
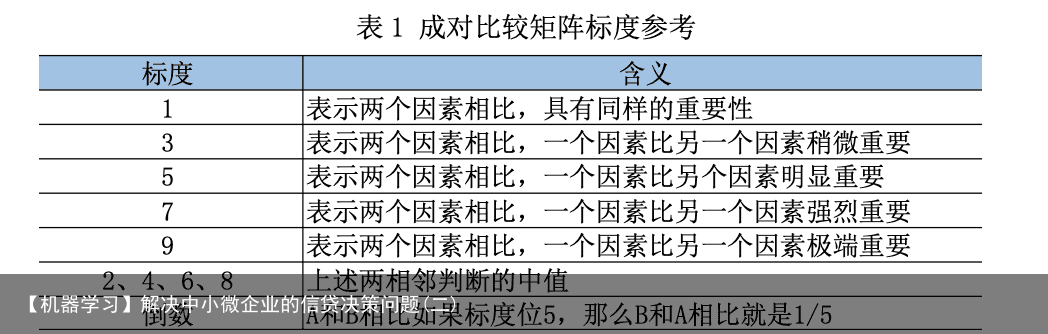
5.1 问题一的模型建立和求解 5.1.1 层次分析法计算各项指标的主观权向量 选定“进项总金额、进项总税额、进项数、销项总金额、进项FP有效率、销项总 税额、销项数、销项FP有效率、信誉评级、是否违约”十个指标为准则层,用层次分 析法求它们的权重,构建层级结构模型。 构造判断矩阵(成对比较矩阵),将 n 个因素 C1,C2,…,Cn 之间两两对比,用 aij 表 示 Ci 和 Cj 的影响之比。比较结果可形成对比较矩阵,矩阵标度方法如下表 1 所示:
 因此我们设比较矩阵:
因此我们设比较矩阵: 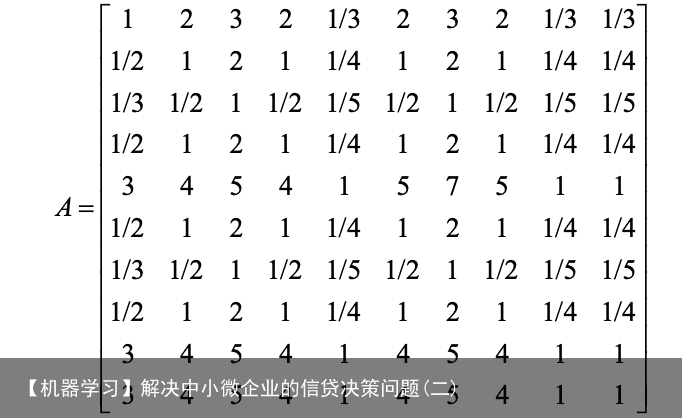 对矩阵 A 进行一致性检验的步骤如下: i) 计算矩阵 A 的最大特征值 lmax 和一致性指标 CI ,其中 n 是矩阵的维数。当 lmax 为 n 时,此判断矩阵就是一致矩阵。 𝐶𝐼 = 𝜆!”# − 𝑛 (1) ii) 根据 n 的大小,对应下表查找平均随机一致性指标 RI 。 表2 RI对照表
对矩阵 A 进行一致性检验的步骤如下: i) 计算矩阵 A 的最大特征值 lmax 和一致性指标 CI ,其中 n 是矩阵的维数。当 lmax 为 n 时,此判断矩阵就是一致矩阵。 𝐶𝐼 = 𝜆!”# − 𝑛 (1) ii) 根据 n 的大小,对应下表查找平均随机一致性指标 RI 。 表2 RI对照表  iii)使用公式(2)计算一致性比率 CR 。 𝐶𝑅 = 𝐶𝐼 (2) iv) 判断 CR 小于 0.1 是否成立,如果成立则认为此判断矩阵的一致性可以使用,否 则需要再次对该比较矩阵修改。最终得出十个指标权重向量为:
iii)使用公式(2)计算一致性比率 CR 。 𝐶𝑅 = 𝐶𝐼 (2) iv) 判断 CR 小于 0.1 是否成立,如果成立则认为此判断矩阵的一致性可以使用,否 则需要再次对该比较矩阵修改。最终得出十个指标权重向量为: 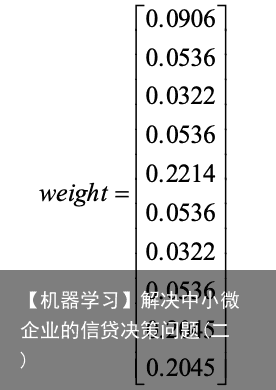 5.1.2 灰色关联分析计算客观权向量 灰色关联分析法对比熵权法的说明: 熵权法是一种客观的赋权的方法,其依据指标的变异程度来分配权值,指标的变异 程度越大,则其指标分配的权值也较高。