【深度学习】Keras加载权重更新模型训练的教程(MobileNet)

重新建立模型并且复制原模型的layer,例:
model = Sequential() for layer in source_model.layers[:-1]: # 跳过最后一层 model.add(layer) model.summary()当然可以自定义增加层用来去掉模型的最后几层,例:
model = Sequential() for layer in source_model.layers[:-1]: # 跳过最后一层 model.add(layer) model.add(Dense(2, activation=softmax)) model.summary()使用函数型模型,即functional model,例:
model = Model(inputs=source_model.input, outputs=source_model.layers[-2].output) # 这里的source_model即为原来的模型同样也可以添加层,例:
prediction = Dense(2, activation=softmax)(source_model.layers[-2].output) model = Model(inputs=source_model.input, outputs=prediction) 2 keras常用模块的简单介绍Input,Model,Sequential,这三个模块是以前老的接口,新的版本已经将它们融合到后面的模块当中
以__开头的模块是一些内嵌的模块
activations是激活函数,包括像sigmoid,relu,softmax等
applications是应用,这里面提供了已经训练好的keras模型,像图像识别的VGG等
backend是后端函数,keras通过它来操作其他的后端执行代码,像tensorflow,theano等,在后面使用models时,models会自动地调用
callbacks是一个回调的抽象函数,在高级应用里面可以用来展示训练过程中网络内部的状态
constraints是一个约束项,主要是能够对神经网络进行约束,来防止神经网络的过拟合
datasets里面包含了很多神经网络常用的数据集
engine是引擎模块,是layers的核心代码,主要是用来实现神经网络的拓补结构,后面的层的构建都是从这里继承而来
initializers是初始化方法
layers里面包含了keras已经实现的一些网络层,像全连接层Dense,卷积神经网络中的Conv
legacy是遗留代码,旧版本的代码都放在里面
losses是目标函数,也就损失函数,代价函数等,包括像均方差误差,交叉熵等等,用来衡量神经网络训练过程中的训练的好坏,能够看在迭代的过程中神经网络的一个训练情况
metrics是评估函数,可以用来评估神经网络的性能,里面包括像准确度,召回率等
models是模型库,Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。序贯模型:使用序贯模型可以像搭积木一样一层一层地网上叠加神经网络
optimizers是优化器,神经网络编译时必备的参数之一,可以用来在神经网络训练过程当中来更新权值的一个方法
preprocessing是预处理模块,包括对数据,序列,文本以及图像数据的预处理
regularizers是正则化方法,是用来防止神经网络在训练过程中出现过拟合
