
torch.autograd提供了类和函数用来对任意标量函数进行求导。要想使用自动求导,只需要对已有的代码进行微小的改变。只需要将所有的tensor包含进Variable对象中即可。
torch.autograd.backward(variables, grad_variables, retain_variables=False) Computes the sum of gradients of given variables w.r.t. graph leaves. 给定图的叶子节点variables, 计算图中变量的梯度和。 计算图可以通过链式法则求导。如果variables中的任何一个variable是 非标量(non-scalar)的,且requires_grad=True。那么此函数需要指定grad_variables,它的长度应该和variables的长度匹配,里面保存了相关variable的梯度(对于不需要gradient tensor的variable,None是可取的)。
此函数累积leaf variables计算的梯度。你可能需要在调用此函数之前将leaf variable的梯度置零。
参数说明:
variables (variable 列表) – 被求微分的叶子节点,即 ys 。
grad_variables (Tensor 列表) – 对应variable的梯度。仅当variable不是标量且需要求梯度的时候使用。
retain_variables (bool) – True,计算梯度时所需要的buffer在计算完梯度后不会被释放。如果想对一个子图多次求微分的话,需要设置为True。
v = Variable(torch.Tensor([0, 0, 0]), requires_grad=True) h = v.register_hook(lambda grad: grad * 2) # double the gradient v.backward(torch.Tensor([1, 1, 1])) #先计算原始梯度,再进hook,获得一个新梯度。 print(v.grad.data) 2 2 2 [torch.FloatTensor of size 3] >>> h.remove() # removes the hook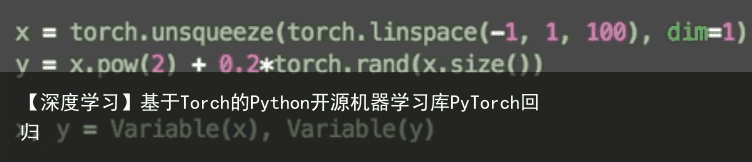 用法:
用法:
非线性激活函数
torch.nn.functional.threshold(input, threshold, value, inplace=False) torch.nn.functional.relu(input, inplace=False) torch.nn.functional.hardtanh(input, min_val=-1.0, max_val=1.0, inplace=False) torch.nn.functional.relu6(input, inplace=False) torch.nn.functional.elu(input, alpha=1.0, inplace=False) torch.nn.functional.leaky_relu(input, negative_slope=0.01, inplace=False) torch.nn.functional.prelu(input, weight) torch.nn.functional.rrelu(input, lower=0.125, upper=0.3333333333333333, training=False, inplace=False) torch.nn.functional.logsigmoid(input) torch.nn.functional.hardshrink(input, lambd=0.5) torch.nn.functional.tanhshrink(input) torch.nn.functional.softsign(input) torch.nn.functional.softplus(input, beta=1, threshold=20) torch.nn.functional.softmin(input) torch.nn.functional.softmax(input) torch.nn.functional.softshrink(input, lambd=0.5) torch.nn.functional.log_softmax(input) torch.nn.functional.tanh(input) torch.nn.functional.sigmoid(input)Normalization 函数 torch.nn.functional.batch_norm(input, running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, eps=1e-05) 线性函数 torch.nn.functional.linear(input, weight, bias=None) Dropout 函数 torch.nn.functional.dropout(input, p=0.5, training=False, inplace=False) 距离函数(Distance functions) torch.nn.functional.pairwisedistance(x1, x2, p=2, eps=1e-06) 计算向量v1、v2之间的距离(成次或者成对,意思是可以计算多个,可以参看后面的参数) $$ \left | x \right |{p}:=\left ( \sum{i=1}^{N}\left | x{i}^{p} \right | \right )^{1/p} $$ 参数:
x1:第一个输入的张量 x2:第二个输入的张量 p:矩阵范数的维度。默认值是2,即二范数。 规格:
输入:(N,D)其中D等于向量的维度 输出:(N,1) 例子:
input1 = autograd.Variable(torch.randn(100, 128)) input2 = autograd.Variable(torch.randn(100, 128)) output = F.pairwise_distance(input1, input2, p=2) output.backward() 损失函数(Loss functions) torch.nn.functional.nll_loss(input, target, weight=None, size_average=True)
Convolution 函数 torch.nn.functional.conv1d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) 对几个输入平面组成的输入信号应用1D卷积。
有关详细信息和输出形状,请参见Conv1d。
参数: – input – 输入张量的形状 (minibatch x in_channels x iW) – weight – 过滤器的形状 (out_channels, in_channels, kW) – bias – 可选偏置的形状 (out_channels) – stride – 卷积核的步长,默认为1
Pooling 函数 torch.nn.functional.avg_pool1d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True) 对由几个输入平面组成的输入信号进行一维平均池化。
有关详细信息和输出形状,请参阅AvgPool1d。
参数: – kernel_size – 窗口的大小 – stride – 窗口的步长。默认值为kernel_size – padding – 在两边添加隐式零填充 – ceil_mode – 当为True时,将使用ceil代替floor来计算输出形状 – count_include_pad – 当为True时,这将在平均计算时包括补零
3 详细的回归DEMO3.1 DATASET
我们创建一些假数据来模拟真实的情况. 比如一个一元二次函数: y = a * x^2 + b, 我们给 y 数据加上一点噪声来更加真实的展示它.