但就本题选取的指标而言,对于量化之后的“是 否违约”指标,因为其特殊的只存在 0 或者 1 两种数值,因而在连续的相同指标的下反 应不出指标的变异程度,最终使得其指标权重偏低,不利于后期模型的处理。而相比于 灰色关联分析而言,这种情况则可避免。 灰色关联分析依据其序列曲线的几何图形的相似程度来判断其关系是否紧密,曲线 越接近,相应序列之间的关联度就越大。最终求得各种指标的灰色关联度,可依据其大 小反应哪一种指标更加影响总体形状的变化趋势。 灰色关联分析法的求解步骤: 第一步,对指标进行正向化处理。 原始矩阵正向化就是将所有的指标统一转化为极大型指标。十种指标中,“进项总 税额、销项总税额”两种指标对于公司来说是极小型指标,因此需要对其进行正向化处 理,即用 Max-x 方法使得其变为正向化指标。 第二步,对正向化后的矩阵进行预处理。 对矩阵进行预处理是为了消去不同指标量纲的影响,并且缩小变量的范围,便于后 面计算。消除不同量纲的影响。设正向化矩阵为:
5.1.2 灰色关联分析计算客观权向量 灰色关联分析法对比熵权法的说明: 熵权法是一种客观的赋权的方法,其依据指标的变异程度来分配权值,指标的变异 程度越大,则其指标分配的权值也较高。但就本题选取的指标而言,对于量化之后的“是 否违约”指标,因为其特殊的只存在 0 或者 1 两种数值,因而在连续的相同指标的下反 应不出指标的变异程度,最终使得其指标权重偏低,不利于后期模型的处理。而相比于 灰色关联分析而言,这种情况则可避免。 灰色关联分析依据其序列曲线的几何图形的相似程度来判断其关系是否紧密,曲线 越接近,相应序列之间的关联度就越大。最终求得各种指标的灰色关联度,可依据其大 小反应哪一种指标更加影响总体形状的变化趋势。 灰色关联分析法的求解步骤: 第一步,对指标进行正向化处理。 原始矩阵正向化就是将所有的指标统一转化为极大型指标。十种指标中,“进项总 税额、销项总税额”两种指标对于公司来说是极小型指标,因此需要对其进行正向化处 理,即用 Max-x 方法使得其变为正向化指标。 第二步,对正向化后的矩阵进行预处理。 对矩阵进行预处理是为了消去不同指标量纲的影响,并且缩小变量的范围,便于后 面计算。消除不同量纲的影响。设正向化矩阵为:  设标准化矩阵为 Z,Z 中元素记为 zij :
设标准化矩阵为 Z,Z 中元素记为 zij :  得到标准化矩阵 Z:
