
伴随着人工智能技术的发展,人们对信息安全有了更高的要求,传统的模 式早已满足不了,人脸识别技术应运而生,走进了人们生活的方方面面。小到 可以通过扫描人脸进行订单支付,大到可以通过人脸识别协助警察追踪破案, 极大的满足了人们迫切提高生活品质的需求。为了到 2030 年使中国成为世界主 要人工智能创新中心,国家大力鼓励支持高校老师和学生探索和钻研人脸识别 技术,因此本文也针对问题一二三分别建立了不同的模型来找到人脸的大致位 置,并对面部特征“脸型、嘴型、鼻型、眼型”进行分类,最后根据不同的面 部特征来识别人脸。
对于问题一,为了找到图像中人脸的大致位置,本文运用了 MTCNN,Multi- task convolutional neural network(多任务卷积神经网络),它将人脸区域 检测与人脸关键点检测放在了一起。该网络为了方便对各种图像进行检测首先把 各种大小不同的图像转变为标准尺寸的图像,然后根据面部特征关键点和边框限 定找到大致存在人脸的多个候选边框,然后经过筛选优化找到可信的存在人脸的 候选边框。
对于问题二,为了判断图 2 中各个人物的脸型、鼻型、眼型、唇形等,在问 题一的基础上,先运用 OpenCV 导入面部和五官 haar 特征分类器找到“眼睛” “鼻子”“嘴巴”的位置,然后利用 Python 的 size 