
 有两个参数可调, alpha和gamma.
有两个参数可调, alpha和gamma.
alpha是控制类别不平衡的.
gamma是控制难易样本的.
一般都是调alpha, gamma自己没调过,有大佬调过的可以发表一下见解.
alpha越大,recall会越高,precision会越低.
当alpha增大时,比如说增大到1, 以一个检测的二分类为背景, 这时候focal loss就不会包含负样本的loss了, 想要focal loss最小我只要全预测为正即可, 这时候自然recall就会100%, precision也会降低.
当alpha减小,比如减小到0, 这时候focal loss中只有负样本的loss, 那只要网络对所有样本全预测成负的就可以了.这时候recall就变成了0, precision也就100%了.
2 实验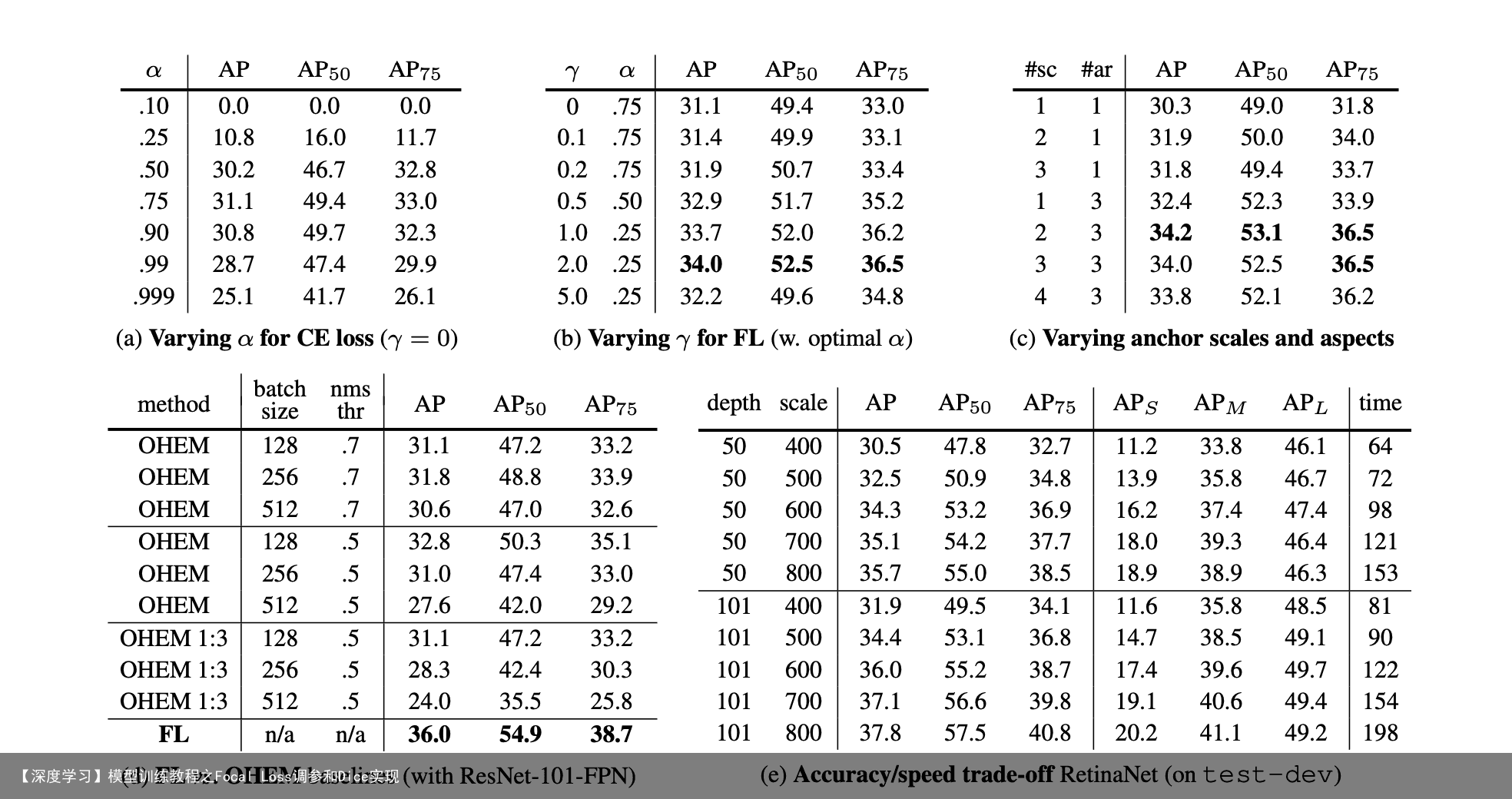
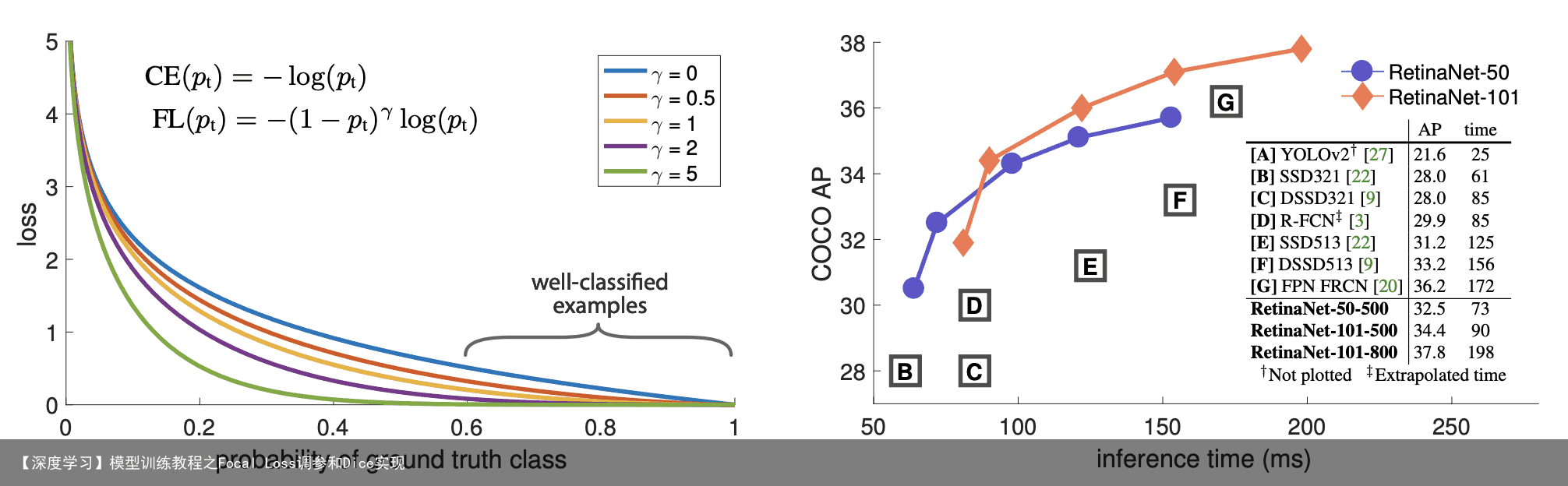
最近因为在做图像分割到一些样本不平均的问题
所以有机会尝试了一下FocalLoss这个损失函数(由Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár提出)
也重新的理解了一次这个损失函数是如何运作
首先我们要知道FocalLoss诞生的原由,要解决什么样的问题?
解决问题 针对one-stage的目标检测框架(例如SSD, YOLO)中正(前景)负(背景)样本极度不平均,负样本loss值主导整个梯度下降, 正样本占比小, 导致模型只专注学习负样本上
在仔细了解FocalLoss之前 我们还是有必要简单回顾一下CE 的过程
二分类 CrossEntropy  y经过sigmoid输出,值在[0, 1]之间 当概率p值越大, 算出的loss值肯定越小
y经过sigmoid输出,值在[0, 1]之间 当概率p值越大, 算出的loss值肯定越小
多分类 CrossEntropy
其实CE的公式简单明了, 但是当遇到样本极度不平均的情况下加总所有的loss值时, 正样本的loss值占比会非常小, 什么意思呢? 我们留到最后的例子说明
把今天的主角请出来!