得到标准化矩阵 Z:  第三步,构造母序列和子序列。 母序列,又称参考数列,其是能反映系统特征的数据序列。子序列,又称比较数列, 其是影响系统行为因素组成的数据序列。这里设母序列为 x0,子序列为(x1 x2 。xn),将 预处理得到的矩阵 Z 每一行取出最大值构成母序列,其余的数据则设为子序列。 第四步,计算各个指标与母序列的灰色关联度。 首先需要计算两极最小差与两极最大差,这里用 a,b 表示:
第三步,构造母序列和子序列。 母序列,又称参考数列,其是能反映系统特征的数据序列。子序列,又称比较数列, 其是影响系统行为因素组成的数据序列。这里设母序列为 x0,子序列为(x1 x2 。xn),将 预处理得到的矩阵 Z 每一行取出最大值构成母序列,其余的数据则设为子序列。 第四步,计算各个指标与母序列的灰色关联度。 首先需要计算两极最小差与两极最大差,这里用 a,b 表示:
 TOPSIS 法别名优劣解距离法,其主要利用数据的信息,精确的反应评价方案之间 的优劣差距。TOPSIS 法多用于解决多指标的决策性问题,其实现原理为通过计算各备 选方案与正负理想解之间的相对距离来进行排序并做出选择。 第一步,原始矩阵正向化。 原始矩阵正向化就是将所有的指标统一转化为极大型指标。十种指标中,“进项总 税额、销项总税额”两种指标对于公司来说是极小型指标,其余指标都是极大型指标, 因此需要对其进行正向化处理,即用 Max-x[10]方法使得其变为正向化指标。
TOPSIS 法别名优劣解距离法,其主要利用数据的信息,精确的反应评价方案之间 的优劣差距。TOPSIS 法多用于解决多指标的决策性问题,其实现原理为通过计算各备 选方案与正负理想解之间的相对距离来进行排序并做出选择。 第一步,原始矩阵正向化。 原始矩阵正向化就是将所有的指标统一转化为极大型指标。十种指标中,“进项总 税额、销项总税额”两种指标对于公司来说是极小型指标,其余指标都是极大型指标, 因此需要对其进行正向化处理,即用 Max-x[10]方法使得其变为正向化指标。
 表 3 信贷风险模型评估表
