
MTCNN 可以并行训练(3 个网络同时训练,前提是内存够大)损失函数:cls 置信度输出函数为 Sigmoid 并且是判断是否存在人脸的分类问题,所以使用 BCELoss(二分类交叉熵损失函数)offset 偏移量为回归候选框的左边点的偏移 量使用的是 MSELoss(均方差损失函数)。
优化器:都使用的是 Adam
cls 置信度是使用的网络输出中索引属于正样本和负样本的数据进行回归 的。
offset 偏移量是使用的网络输出中索引属于正样本和部分样本的数据进行 回归的。
PNet 训练停止损失值为 0.01,RNet 训练停止损失值为 0.001,ONet 训练停 止损失值为 0.0005。工具 图像 IOU(图像重合度): 候选框有以下几种情况:
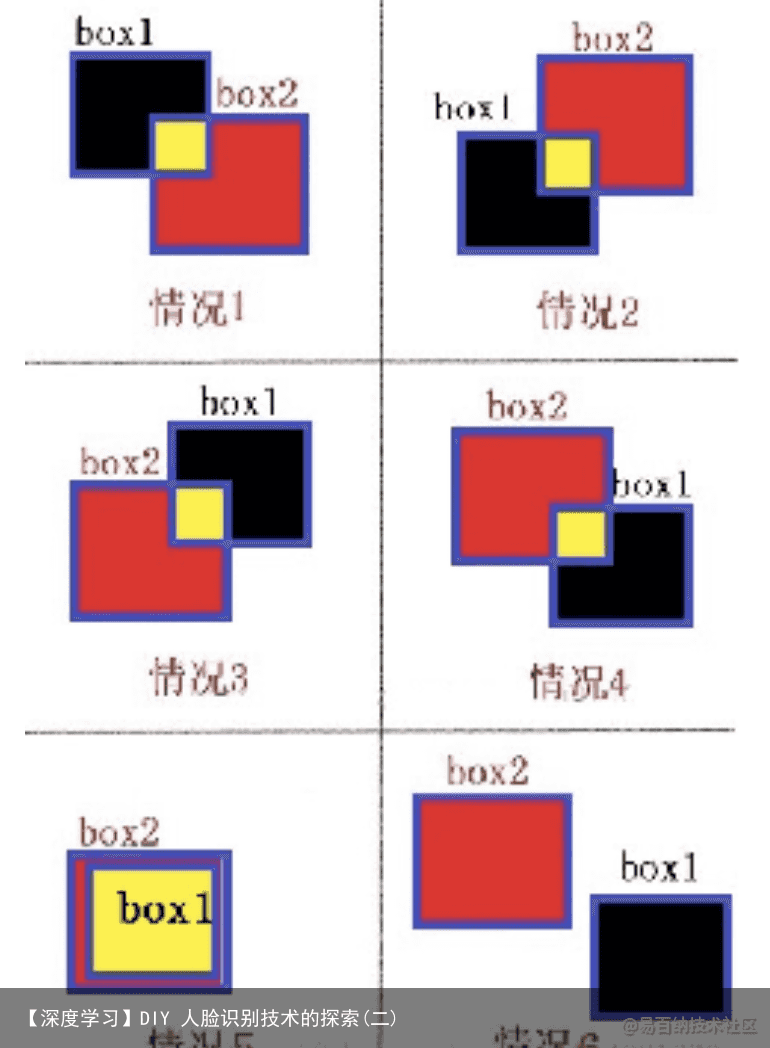
图 8 前 4 种情况为两个候选框相交,第 5 种情况为大框套小框,第 6 种情况
为两个候选框分离(这种很有可能两个框都是人脸框) IOU 为重合程度,计算方法有两种如图 9
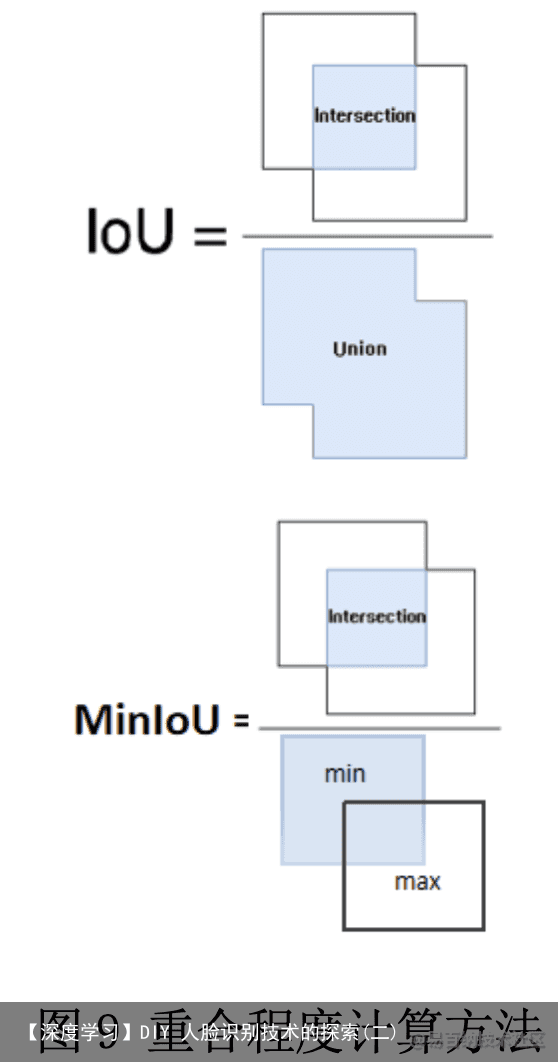
第一种为交并比 IOU(交集面积/并集面积)。先找到交集,从图 1 第一种情
况可以看出 交集框 x1,y1 为两个框 x1,y1 的最大值,交集框 x2,y2 为两个框 x2,y2 的最小值。
交集面积 = (min(x2,x2) – max(x1,x1)) * (min(y2,y2) – max(y1,y1)) 并集面积 = 两个框的面积和 – 交集面积
