
要介绍PyTorch之前,不得不说一下Torch。Torch是一个有大量机器学习算法支持的科学计算框架,是一个与Numpy类似的张量(Tensor) 操作库,其特点是特别灵活,但因其采用了小众的编程语言是Lua,所以流行度不高,这也就有了PyTorch的出现。所以其实Torch是 PyTorch的前身,它们的底层语言相同,只是使用了不同的上层包装语言。
 PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。 PyTorch提供了两个高级功能:
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。 PyTorch提供了两个高级功能:
具有强大的GPU加速的张量计算(如Numpy)
包含自动求导系统的深度神经网络
除了Facebook之外,Twitter、GMU和Salesforce等机构都采用了PyTorch。TensorFlow和Caffe都是命令式的编程语言,而且是静态的,首先必须构建一个神经网络,然后一次又一次使用相同的结构,如果想要改 变网络的结构,就必须从头开始。但是对于PyTorch,通过反向求导技术,可以让你零延迟地任意改变神经网络的行为,而且其实现速度 快。正是这一灵活性是PyTorch对比TensorFlow的最大优势。
另外,PyTorch的代码对比TensorFlow而言,更加简洁直观,底层代码也更容易看懂,这对于使用它的人来说理解底层肯定是一件令人激 动的事。
所以,总结一下PyTorch的优点:
支持GPU 灵活,支持动态神经网络 底层代码易于理解 命令式体验 自定义扩展当然,现今任何一个深度学习框架都有其缺点,PyTorch也不例外,对比TensorFlow,其全面性处于劣势,目前PyTorch还不支持快速傅里 叶、沿维翻转张量和检查无穷与非数值张量;针对移动端、嵌入式部署以及高性能服务器端的部署其性能表现有待提升;其次因为这个框 架较新,使得他的社区没有那么强大,在文档方面其C库大多数没有文档。
2 环境搭建我在学习中一般使用colab,建议大家和我一样。如下图
这里我就不多说了,很简单。
网上有其他教程。
 3 Hello world!
3 Hello world!
PyTorch 是一个基于 Python 的科学计算包,主要定位两类人群:
NumPy 的替代品,可以利用 GPU 的性能进行计算。
深度学习研究平台拥有足够的灵活性和速度3.1 Tensors (张量)
Tensors 类似于 NumPy 的 ndarrays ,同时 Tensors 可以使用 GPU 进行计算。
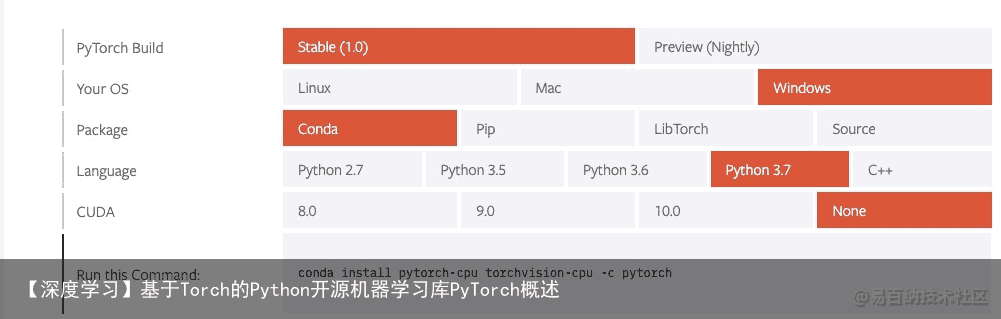
from __future__ import print_function import torch构造一个5×3矩阵,不初始化。
x = torch.empty(5, 3) print(x)构造一个随机初始化的矩阵:
x = torch.rand(5, 3) print(x)构造一个矩阵全为 0,而且数据类型是 long.