表 3 信贷风险模型评估表 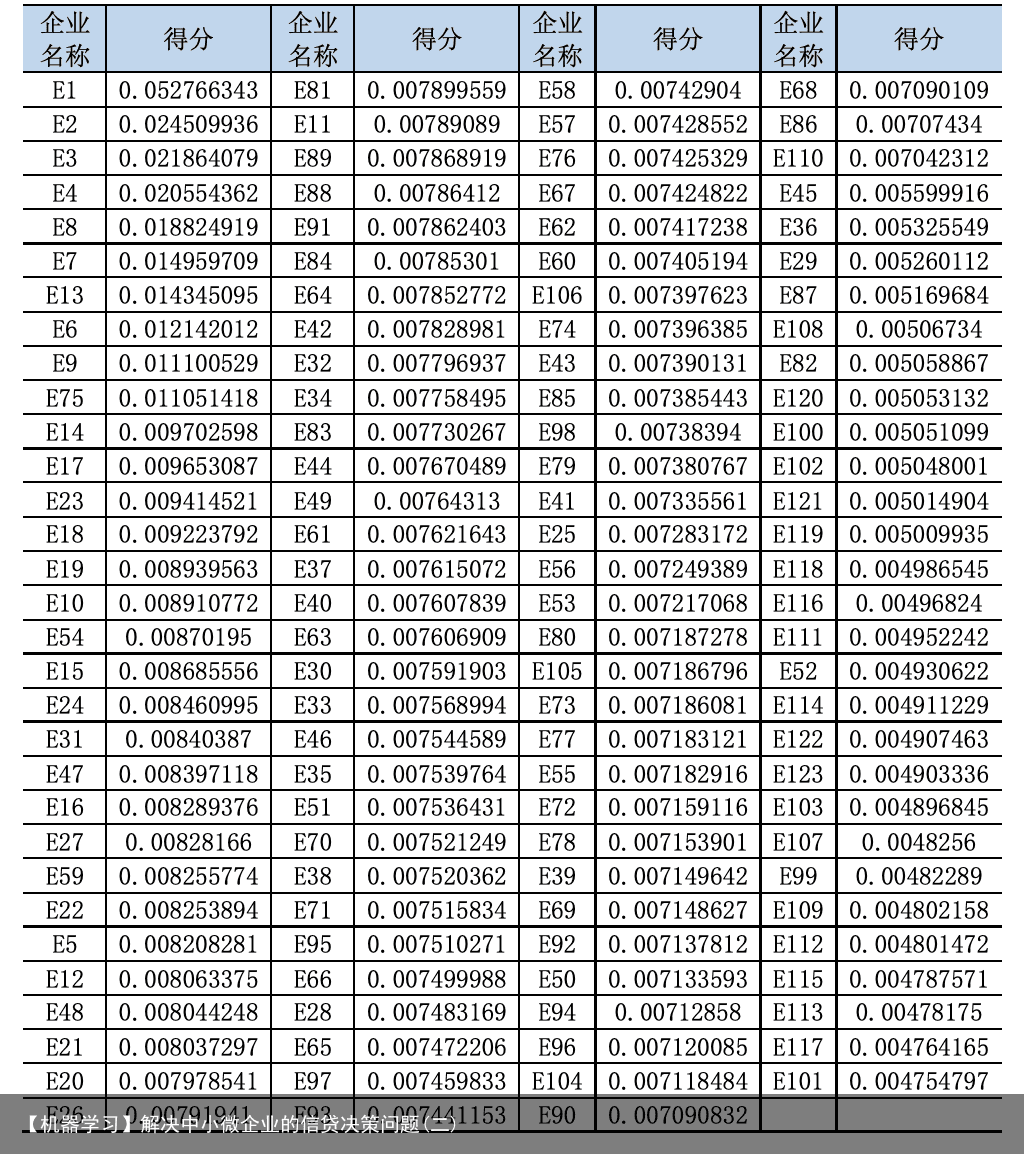 K-Means 是比较常用的聚类模型[11],它的主要思想是为在指定 K 值和 K 个初始类 簇中心点的条件下,将每个数据分配到离其最近的簇中心点所在的类中,当所有数据点 都分配完毕之后,根据一个类簇内的所有数据点取均值重新计算该类簇的中心点,然后 反复迭代此过程,直至类簇数据中心点的变化很小或者达到指定的迭代次数才停止算法。 假设给定数据样本 X,其中包含了 n 个对象 X={X1,X2,X3,…,Xn},每个数据项维度 都为 m,首先需要初始化任意个数的聚类中心{C1,C2,C3,…,Ck},1<k≤n,本文指定 k=5, 使用欧式距离作为分类判别指标,如公式(14)所示。
K-Means 是比较常用的聚类模型[11],它的主要思想是为在指定 K 值和 K 个初始类 簇中心点的条件下,将每个数据分配到离其最近的簇中心点所在的类中,当所有数据点 都分配完毕之后,根据一个类簇内的所有数据点取均值重新计算该类簇的中心点,然后 反复迭代此过程,直至类簇数据中心点的变化很小或者达到指定的迭代次数才停止算法。 假设给定数据样本 X,其中包含了 n 个对象 X={X1,X2,X3,…,Xn},每个数据项维度 都为 m,首先需要初始化任意个数的聚类中心{C1,C2,C3,…,Ck},1<k≤n,本文指定 k=5, 使用欧式距离作为分类判别指标,如公式(14)所示。

考虑到 K-Means 算法对初值和孤立点数据敏感的特点,本文使用了 K-Means++模 型对企业进行信贷风险等级划分。K-Means++算法选择初始聚类中心的基本原则是初始 的聚类中心之间的相互距离要尽可能的远。算法描述如下,流程图如图 3 所示。 (1)随机选取一个样本作为第一个聚类中心。 (2)计算每个样本与当前已有聚类中心的最短距离,这个值越大,表示被选取作为 聚类中心的概率较大,最后用轮盘法选出下一个聚类中心。 (3)重复步骤(2),直到选出 K 个聚类中心,选出初始点后,继续使用标准的 K- Means 算法。 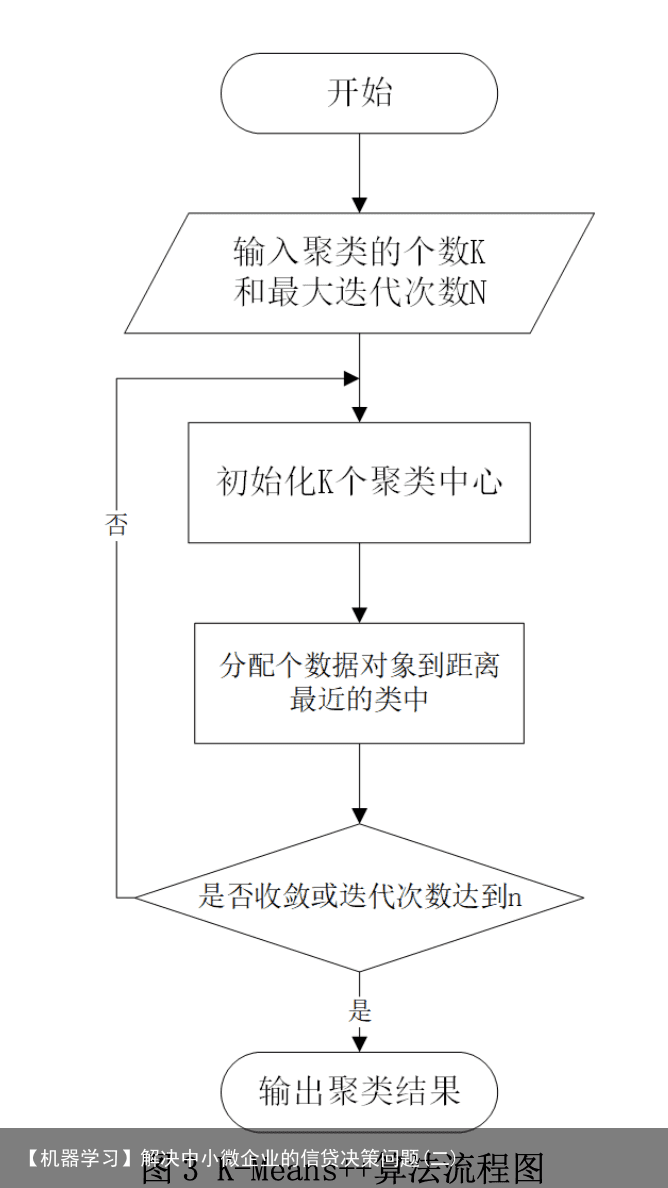
 5.1.5 信贷策略制定 是否放贷决策:构建好信贷风险评估模型后,本文将 123 家企业的信贷风险划分为 五个等级从 A-E,银行对于 E 等级的企业原则上不予放贷,应该优先DK给风险低信誉 评级高的企业。 DK配额决策:对于 A-D 等级的企业,银行会根据 TOPSIS 模型求出的打分[12]情 况,按照正比例关系,合理的分配10~100万元的DK额度。 