函数运行提取“脸型、嘴型、 鼻型、眼型”等面部特征的特征宽度,最后通过计算眼睛、鼻子 和嘴巴的宽度 和的比人脸的长度得到的比例大小,通过比例大小对人物的脸型、鼻型、眼型、 唇形进行分类。
对于问题三,在问题一和问题二的基础上,首先从图像中检测有无存在人脸, 如果存在人脸则利用基于 PCA 主成分分析法有效的利用低维提取和表示出人脸 的特征,然后利用基于 K 最邻近算法的人脸识别模型接受样本进行处理并由最邻 近的一个或几个样本的类型来确定该样本的类型。正是依照着人脸捕获、识别功 能来检测判断图 2、图 3 中是否有人物与图 1 的人物是同一人,并在有同一个人 的情况下在图片中框出具体是哪个人物与图 1 的人物一样。关键词:人脸识别 MTCNN 神经网络 haar 模型 Adaboost 算法
问题重述1.1 问题的背景
1.2 问题的求解
曾经神秘的人脸识别技术,由于越来越贴近生活,现在也变得平常起来。美
图秀秀等手机 APP 把人脸识别技术用于“一键美颜”,让留住的瞬间更加美丽; 学校和公司逐步安装了人脸识别考勤机,方便管理人员进行考核和查勤;警方在 刑事侦查时,也经常采用人脸识别技术从海量信息中寻找犯罪嫌疑人,使正义的 力量得到技术的支持;交互式机器人通过人脸识别技术判断用户的心情。因此, 人脸识别技术应用广泛,越来越深入我们的日常生活,本文认为对 DIY 人脸识别 技术的研究十分重要。