import torch import matplotlib.pyplot as plt x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1) y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1) # 画图 plt.scatter(x.data.numpy(), y.data.numpy()) plt.show()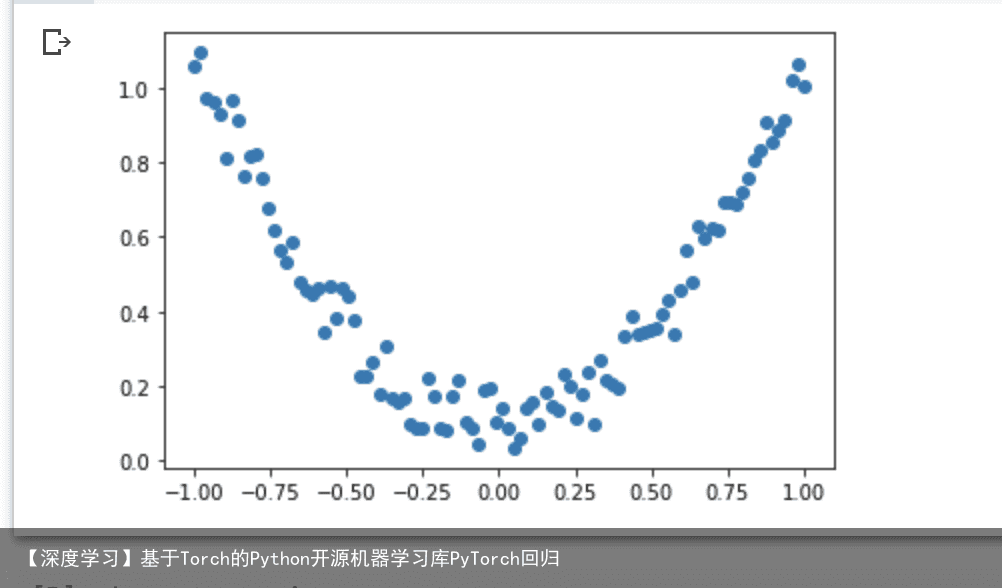
3.2 网络
建立一个神经网络我们可以直接运用 torch 中的体系. 先定义所有的层属性(__init__()), 然后再一层层搭建(forward(x))层于层的关系链接.