DK利率设定:根据附件 3 种的数据,银行对不同信誉等级的企业会给予不同大小 的年利率,以保证获取最大收益的同时,客户流失率最低。 5.2 问题二的模型建立和求解 5.2.1 支持向量机可视化 由于附件2种的302家企业没有信贷记录,需要根据其中的sheet2和sheet3分析出 企业的信誉情况,所以使用了支持向量机模型进行预测分析。支持向量机[13](Support Vector Machines)是一种监督学习算法,实现步骤如下: (1)寻找最大分类间距 考虑条件最优化问题,制定的目标规划如下所示。
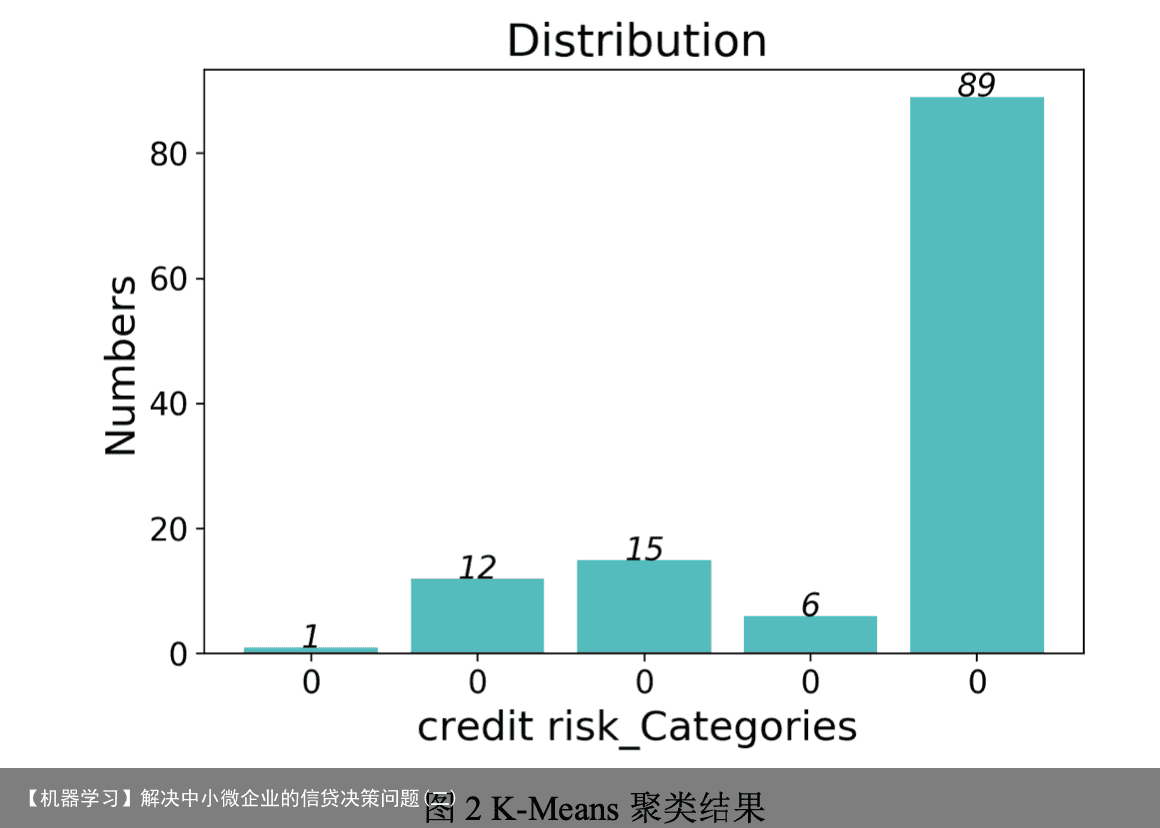
5.1.5 信贷策略制定 是否放贷决策:构建好信贷风险评估模型后,本文将 123 家企业的信贷风险划分为 五个等级从 A-E,银行对于 E 等级的企业原则上不予放贷,应该优先DK给风险低信誉 评级高的企业。 DK配额决策:对于 A-D 等级的企业,银行会根据 TOPSIS 模型求出的打分[12]情 况,按照正比例关系,合理的分配10~100万元的DK额度。 DK利率设定:根据附件 3 种的数据,银行对不同信誉等级的企业会给予不同大小 的年利率,以保证获取最大收益的同时,客户流失率最低。 5.2 问题二的模型建立和求解 5.2.1 支持向量机可视化 由于附件2种的302家企业没有信贷记录,需要根据其中的sheet2和sheet3分析出 企业的信誉情况,所以使用了支持向量机模型进行预测分析。支持向量机[13](Support Vector Machines)是一种监督学习算法,实现步骤如下: (1)寻找最大分类间距 考虑条件最优化问题,制定的目标规划如下所示。 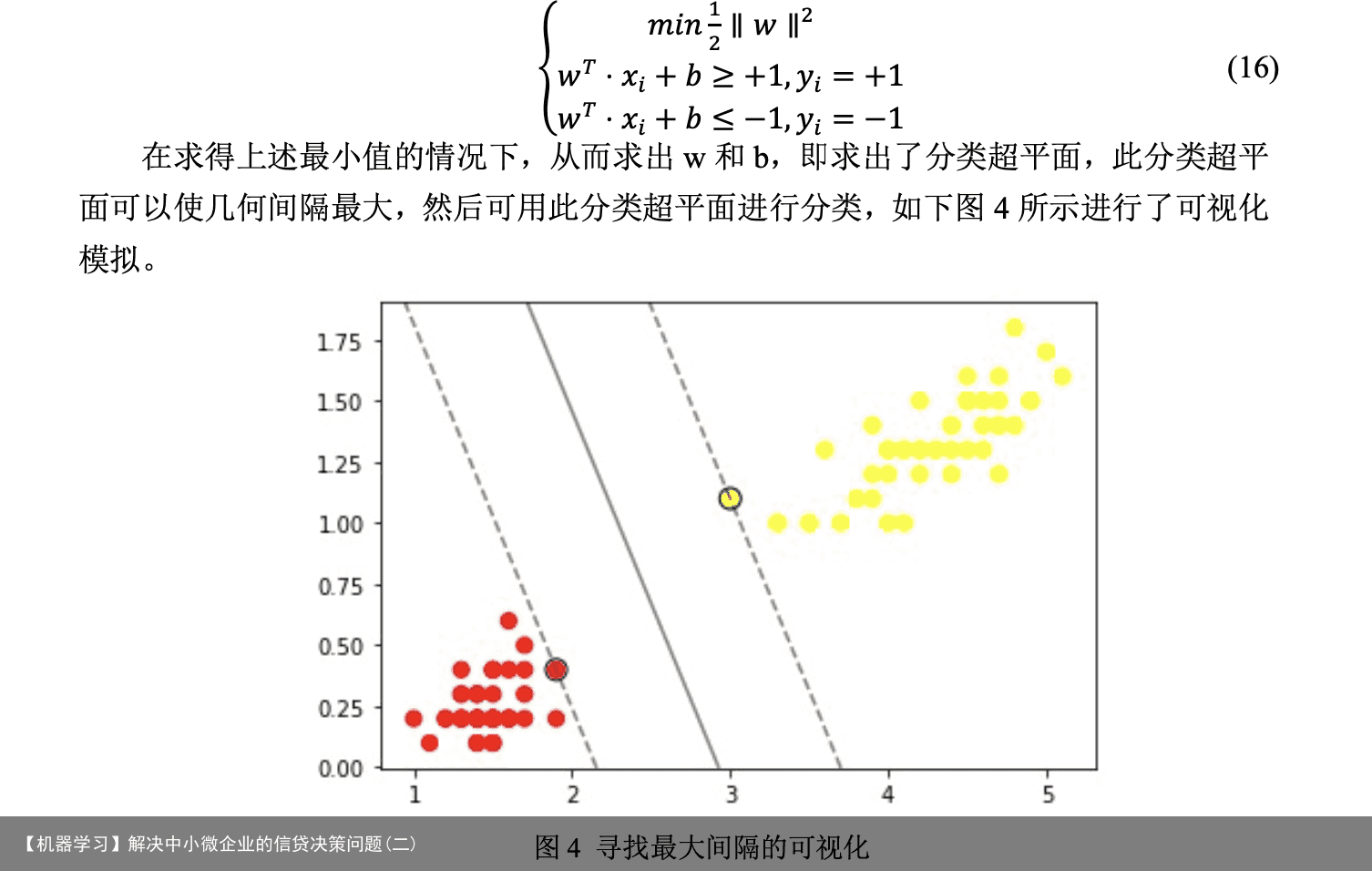 (2)核函数(kernel)[14]使用 该模型对于线性可分的情况效果明显,而对于非线性的情况就需要用到一种叫添加 核函数(kernel)的方法将数据转化为二分类器易于理解的形式。如下图 5 所示进行了可视 化模拟。
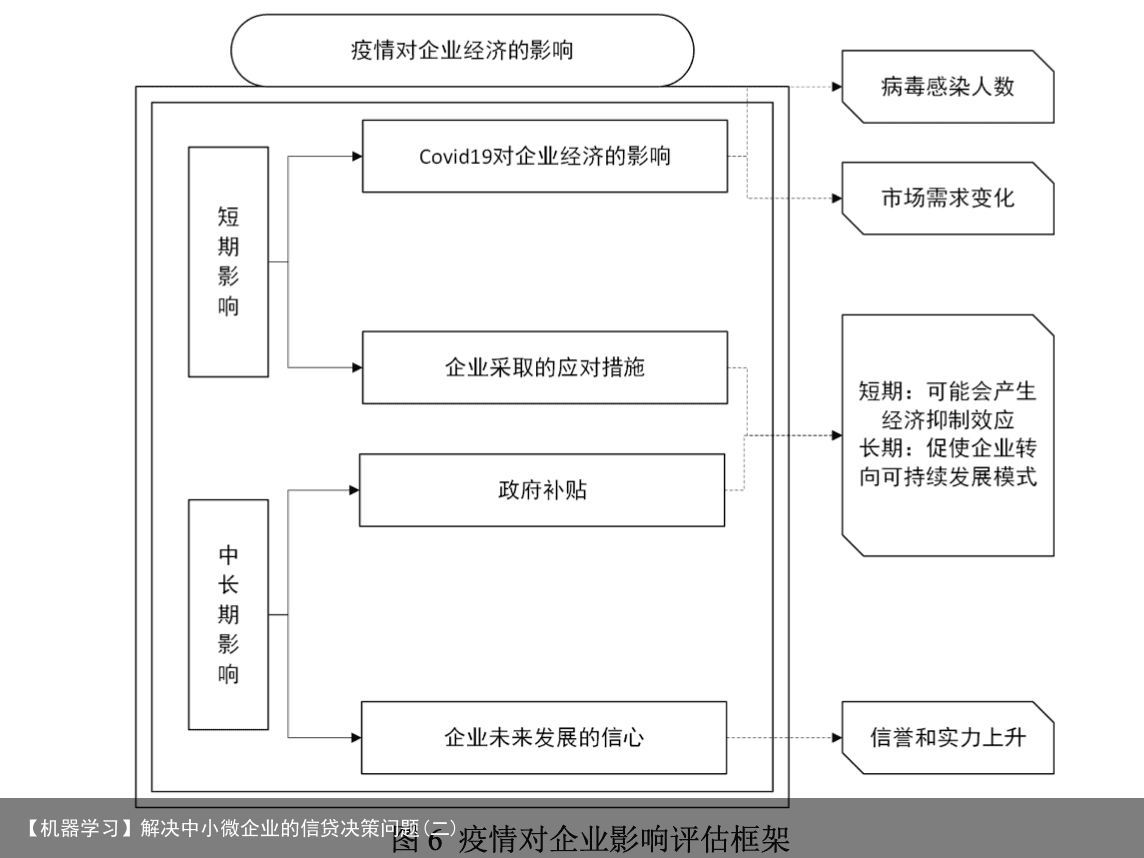