常用的第一步人脸识别方法:第一步,确定人脸的位置;第二步,对人脸做
一些技术处理;第三步,提取人脸的细节特征。本文在计算机上实现 DIY 人脸技
术识别,根据提出的问题建立模型,并设计求解方案解决一下问题。
(1)问题一:为了判断人脸在照片中的大致位置,本文采用了 MTCNN 模型,
并运用该模型在图 1 和图 2 中“框出”人脸的大致位置。
(2)问题二:在问题一的基础上,建立人脸精确识别的数学模型,判断图 2
中各个人物的脸型、鼻型、眼型、唇形等五官。
(3)问题三:在问题二的基础上,建立人脸匹配的数学模型,判断附件_图 2、附件_图 3 中是否有人物与附件_图 1 的人物是同一人,如果有,请在图片中
框出具体是哪个人物与附件_图 1 的人物一样。 模型假设假设不存在长相完全一样的两个人
假设人脸图像符合要求且真实有效,具有研究价值
假设人脸图像的各项参数值在电脑的可运行范围之内。 定义与符号说明
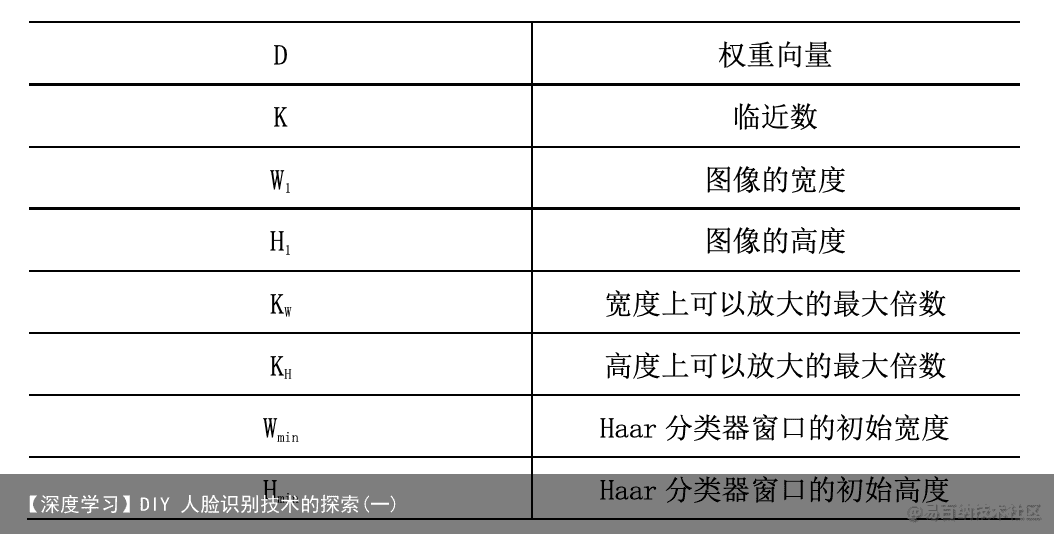
4.1 问题一的分析
运用 MTCNN 神经网络,首先确定一个合理的图像尺寸,并将尺寸大小不一的 图像变换到该尺寸,以便对所有图像进行人脸检测。