Construct a matrix filled zeros and of dtype long:
x = torch.zeros(5, 3, dtype=torch.long) print(x)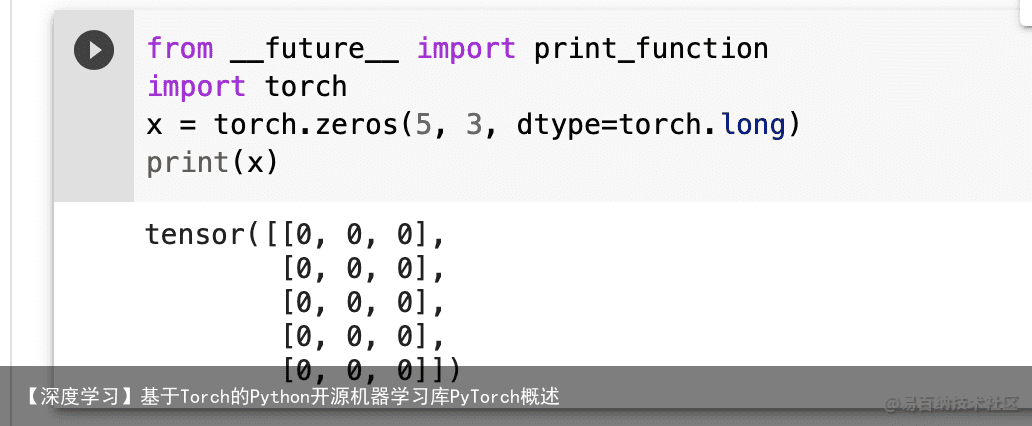 构造一个张量,直接使用数据:
构造一个张量,直接使用数据:
创建一个 tensor 基于已经存在的 tensor。
x = x.new_ones(5, 3, dtype=torch.double) # new_* methods take in sizes print(x) x = torch.randn_like(x, dtype=torch.float) # override dtype! print(x) # result has the same size输出:
tensor([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]], dtype=torch.float64)
tensor([[-0.2183, 0.4477, -0.4053],
[ 1.7353, -0.0048, 1.2177],
[-1.1111, 1.0878, 0.9722],
[-0.7771, -0.2174, 0.0412],
[-2.1750, 1.3609, -0.3322]])
获取它的维度信息: print(x.size())输出:
torch.Size([5, 3])
注意torch.Size 是一个元组,所以它支持左右的元组操作。
3.2 操作
在接下来的例子中,我们将会看到加法操作。
加法: 方式 1 y = torch.rand(5, 3) print(x + y)Out:
tensor([[-0.1859, 1.3970, 0.5236],
[ 2.3854, 0.0707, 2.1970],
[-0.3587, 1.2359, 1.8951],
[-0.1189, -0.1376, 0.4647],
[-1.8968, 2.0164, 0.1092]])
加法: 方式2 print(torch.add(x, y))Out:
tensor([[-0.1859, 1.3970, 0.5236],
[ 2.3854, 0.0707, 2.1970],
[-0.3587, 1.2359, 1.8951],
[-0.1189, -0.1376, 0.4647],
[-1.8968, 2.0164, 0.1092]])加法: 提供一个输出 tensor 作为参数
result = torch.empty(5, 3) torch.add(x, y, out=result) print(result)加法: in-place
# adds x to y y.add_(x) print(y) 4 GPU Tensor新建的Tensor对象默认存在于CPU内存中,在使用GPU进行计算的时候,只需要把Tensor拷贝到GPU memory中即可。第一种方法是使用cuda()函数:
x = x.cuda()在使用cuda()的时候,如果机器没有检测到可用的GPU,会报错。自从PyTorch 0.4以来,一个新的函数to()被引入,所以现在的标准代码都会这样写:
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)x = x.to(device)这两行代码的意思是,如果检测到可用的GPU,就把x拷贝到GPU上,否则,x依旧保留在CPU内存中。这样避免了运行错误,在任何情况下程序都可以顺利执行。
5 前向传播与反向传播在Tensorflow中,一组操作符构建了一个计算图,这个计算图固定的存储在了内存中。当你给placeholder放入具体数据的时候,计算图执行运算,更新参数。
这个过程相当于:你想吃面条,那么第一步你做了一个面条机,这个面条机一直在那里,不管你有没有面;当你有面了,把面扔进去,调节面条机的刀片(参数),做出你需要的面条来。
这个优点是建造面条机和做面条分开,你可以集中精力去设计一个很棒的面条机;缺点是当你做好了面条机,发现你的某个要求它达不到,你需要重做一个(重写一个网络)。
在PyTorch中,由于“所见即所得”,所以每一步运算都是在计算图上添砖加瓦。所谓的“动态”也就在这里,你可以随时增加一行代码,计算图就成了一个新的样子。
这个可以类比成造房子(主页菌想象力匮乏,大家凑合看……)你先建了一个平房,住了一段时间觉得不够用了,你不需要推翻重建,而是可以在上面直接加一层。第一层的房顶就是你盖第二层时候的“基础”(前端计算图的输出直接作为新的操作符的输入)。
所以在PyTorch中运行一个模型的时候,过程是这样的:
你:我想前向传播,这是数据
计算机:好的,构建计算图,计算结果,存储中间数据用于计算梯度
你:我想执行反向传播
计算机:好的,梯度计算完成,释放不再需要的中间数据和计算图,存储更新参数。
你:执行第二次前向传播
计算机:好的,重新构建计算图,计算结果,存储中间数据……
…… ……
你:训练好了,我想测试,开启测试模式,这是测试数据
计算机:构建计算图,前向传播计算输出,不存储中间结果,因为不需要计算梯度
存储中间数据计算梯度这个概念很重要哦。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】基于Torch的Python开源机器学习库PyTorch概述 https://www.yhzz.com.cn/a/11832.html