Focal Loss
 从公式可以看出
从公式可以看出
基于原来的CrossEntropy, 多了一组
 同时多了两个超参数alpha 和 gamma
同时多了两个超参数alpha 和 gamma
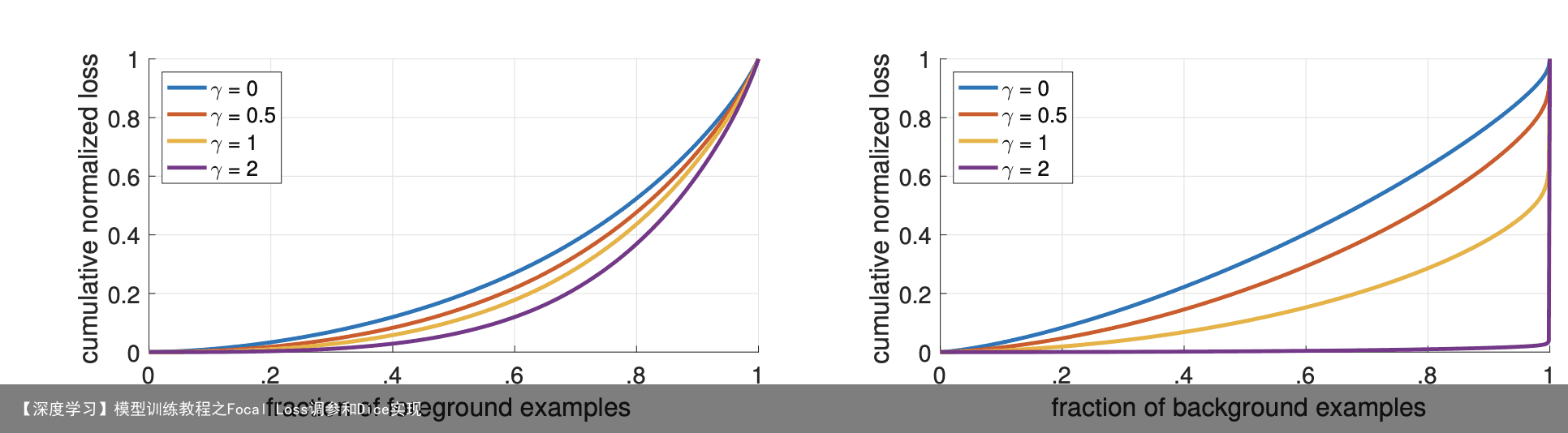
在不考虑alpha和gamma时(1-pt)
所以当pt越大时,赋予的权重就越小, pt越小,赋予的权重就越大
为了能够比较出差异, 直接用极端的例子, 其实也就是one-stage 目标检测的情况
假设我们模型
负样本10000笔资料probability(pt) = 0.95(简单样本), 这边可以理解为easy-example 正样本10笔资料, probability(pt) = 0.05(困难样本),
带入FocalLoss 假设alpha = 0.25, gamma=2
1 – 负样本 : 0.75(1-0.95)^2 0.02227 样本数(100000) = 0.00004176 100000 = 4.1756 2 – 正样本 : 0.25 (1-0.05)^2 1.30102 样本数(10)= 0.29354264 10 = 2.935 3total loss = 4.175 + 2.935 = 7.110 4正样本占比:2.935/7.110 = 0.4127(与0.0058差距甚大) 经过比较, 我们算出CE正样本的值占总loss比例是0.0058, 而FocalLoss計算的正样本占比是0.4127,相差了71倍, 可以看出FL能有效提升正样本的loss占比
上面的例子中alpha取值为0.25, gamma=2, 这是作者建议的最佳值 alpha 的0.25代表的是正样本, 所以负样本就会是1-0.25 = 0.75
这里也许有些奇怪, 就理论上来看,alpha值设定为0.75(因为正样本通常数量小)是比较合理, 但是毕竟还有gamma值在, 已经将负样本损失值降低许多,可理解为alpha和gamma相互牵制,alpha也不让正样本占比过大,因此最终设定为0.25, 如果有更好的理解欢迎留言一起讨论