在此基础上对图像进行特征 提取和标定边框来初步确定可能存在人脸的多个候选框,然后运用边框回归和一 个面部特征关键点来确过滤筛除效果差的候选框,最后经过优化找出相对可信的 人脸候选框。从而判断人脸在照片中的大致位置,并在图 1 和图 2 中框出人脸的 大致位置。
4.2 问题二的分析
在
小。
4.3 问题三的分析
问题一大致判断出人脸位置的基础上进行精确人脸识别,需要先提取人脸
图片,在此基础上判断出各个人物的脸型、鼻型、眼型、唇形等五官。运用问题 一所构建的模型和算法,对其进行人脸识别。关于人的五官特征比较,运用人脸 五官位置黄金比例,和提取的五官位置比例比较,超出黄金值则为大,反正则为
在问题一、二的基础上,识别出人脸,由于识别出的人脸并没有特征人物
比较对象,需要通过建立训练集,将多个同种人物脸型做比较,建立人脸匹配
模型,与待识别的人脸进行特征比较并预测匹配。 模型的建立与求解5.1 问题一的模型建立与求解
5.1.1 基于 MTCNN 的人脸识别模型
MTCNN,Multi-task convolutional neural network(多任务卷积神经网络), 将人脸区域检测与人脸关键点检测放在了一起,它的主题框架类似于 cascade。 总体可分为 P-Net、R-Net、和 O-Net 三层网络结构。MTCNN 模型也用到了图像 金字塔、边框回归、非最大值抑制等技术。