第二种为最小集 IOU(交集面积/最小框面积)。这种是计算方法是因为获取 的所有候选框中,有大框套小框的存在,并且小框远小于大框(如上图),这样 使用交并比 IOU 是无法去除非人脸框的,这是就只能用最小集 IOU,因为大框套 小框交集面积=最小集面积所以 IOU=1,这种是可以将不合适的框滤除掉的。这 种 IOU 计算方法只有 O 网络用到。 NMS(非极大值抑制):
NMS 顾名思义是留下值大的,抑制(丢弃)值小的,而这个值在 MTCNN 中指 的是 cls 置信度。如图 10 中有多个框框在同一张人脸上,本文需要去除多余的 框。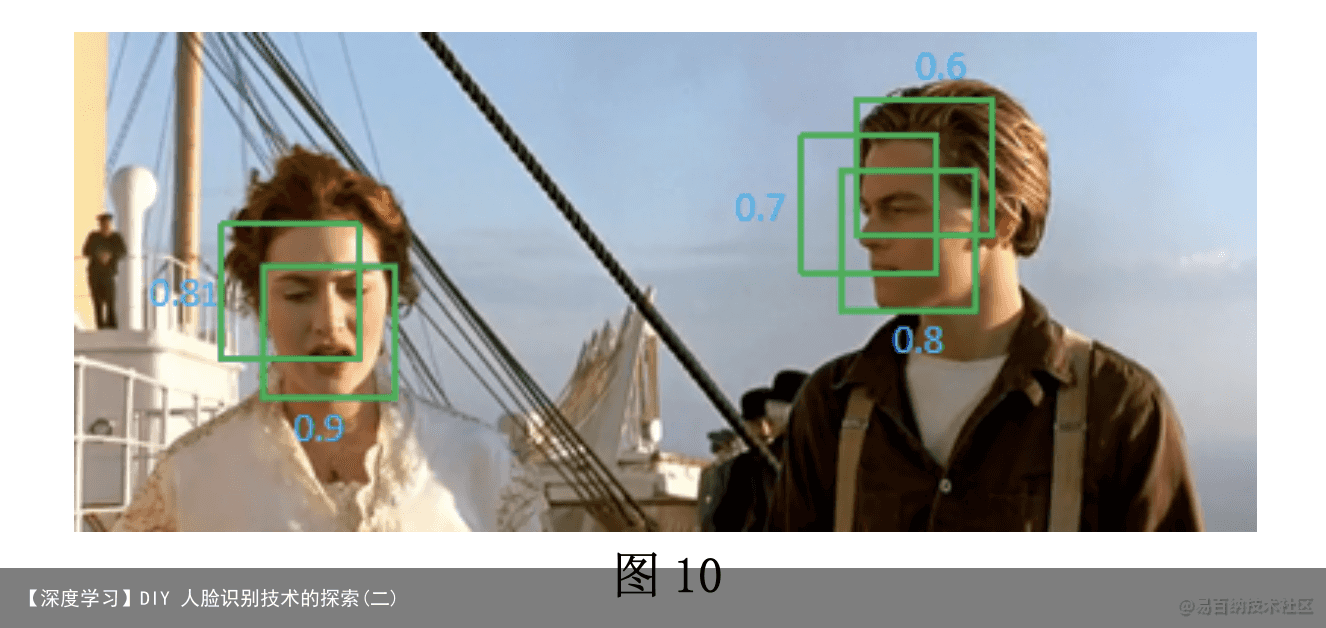
去重方法如此图,先按照 cls 置信度将所有候选框的数据排序(从大到
小),第一个框(也就是置信度最大的框)一定为人脸框需要保留存为预测 框,剩下的框依次和第一个框做 IOU,若重合度高于阈值则丢弃,低于阈值说 明可能是另一个人脸的框所以保留。重复上述操作直到候选框中只剩下一个框 或者没有框,若只剩下一个说明此框可能是人脸框也保留存储在预测框中 NMS

图像坐标正方形转换
此工具在侦测时 RNet 和 ONet 之前使用,目的是因为 PNet 和 RNet 输出的框 大可能是长方形的,但是 RNet 和 ONet 传入的是 2424 和 4848 固定的正方形, 如果直接变形会导致人脸特征扭曲变形,不利于侦测,所以需要在变形之前转换 成正方形。

图13