(2)核函数(kernel)[14]使用 该模型对于线性可分的情况效果明显,而对于非线性的情况就需要用到一种叫添加 核函数(kernel)的方法将数据转化为二分类器易于理解的形式。如下图 5 所示进行了可视 化模拟。 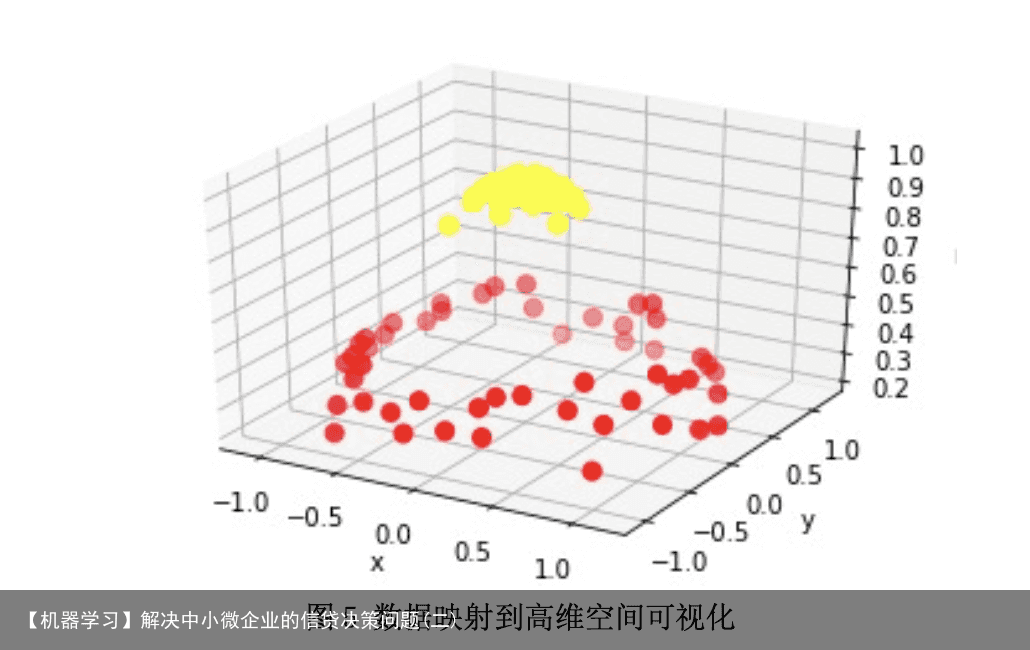 5.3 问题三的模型建立和求解 E374 289739.9604 E424 289640.0516 E397 289302.0408 E376 289254.3822 E317 289124.9761 E353 288576.3129 E384 288064.5276 E360 287564.6004 E386 287373.6242 E288 287371.0905 E413 287188.611 E371 285805.7563 E408 285483.5149 E395 284988.774 E336 284856.3302 E399 284078.2653 E414 283665.5139 E286 282941.4937 E406 282233.0786 E401 280766.5762 E407 276395.1691 E411 275187.4236 E368 274112.0419 E377 273643.525 E240 273439.8227 E394 271385.2446 E264 270552.2999 E217 267896.0961 E425 266457.7885 E385 257897.9216 E242 253234.481 企业的生产经营和经济效益可能会受到一些突发因素影响(例如:新冠病毒疫情), 本文搜集各大行业经济变化数据、政府补贴数据等用来完善评估信贷策略模型。分析疫 情前后中国的中小微企业经济数据的变化,判断不同类型企业对突发情况的处理机制, 建立新冠肺炎疫情对中小微企业影响评估框架,对信贷风险评估模型和信贷策略加以修 正。评估框架如下图 6 所示。
5.3 问题三的模型建立和求解 E374 289739.9604 E424 289640.0516 E397 289302.0408 E376 289254.3822 E317 289124.9761 E353 288576.3129 E384 288064.5276 E360 287564.6004 E386 287373.6242 E288 287371.0905 E413 287188.611 E371 285805.7563 E408 285483.5149 