构建图像金字塔首先将图像进行不同 尺度的变换,构建图像金字塔,以适应不同大小的人脸的进行检测。MTCNN 对 图像的识别采用的是级联思想:图片输入到 PNet 得到输出,将 PNet 的输出输入 到 RNet 得到输出,再将 RNet 的输出输入到 ONet 得到最终的输出。
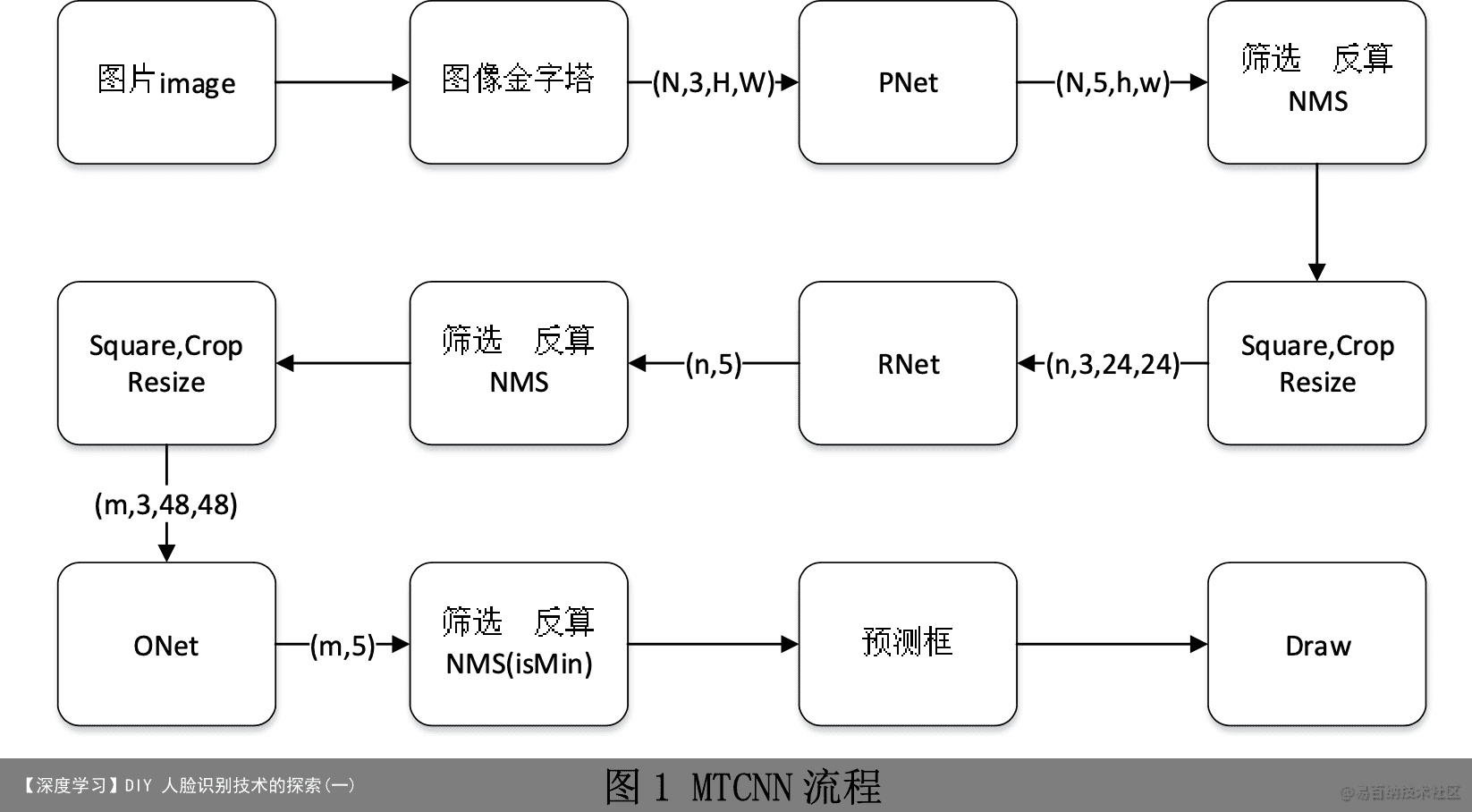
5.1.2 制作样本
制作样本所用到的是 CelebA 数据集,CelebA Anno:img_id x1 y1 w h,这 里需要计算成 cx cy w h(cx,cy 为中心点坐标)以方便后面的使用。 建议框的选取: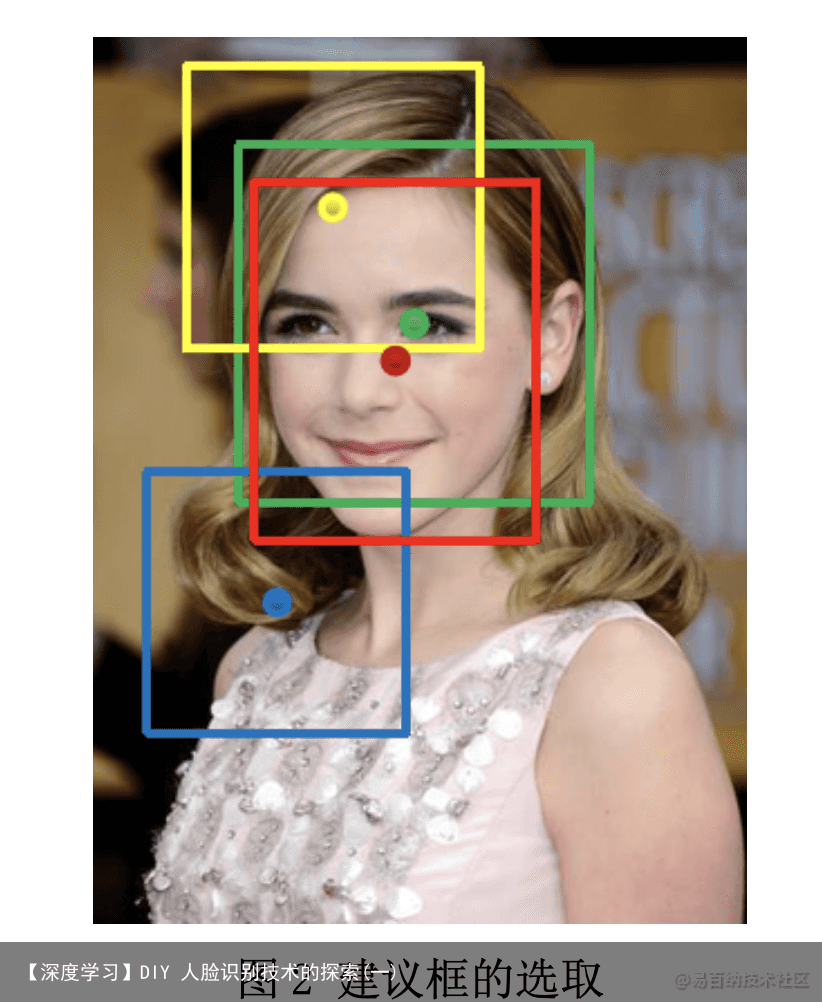
红色的框为标签框,红色的点为标签框的中心点(cx, cy),获取到标签框的
最大边长 max_side,本文通过偏移中心点和最大边长来得到建议框,偏移方法 是先制定一个 1:1:3 或者 1:3:5 的种子(随机小数)(如:[0.1, 0.5, 0.85, 0.9, 0.95] 0.1偏移小的大概率为正样本,0.5偏移大概率为部分样本,0.9偏移大 的大概率为负样本)
建议框的中心点=真实框中心点±种子真实框中心点 建议框的边长=真实框最大边长±种子真实框最大边长(建议框为正方形) 但为更好的区分样本,本文使用 IOU(图像重合度)来区分样本,IOU 为两