import torch import torch.nn.functional as F # 激励函数都在这 class Net(torch.nn.Module): # 继承 torch 的 Module def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() # 继承 __init__ 功能 # 定义每层用什么样的形式 self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出 self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出 def forward(self, x): # 这同时也是 Module 中的 forward 功能 # 正向传播输入值, 神经网络分析出输出值 x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值) x = self.predict(x) # 输出值 return x net = Net(n_feature=1, n_hidden=10, n_output=1) print(net) # net 的结构 “”” Net ( (hidden): Linear (1 -> 10) (predict): Linear (10 -> 1) ) “””
3.3 训练
import matplotlib.pyplot as plt import torch plt.ion() # 画图 plt.show() # optimizer 是训练的工具 optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, 学习率 loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差) for t in range(100): prediction = net(x) # 喂给 net 训练数据 x, 输出预测值 loss = loss_func(prediction, y) # 计算两者的误差 optimizer.zero_grad() # 清空上一步的残余更新参数值 loss.backward() # 误差反向传播, 计算参数更新值 optimizer.step() # 将参数更新值施加到 net 的 parameters 上 # 接着上面来 if t % 5 == 0: # plot and show learning process plt.cla() plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), prediction.data.numpy(), r-, lw=5) plt.text(0.5, 0, Loss=%.4f % loss.data.numpy(), fontdict={size: 20, color: red}) plt.pause(0.1)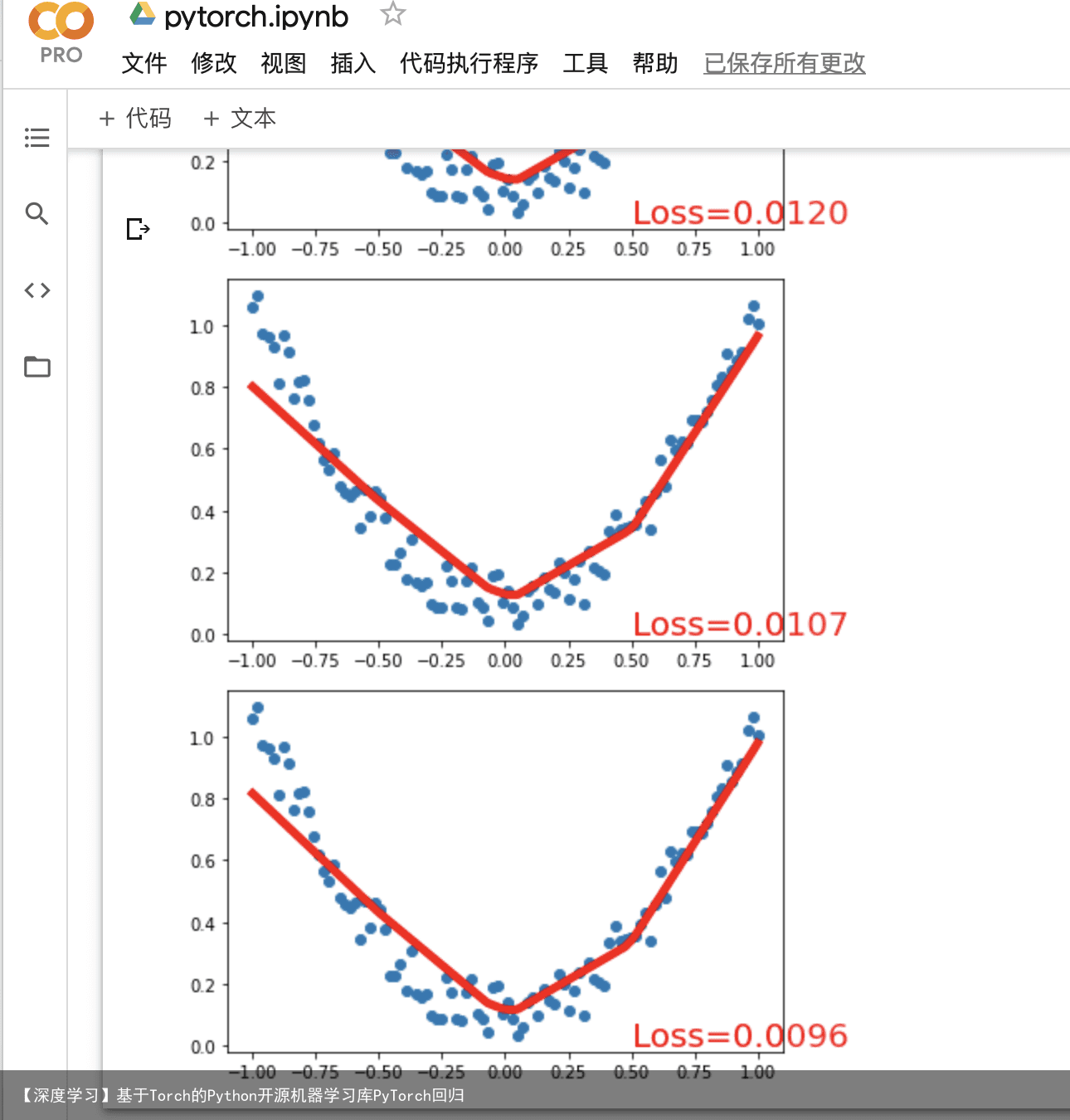
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】基于Torch的Python开源机器学习库PyTorch回归 https://www.yhzz.com.cn/a/11879.html