E395 284988.774 E336 284856.3302 E399 284078.2653 E414 283665.5139 E286 282941.4937 E406 282233.0786 E401 280766.5762 E407 276395.1691 E411 275187.4236 E368 274112.0419 E377 273643.525 E240 273439.8227 E394 271385.2446 E264 270552.2999 E217 267896.0961 E425 266457.7885 E385 257897.9216 E242 253234.481 企业的生产经营和经济效益可能会受到一些突发因素影响(例如:新冠病毒疫情), 本文搜集各大行业经济变化数据、政府补贴数据等用来完善评估信贷策略模型。分析疫 情前后中国的中小微企业经济数据的变化,判断不同类型企业对突发情况的处理机制, 建立新冠肺炎疫情对中小微企业影响评估框架,对信贷风险评估模型和信贷策略加以修 正。评估框架如下图 6 所示。
[1] 闫瑞欣. 普惠金融背景下如何解决小微企业融资难问题[D].河北金融学院,2019. [2] 房斌. P 银行小微企业信贷风险评价体系研究[D].西安石油大学,2020. [3] 胡倩倩.大数据征信建设与中小微企业信贷能力的关系研究[D].浙江工业大学,2020. [4] 王利利,贾梦雨,韩松,李锰,刘巍.基于 TOPSIS—灰色关联度的农WT资效益与风险能 力综合评价[J].电力科学与技术学报,2020,35(04):76-83. [5] 龚超,刘春雨,薄云鹊,林春光,张昱,石柱峰,杨文秀.基于 AHP 和灰色关联分析的家庭 医生签约服务质量评价[J].中国初级卫生保健,2020,34(06):7-11. [6] [7] 王坤,侯树贤,王力.基于自适应变异PSO-SVM的APU性能参数预测模型[J/OL].系统 工程与电子技术:1-14[2020-09- 13].http://kns.cnki.net/kcms/detail/11.24 22.TN.202009 11.1449.002.html. [8] 赵慧琴,石立,刘金山,林海明.SPSS 软件计算主成分分析的缺陷与纠正[J].统计与决 策,2020,36(15):56-59. 