个框交集面积与并集面积的比值,IOU 小则重合程度低,IOU 大则重合程度高, IOU>0.65 为正样本 如绿色框,0.4<IOU<0.65 为部分样本 如黄色框,IOU<0.3 的 为负样本如蓝色框。偏移量的计算:
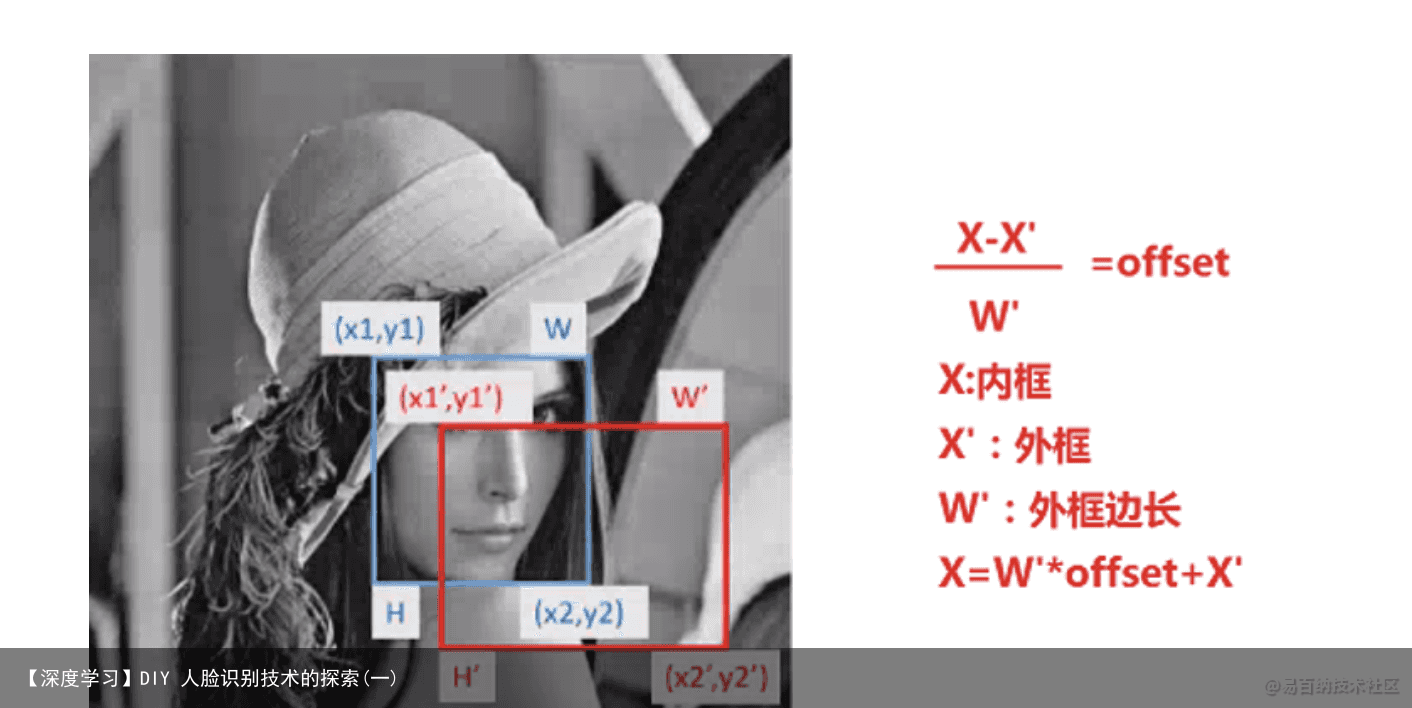
图 3 偏移量的计算 蓝色框为真实框,红色框为建议框,而坐标点 x1,y1,x2,y2 的偏移量
offset=(真实框的坐标-建议框的坐标)/建议框的边长(建议框是正方形),由于 本文训练的是建议框而非真实框,因此要除偏移框的边长而不是真实框的边长。样本文件和标签文件:
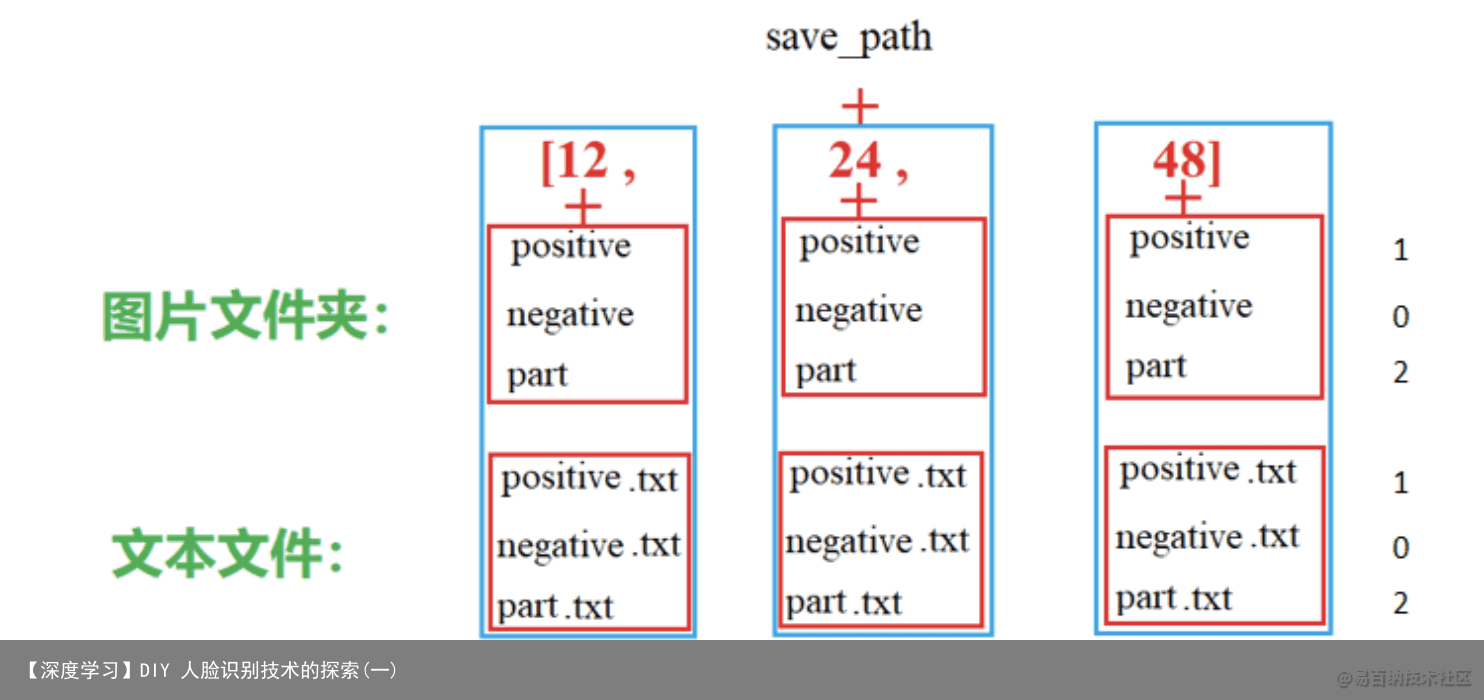
图 4 样本文件和标签文件
保存的路径下包含 3 个 size 的子文件夹,每个子文件夹下包含 positive
正、negative 负、part 部分 3 个文件夹和标签 txt 文本文件 标签值为:sample/image_id cls x1_offset y1_offset x2_offset y2_offset 正样本 cls(置信度)为 1,部分样本 cls 为 2,负样本 cls 为 0(且负样本的 offset 都可以为 0)
