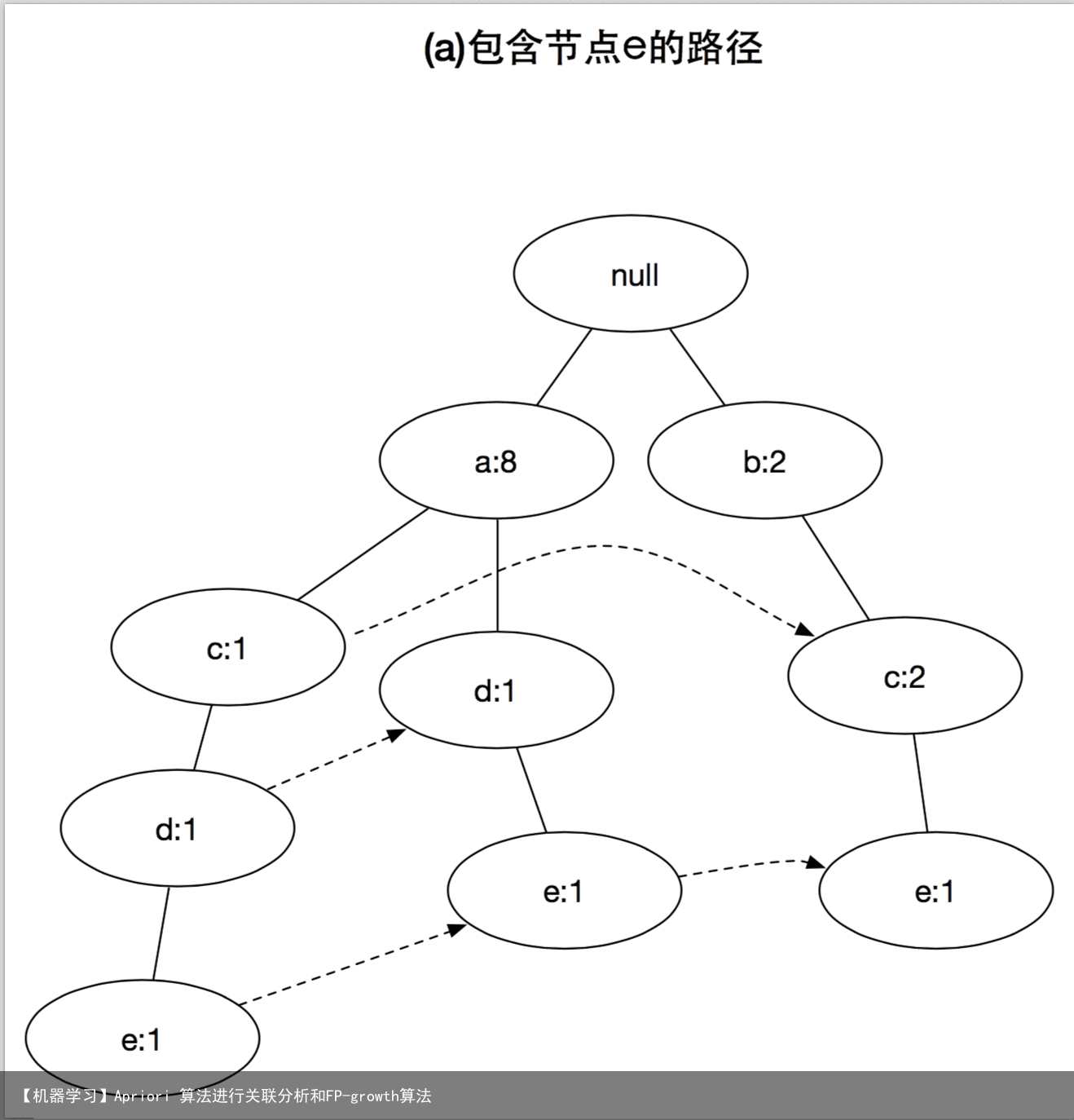
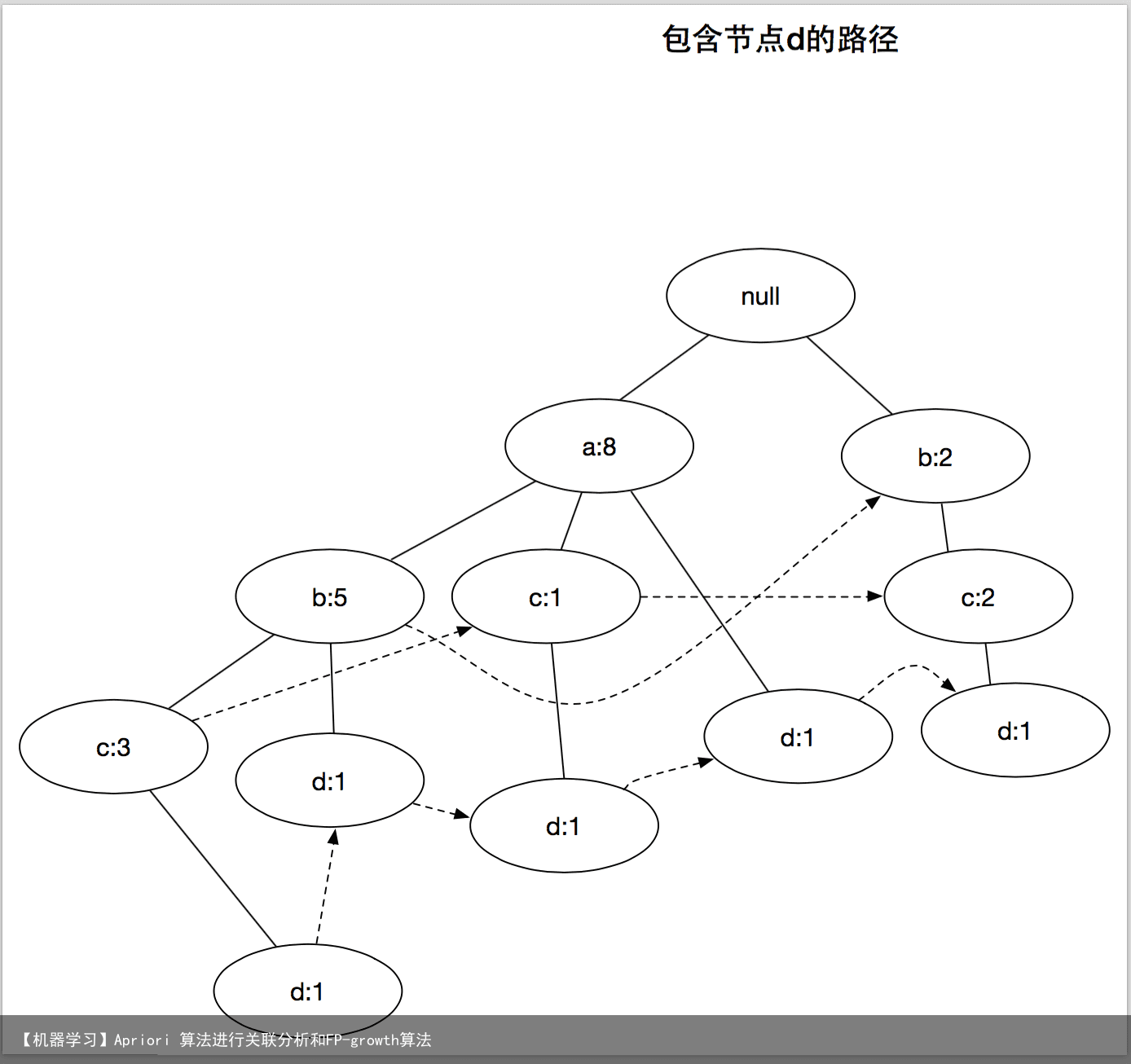
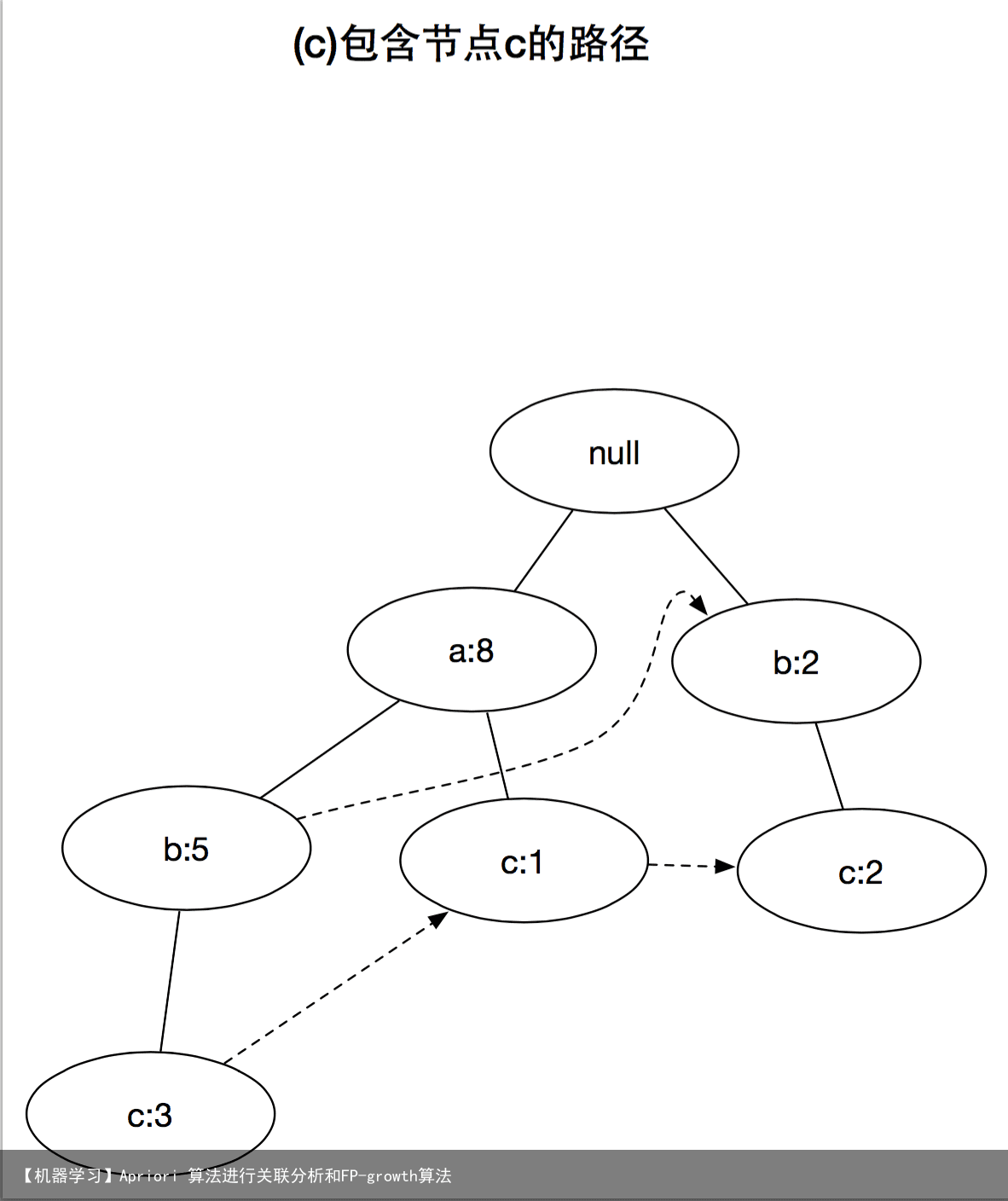

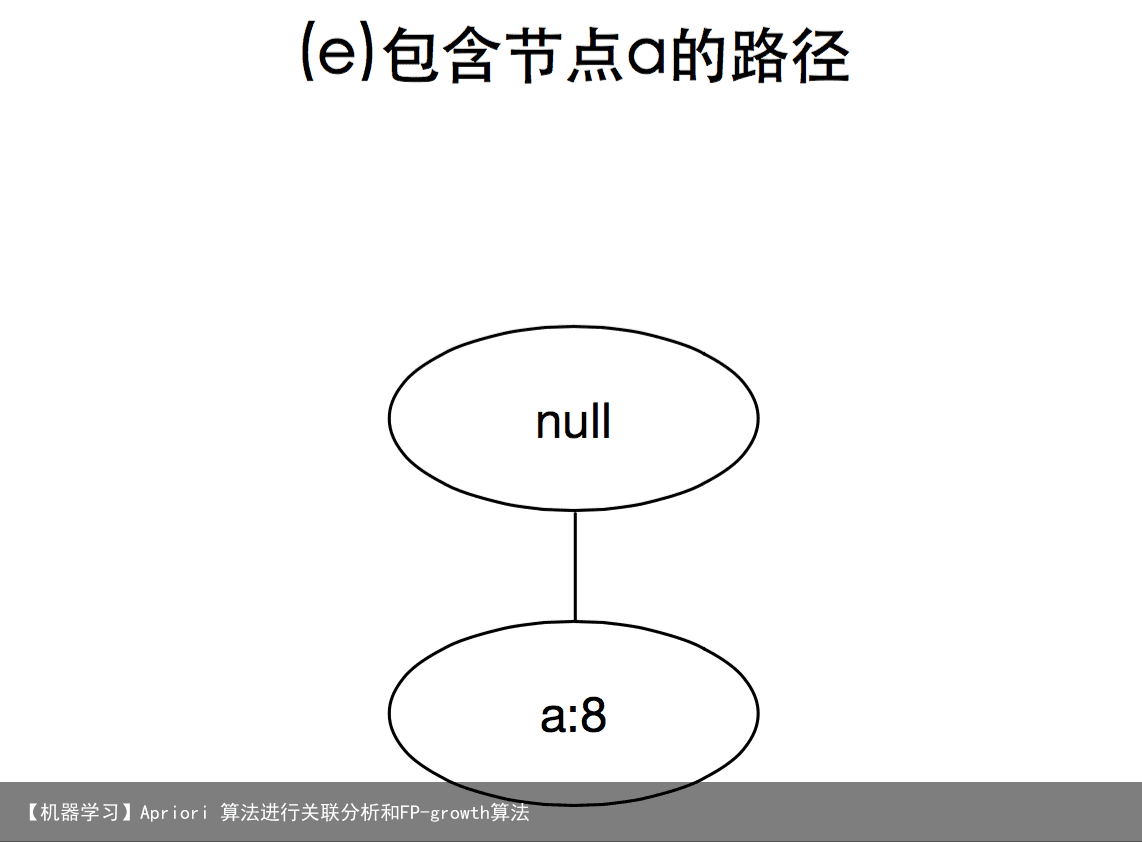 上面的图演示了讲频繁项集产生的问题分解成多个子问题,其中每个子问题分别涉及发现以e,d,c,b和a结尾的频繁项集
上面的图演示了讲频繁项集产生的问题分解成多个子问题,其中每个子问题分别涉及发现以e,d,c,b和a结尾的频繁项集
发现以e结尾的频繁项集之后,算法通过处理与节点d相关联的路径,进一步寻找以d为结尾的频繁项集,继续该过程,直到处理了所有与节点c,b和a相关联的路径为止,上面的图分别显示了这些项的路径,而他们对应的频繁项集汇总在下表中

FP树构造代码实现
def updateHeader(nodeToTest, targetNode): while nodeToTest.nodeLink != None: nodeToTest = nodeToTest.nodeLink nodeToTest.nodeLink = targetNode def updateFPtree(items, inTree, headerTable, count): if items[0] in inTree.children: # 判断items的第一个结点是否已作为子结点 inTree.children[items[0]].inc(count) else: # 创建新的分支 inTree.children[items[0]] = treeNode(items[0], count, inTree) # 更新相应频繁项集的链表,往后添加 if headerTable[items[0]][1] == None: headerTable[items[0]][1] = inTree.children[items[0]] else: updateHeader(headerTable[items[0]][1], inTree.children[items[0]]) # 递归 if len(items) > 1: updateFPtree(items[1::], inTree.children[items[0]], headerTable, count) def createFPtree(dataSet, minSup=1): headerTable = {} for trans in dataSet: for item in trans: headerTable[item] = headerTable.get(item, 0) + dataSet[trans] for k in headerTable.keys(): if headerTable[k] < minSup: del(headerTable[k]) # 删除不满足最小支持度的元素 freqItemSet = set(headerTable.keys()) # 满足最小支持度的频繁项集 if len(freqItemSet) == 0: return None, None for k in headerTable: headerTable[k] = [headerTable[k], None] # element: [count, node] retTree = treeNode(Null Set, 1, None) for tranSet, count in dataSet.items(): # dataSet:[element, count] localD = {} for item in tranSet: if item in freqItemSet: # 过滤,只取该样本中满足最小支持度的频繁项 localD[item] = headerTable[item][0] # element : count if len(localD) > 0: # 根据全局频数从大到小对单样本排序 orderedItem = [v[0] for v in sorted(localD.items(), key=lambda p:p[1], reverse=True)] # 用过滤且排序后的样本更新树 updateFPtree(orderedItem, retTree, headerTable, count) return retTree, headerTable测试实例
# 数据集 def loadSimpDat(): simDat = [[r,z,h,j,p], [z,y,x,w,v,u,t,s], [z], [r,x,n,o,s], [y,r,x,z,q,t,p], [y,z,x,e,q,s,t,m]] return simDat # 构造成 element : count 的形式 def createInitSet(dataSet): retDict={} for trans in dataSet: key = frozenset(trans) if retDict.has_key(key): retDict[frozenset(trans)] += 1 else: retDict[frozenset(trans)] = 1 return retDict simDat = fpgrowth.loadSimpDat() initSet = fpgrowth.createInitSet(simDat) myFPtree, myHeaderTab = fpgrowth.createFPtree(initSet, 3) # 最小支持度3 myFPtree.disp()FP-growth其实是一种特殊的数据结构的应用,本质上是某种前缀树+相似元素链表的结构。FP-growth算法提供了一种相对更快的发现频繁项集的方法,它之所以快,是因为它只遍历1次数据集,即可将整个数据集构造成一棵FP树,之后从FP树中发现频繁项集。提取出频繁项集之后,就可以进一步挖掘关联规则。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【机器学习】Apriori 算法进行关联分析和FP-growth算法 https://www.yhzz.com.cn/a/12055.html