如图 13,如果直接传入长方形会少一部分特征,而且 RNet 和 ONet 需求是固定 size 的正方形;如果直接 resize 会使脸部特征扭曲变形不利于侦测;如果放入 黑色正方形背景中特征不全会影响侦测结果;最好的办法是在原图上变成正方形 再 resize。变形方法:计算长方形框的最大边长 max_side,然后在计算正方形
的 x1,y1,x2,y2
图像坐标反算
图像坐标反算每个 Net 都要进行,但是 PNet 不同,因为在传入 PNet 之前做 了图像金字塔如果要反算回原图就要/scale(缩放比率)如上图:可以看到左边为 原图,框为建议框,右边为输出的结果(N,5,h,w)的结果,先筛选出置信度大于 阈值的框(PNet 使用的是 index = torch.nonzero(torch.gt(cls, 0.5))方法, RNet 和 ONet 使用的是 index,_ = np.where(cls>0.6)方法)。
先反算建议框:
而 RNet 和 ONet 都是直接输入的建议框,所以不需要反算建议框,直接反算 预测框。
 结果展示
结果展示


5.2.1 基于问题一的 Haar 强级联分类模型的问题二求解
问题二是在问题一求解后的基础上,建立人脸精确识别模型。区别于问题一 中只用矩形标出图片中人脸的位置,问题二的目标是在输入的图像中不仅标出人 脸的位置,还能标出人的眼睛、嘴巴和鼻子。问题二是在标记出人脸的位置的基 础上继续寻找眼睛、鼻子和嘴巴的位置。OpenCV 配有训练器和探测器。在级联 分类器将处理检测。OpenCV 已包含许多预先训练的面部,眼睛,微笑等分类器。 这些 XML 文件存储在 opencv/data/haarcascades/文件夹中。运行时可用 OpenCV 导入面部和五官 Haar 特征分类器。首先,我们需要加载所需的 XML 分类器和 待检测的图像,然后灰度化以及一系列图像处理输入图像进特征分类器提取特 征,最后框出提取的特征区域。