5.1.3 网络结构所有网络激活函数都是使用的 PReLU,PReLU 负半轴有斜率不会丢失负半轴 的部分特征。所有网络的隐藏层都加 BatchNormal,效果比不加好。
PNet 训练 12*12 样本集(层数浅、图片尺寸小(参数量小)所以训练最快)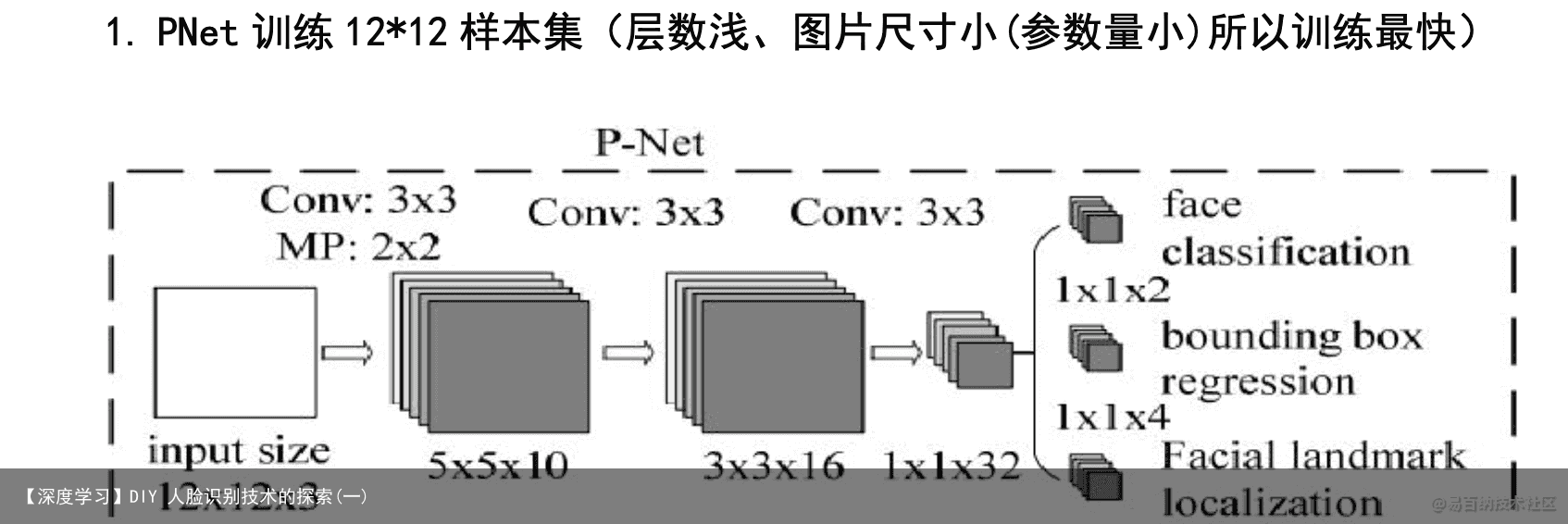 PNet 为全卷积网络,因为在侦测时 PNet 的输入是图像金字塔变形后的图片 集每张图片大小都不一样,使用全卷积网络才能训练这些图片,PNet 只有 3 层 隐藏层,层数很浅作用是为了侦测时更快的获取大量的候选框。(不放过图片中 任何一个人脸)训练时输入为(N,3,12,12)N 为 12*12(包含正、部分、负样本) 的所有样本图片数输出为(N,1,1,1)置信度,图片中使用的是 softmax 输出函数, 而我使用的是 Sigmoid 输出函数和(N,4,1,1)4 个坐标点的偏移量侦测时输入为 (N,3,H,W)N 为做完图像金字塔所得到的所有图片数(min(H, W)≥12)输出为 (N,1,h,w)置信度和(N,4,h,w)4 个坐标点的偏移量