utils工具模块,本模块提供了一系列有用工具,用于提供像数据转换,数据规范化等功能
wrappers包装器(层封装器),能够将普通层进行包装,比如将普通数据封装成时序数据
举例:
from keras.models import Model from keras.layers import Input, Dense from keras.models import Sequential from tensorflow.keras.layers import Dense, Input, Layer from tensorflow.keras import layers from keras.models import Model from keras.layers import Input, Dense # 加载 MobileNet 的预训练模型权重 weights_path = basic_path + keras_model_data/mobilenet_1_0_224_tf_no_top.h5 # 图像数据的行数和列数 height, width = 160, 160 source_model = MobileNet(input_shape=[height,width,3],classes=2) source_model.load_weights(weights_path,by_name=True) # # a layer instance is callable on a tensor, and returns a tensor # x = Dense(64, activation=relu)(model) # # 输入inputs,输出x # # (inputs)代表输入 # x = Dense(64, activation=relu)(x) # # 输入x,输出x # model = Dense(2, activation=softmax)(x) # print(model.summary()) model = Sequential() for layer in source_model.layers[:-5]: # 跳过最后一层 model.add(layer) model.add(layers.Flatten(input_shape=(5, 5, 1024))) model.add(layers.Dense(256, activation=relu, input_dim=(5*5*1024))) model.add(layers.Dropout(0.5)) model.add(layers.Dense(1, activation=sigmod)) model.summary()为了避免训练过程中遇到断电等突发事件,导致模型训练成果无法保存。 我们可以通过 ModelCheckpoint 规定在固定迭代次数后保存模型。 同时,我们设置在下一次重启训练时,会检查是否有上次训练好的模型,如果有,就先加载已有的模型权重。 这样就可以在上次训练的基础上继续模型的训练了。