5.2.2 基于问题一模型在问题二的补充
问题二是基于问题一 MTCNN 模型识别的脸部图片,进行 Haar 的特征分 类。而 OpenCV 中训练好的的 haarcascades 分类器文件内拥有对于眼睛,鼻子, 嘴巴的 Haar 特征分类器,所以和问题一解决方法一致。5.2.3 五官位置比例模型
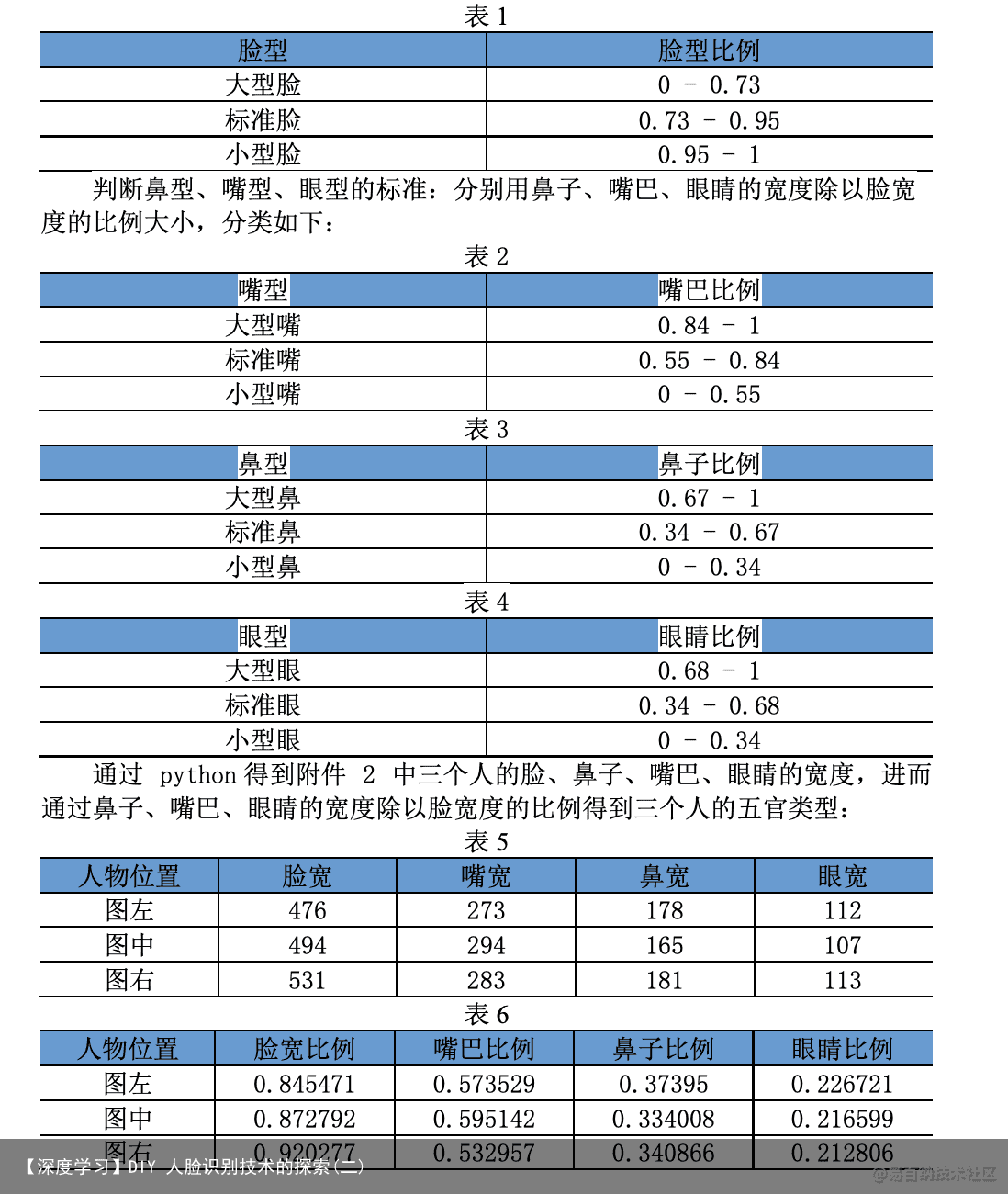
基于 Haar 特征分类器提取出的特征宽度,特征即人脸、眼睛、鼻子和嘴巴。 本文 利用 Python 的 size 函数运行得出五官的数据。判断脸型的标准:通过计 算眼睛、鼻子 和嘴巴的宽度和的比人脸的长度得到的比例大小,分类如下:图 8 眼睛 Haar 特征提取实现方式。
i)导入库 importcv2,获取训练好的人脸的参数数据
ii)引入并读取图片
iii)灰度化
iv)调用 Haar 脸部特征分类器 haarcascade_frontalface_alt2.xml,设置分类器的参数,以及目标检测迭代次 数(迭代次数的不同会直接影响特征提取结果),来检测图片中的人脸特征。 v)在检测到的人脸特征图上继续调用 Haar 眼部特征分类器 haarcascade_eye.xml,
Haar 鼻 部 特 征 分 类 器 haarcascade_mcs_nose.xml ,