PS. gamma = 2, alpha = 0.25是经过作者不断尝试出的一般最佳值
最后我们记得 gamma及 alpha 两兄弟的作用
gamma负责降低简单样本的损失值, 以解决加总后负样本loss值很大 alpha调和正负样本的不平均,如果设置0.25, 那么就表示负样本为0.75, 对应公式 1-alpha
4 多分类 focal loss 以及 dice loss 的pytorch以及keras/tf实现4.1 pytorch 下的多分类 focal loss 以及 dice loss实现
dice loss
class DiceLoss(nn.Module): def __init__(self): super(DiceLoss, self).__init__() def forward(self, input, target): N = target.size(0) smooth = 1 input_flat = input.view(N, -1) target_flat = target.view(N, -1) intersection = input_flat * target_flat loss = 2 * (intersection.sum(1) + smooth) / (input_flat.sum(1) + target_flat.sum(1) + smooth) # loss = 1 – loss.sum() / N return 1 – lossfocal loss
class FocalLoss(nn.Module): def __init__(self, alpha=0.25, gamma=2, logits=False, sampling=mean): super(FocalLoss, self).__init__() self.alpha = alpha self.gamma = gamma self.logits = logits self.sampling = sampling def forward(self, y_pred, y_true): alpha = self.alpha alpha_ = (1 – self.alpha) if self.logits: y_pred = torch.sigmoid(y_pred) pt_positive = torch.where(y_true == 1, y_pred, torch.ones_like(y_pred)) pt_negative = torch.where(y_true == 0, y_pred, torch.zeros_like(y_pred)) pt_positive = torch.clamp(pt_positive, 1e-3, .999) pt_negative = torch.clamp(pt_negative, 1e-3, .999) pos_ = (1 – pt_positive) ** self.gamma neg_ = pt_negative ** self.gamma pos_loss = -alpha * pos_ * torch.log(pt_positive) neg_loss = -alpha_ * neg_ * torch.log(1 – pt_negative) loss = pos_loss + neg_loss if self.sampling == “mean”: return loss.mean() elif self.sampling == “sum”: return loss.sum() elif self.sampling == None: return loss4.2 keras/tf 下的多分类 focal loss 以及 dice loss实现
dice loss