def save_model(model, checkpoint_save_path, model_dir): “”” 保存模型,每迭代3次保存一次 :param model: 训练的模型 :param checkpoint_save_path: 加载历史模型 :param model_dir: :return: “”” if os.path.exists(checkpoint_save_path): print(“模型加载中”) model.load_weights(checkpoint_save_path) print(“模型加载完毕”) checkpoint_period = ModelCheckpoint( # 模型存储路径 model_dir + ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5, # 检测的指标 monitor=val_acc, # ‘auto’,‘min’,‘max’中选择 mode=max, # 是否只存储模型权重 save_weights_only=False, # 是否只保存最优的模型 save_best_only=True, # 检测的轮数是每隔2轮 period=2 ) return checkpoint_period手动调整学习率(可调参) 学习率的手动设置可以使模型训练更加高效。 这里我们设置当模型在两轮迭代后,准确率没有上升,就调整学习率。
# 学习率下降的方式,acc三次不下降就下降学习率继续训练 reduce_lr = ReduceLROnPlateau( monitor=acc, # 检测的指标 factor=0.5, # 当acc不下降时将学习率下调的比例 patience=2, # 检测轮数是每隔两轮 verbose=2 # 信息展示模式 )早停法(可调参) 当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能。 但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合。 当网络在训练集上表现越来越好,错误率越来越低的时候,就极有可能出现了过拟合。 早停法就是当我们在检测到这一趋势后,就停止训练,这样能避免继续训练导致过拟合的问题。
early_stopping = EarlyStopping( monitor=val_loss, # 检测的指标 min_delta=0, # 增大或减小的阈值 patience=10, # 检测的轮数频率 verbose=1 # 信息展示的模式 )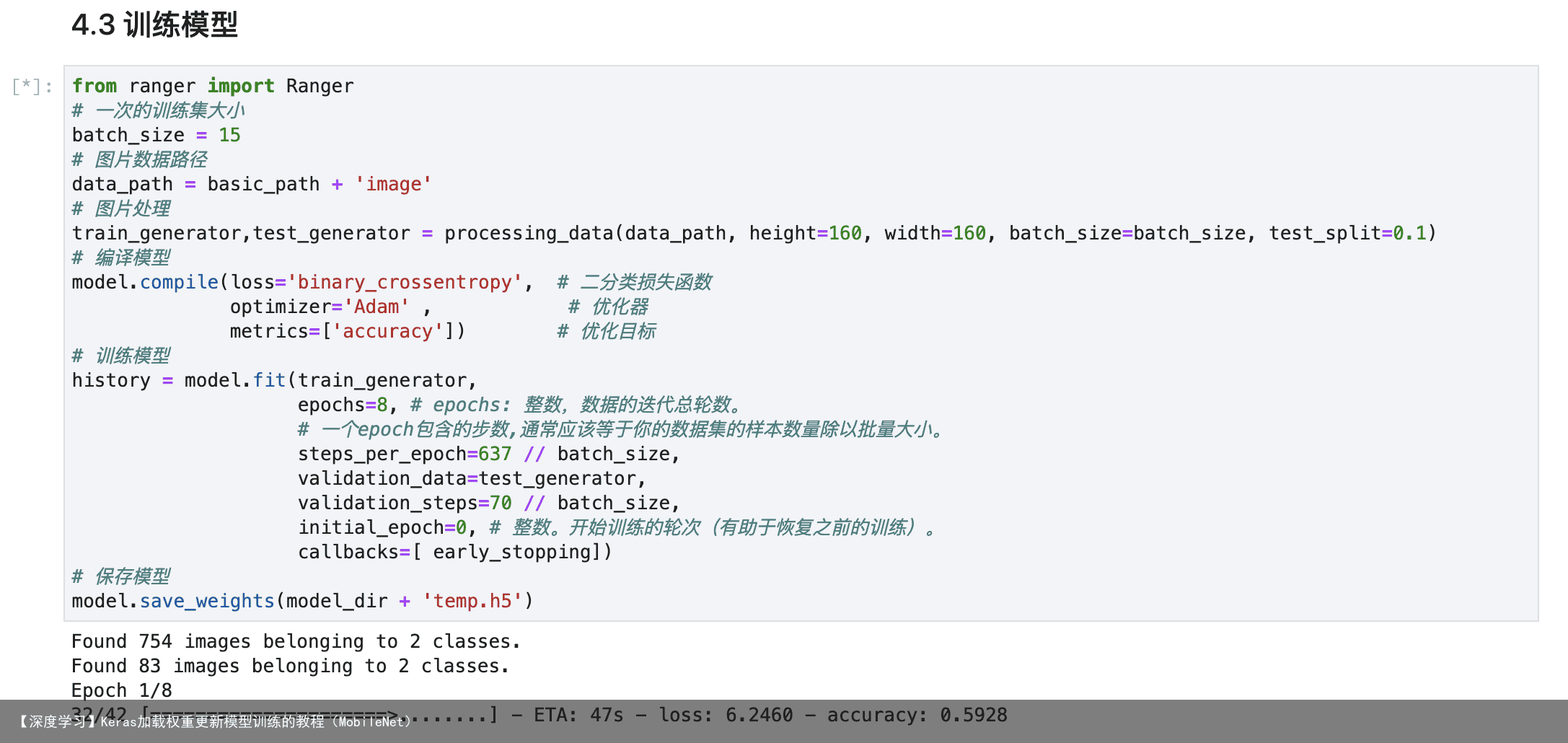



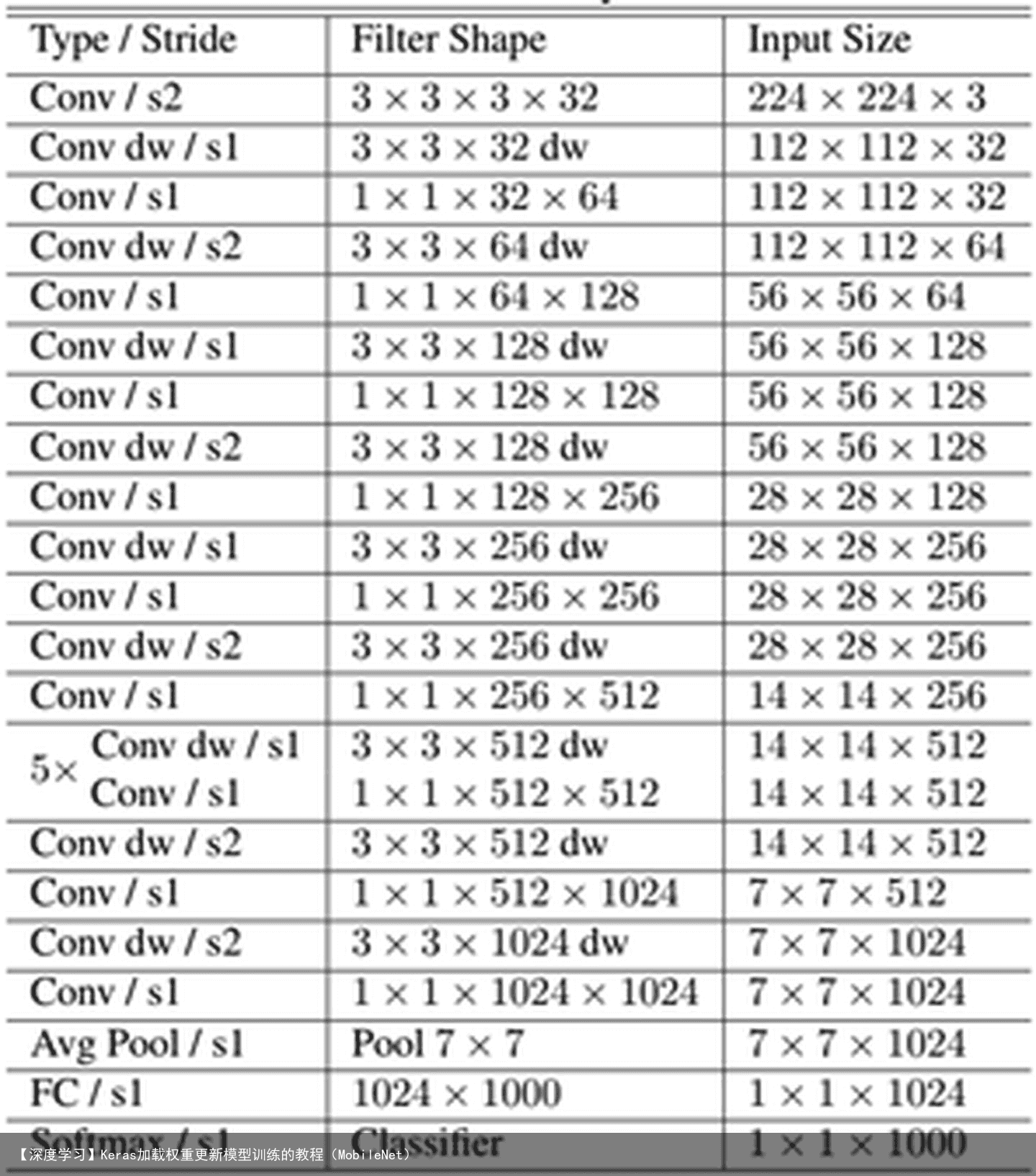
MobileNet网络结构 前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图所示。 MobileNet的网络结构如表所示。首先是一个3×3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1×1,根据预测类别大小加上全连接层,最后是一个softmax层。如果单独计算depthwise convolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1×1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1×1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1×1卷积,除此之外还有就是全连接层占了一部分参数。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】Keras加载权重更新模型训练的教程(MobileNet) https://www.yhzz.com.cn/a/11985.html