Haar 嘴 部 特 征 分 类 器 haarcascade_mcs_mouth.xml,
通过 xxx_cascade.detectMultiScale()函数实现五官特征值位置提取。
vi) 人脸提取并标注,在原始图片上分别以人脸、眼睛、鼻子和嘴巴作为坐标 原点用合适的矩形标出标记的高度
vii) 显示图片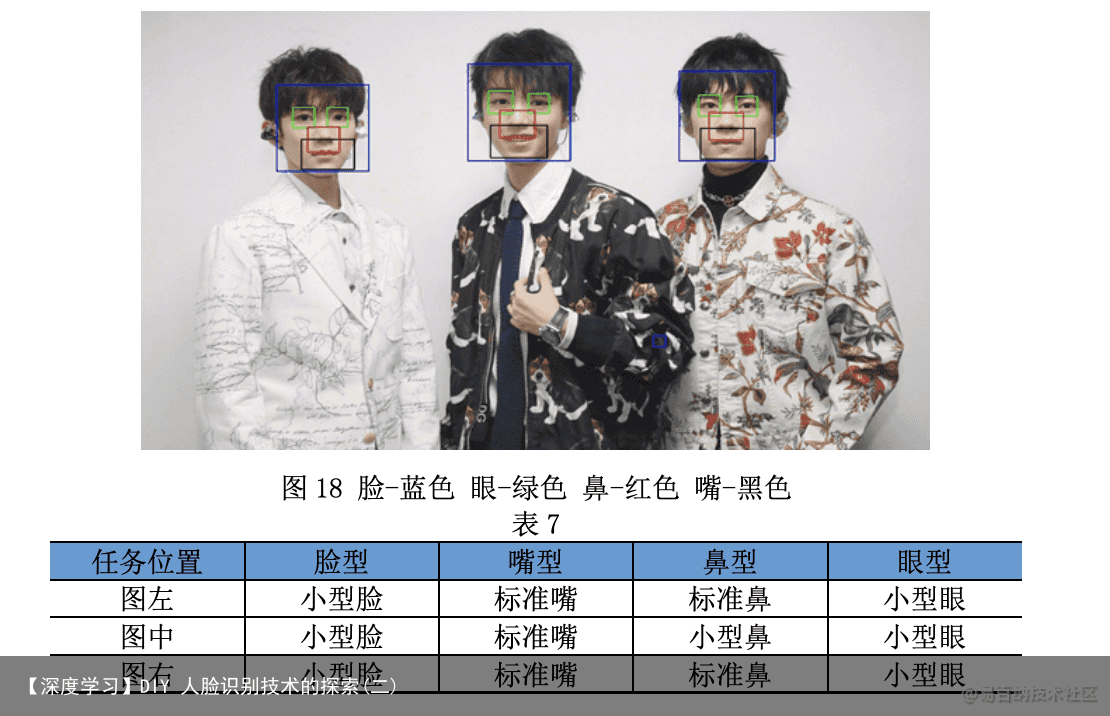
邻近算法,或者说 K 最近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘 分类技 术中最简单的方法之一。所谓 K 最近邻,就是 k 个最近的邻居的意思, 说的是每个样本都可以用它最接近的 k 个邻居来代表。Cover 和 Hart 在 1968 年 提出了最初的邻近算法。KNN 是一种分类算法,它输入基于实例的学习,属于懒 惰学习即 KNN 没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了 分类和特征值,待收到新样本后直接进行处理。与急切学习相对应。KNN 是通过 测量不同特征值之间的距离进行分类。思路是:如果一个样本在特征空间中的 k 个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN 算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最 邻 近的一个或者几个样本的类别来决定待分样本所属的类。如图 11 我们确定 绿点属于哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的 k 个点,看这 k 个 点的大多数颜色是什么颜色。