def dice(y_true, y_pred, smooth=1.): y_true_f = K.flatten(y_true) y_pred_f = K.flatten(y_pred) intersection = K.sum(y_true_f * y_pred_f) return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth) def dice_loss(y_true, y_pred): return 1-dice(y_true, y_pred)focal loss
def focal_loss(y_true, y_pred): gamma = 2 alpha = 0.25 tf.where(tensor,a,b):将tensor中true位置元素替换为a中对应位置元素,false的替换为b中对应位置元素 pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred)) pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred)) pt_1 = K.clip(pt_1, 1e-3, .999) pt_0 = K.clip(pt_0, 1e-3, .999) return K.mean(-alpha*K.pow(1.-pt_1, gamma)*K.log(pt_1)-(1-alpha)*K.pow(pt_0, gamma)*K.log(1.-pt_0))附录: 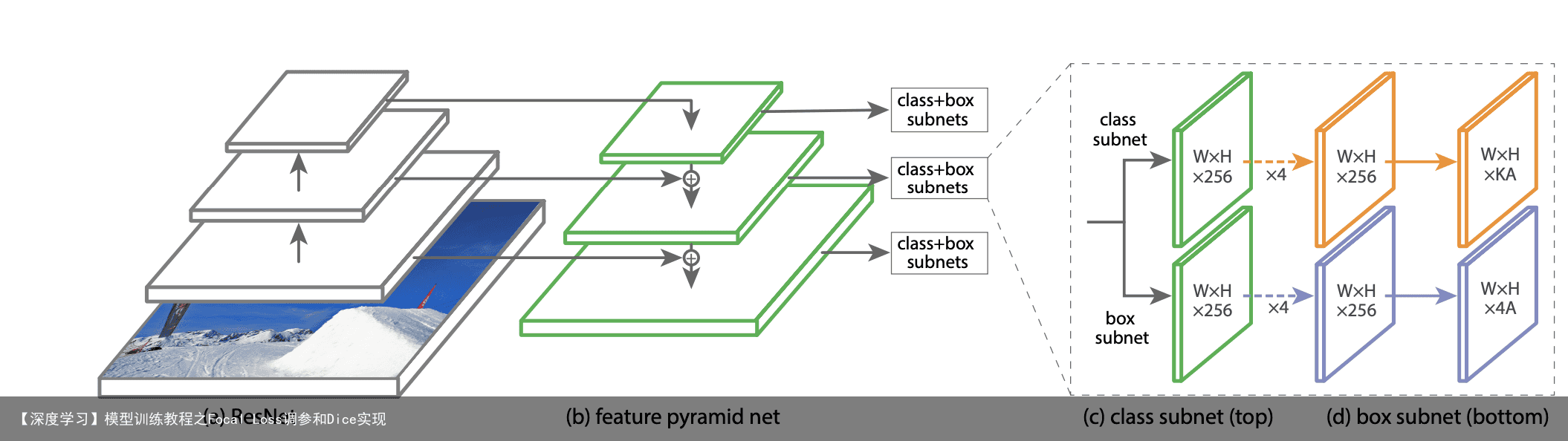
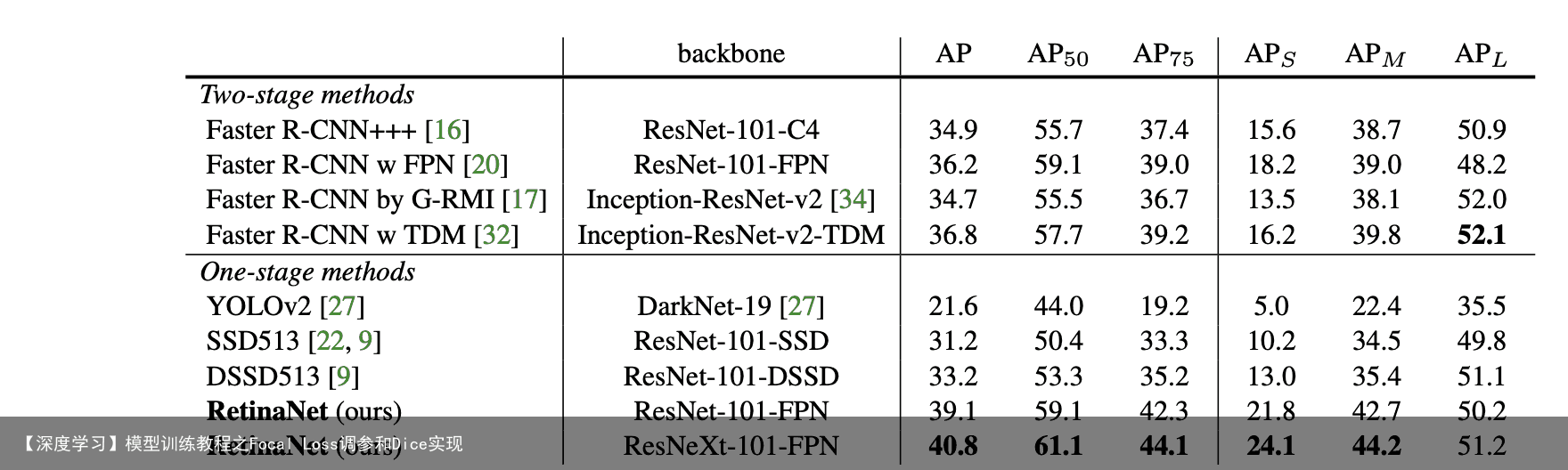
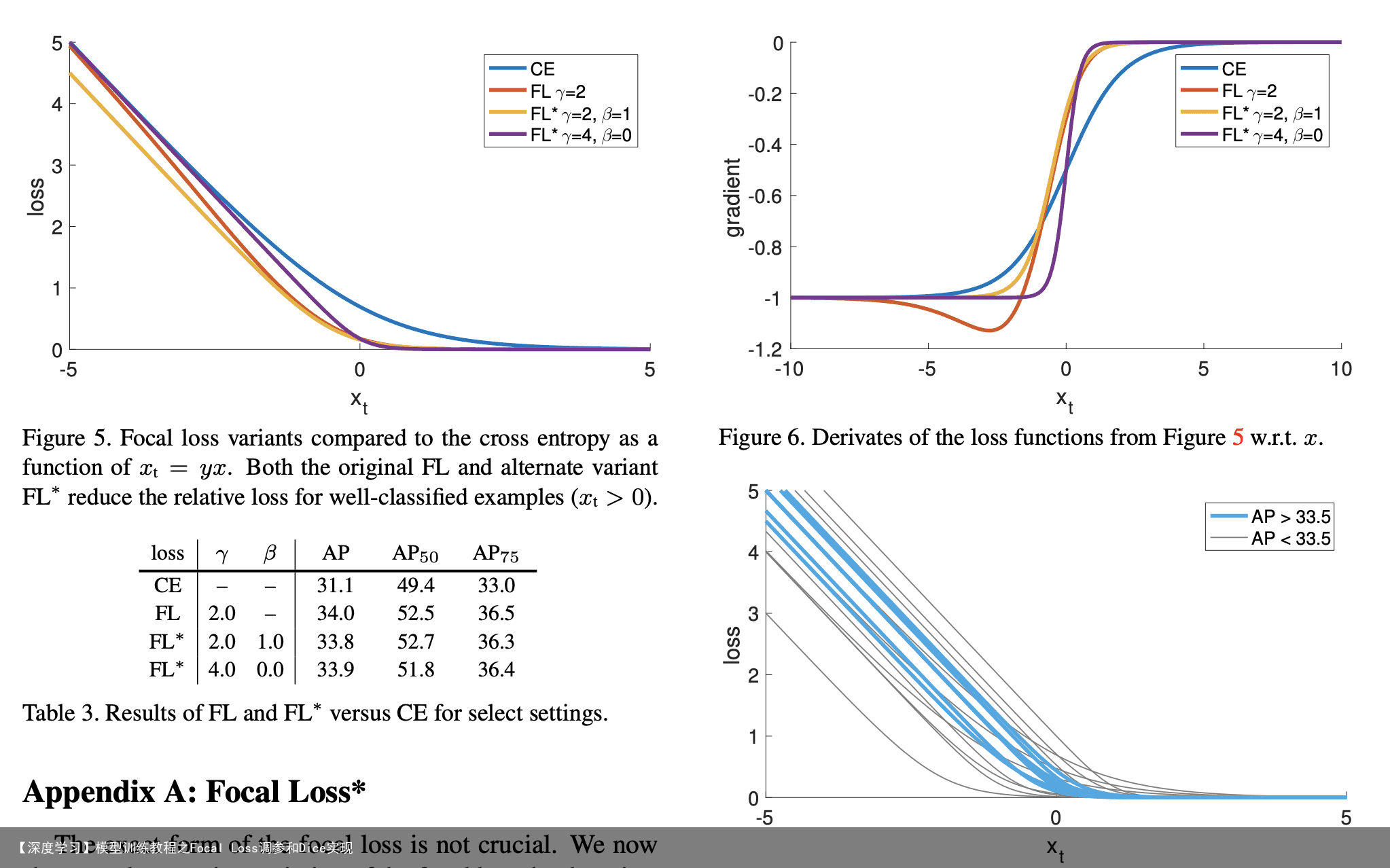
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】模型训练教程之Focal Loss调参和Dice实现 https://www.yhzz.com.cn/a/11955.html