包婉莹,罗小玲,潘新. Improved Hybrid Clustering Algorithm Based on Artificial Bee Colony Algorithm and K-Means Algorithm. 2020, 09(02):92-99. 李慧勇. 疫情影响有限 多数行业明显回暖可期[N]. 中国证券报,2020-02-17(A03). Shiwang Ma,Lixia Wang. Bounded and Unbounded Motions in Asymmetric Oscillators at Resonance[J]. Journal of Dynamics and Differential Equations,2013,25(4). Jayasree Saha,Jayanta Mukherjee. CNAK : Cluster number assisted K-means[J]. Pattern Recognition,2021,110. Zhang Kaize,Shen Juqin,Han Han,Zhang Jinglai. Study of the Allocation of Regional Flood Drainage Rights in Watershed Based on Entropy Weight TOPSIS Model: A Case Study of the Jiangsu Section of the Huaihe River, China.[J]. International journal of environmental research and public health,2020,17(14). 柳丽娜. 基于非平行支持向量机的三种分类算法[D].重庆师范大学,2019. Saburou Saitoh. Integral Transforms, Reproducing Kernels and Their Applications [M].CRC Press:2020-09-11.
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【机器学习】解决中小微企业的信贷决策问题(二) https://www.yhzz.com.cn/a/11869.html