当 k 取 3 的时候,我们可以看出 距离最近的三个,分别是 红色、红色、蓝色,因此得到目标点为红色。KNN 算法 的描述如下 :
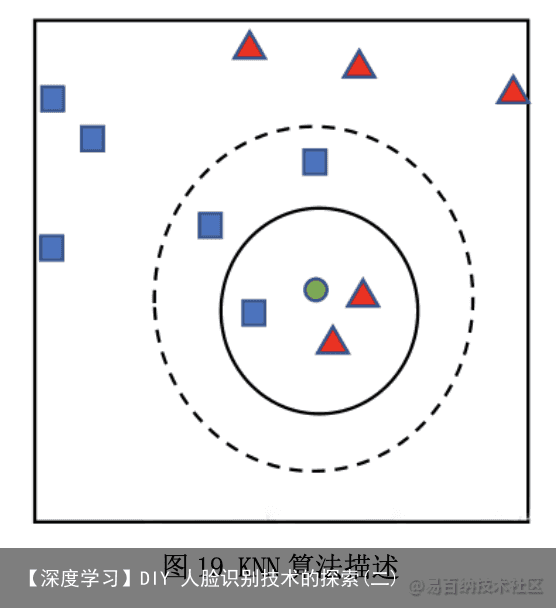
i)计算测试数据与各个训练数据之间的距离; ii)按照距离的递增关系进行排序;
iii)选取距离最小的 K 个点;
iv)确定前 K 个点所在类别的出现频率;
v)返回前 K 个点中出现频率最高的类别作为测试数据的预测分类。K 是临近数, 即在预测目标点时取几个临近的点来预测。
i)下载训练集的 3*50 张图片放在三个带标签文件夹中,并载入测试集、载入训 练集和标签。
ii)进行图片预处理(大小统一,灰度化),通过 PCA 拟合并降维训练数据。 iii)利用人脸Haar分类器 haarcascade_frontalface_alt2 识别出人脸区域
18
集合。
iv)提取人脸区域集合作为训练集和测试集,训练集标签输入进 SVM 分类器。 v)提取人脸区域集合作为训练集和测试集,训练集标签输入进 KNN 分类器。 vi)KNN 分类器和 SVM 分类器返回预测标签值。
vii)根据预测标签值进行 Step4 分类后的脸部的框取以及标注。 viii)显示图片。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】DIY 人脸识别技术的探索(二) https://www.yhzz.com.cn/a/11820.html