PNet 为全卷积网络,因为在侦测时 PNet 的输入是图像金字塔变形后的图片 集每张图片大小都不一样,使用全卷积网络才能训练这些图片,PNet 只有 3 层 隐藏层,层数很浅作用是为了侦测时更快的获取大量的候选框。(不放过图片中 任何一个人脸)训练时输入为(N,3,12,12)N 为 12*12(包含正、部分、负样本) 的所有样本图片数输出为(N,1,1,1)置信度,图片中使用的是 softmax 输出函数, 而我使用的是 Sigmoid 输出函数和(N,4,1,1)4 个坐标点的偏移量侦测时输入为 (N,3,H,W)N 为做完图像金字塔所得到的所有图片数(min(H, W)≥12)输出为 (N,1,h,w)置信度和(N,4,h,w)4 个坐标点的偏移量
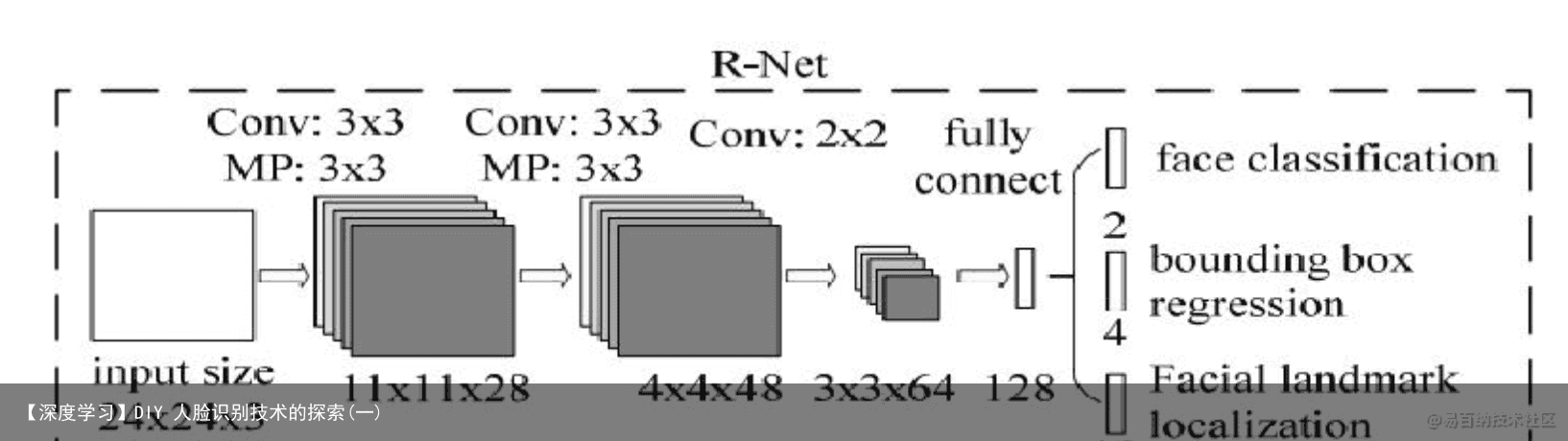
图 6 RNet 样本集
Rnet 为卷积+全连接网络,加全连接的目的是为了特征融合,在侦测时是为
了筛选掉一部分不存在人脸的候选框。
训练时输入为(N,3,24,24)N 为 24*24(包含正、部分、负样本)的所有样本图片 数输出为(N,1,1,1)置信度,图片中使用的是 softmax 输出函数,而我使用的是 Sigmoid 输出函数和(N,4,1,1)4 个坐标点的偏移量侦测时输入为(n,3,24,24)n 为 PNet 输出的所有候选框经过筛选、反算、NMS、正方形转换、裁剪、变形后的 图片数输出为(n,1,1,1)置信度和(n,4,1,1)4 个坐标点的偏移量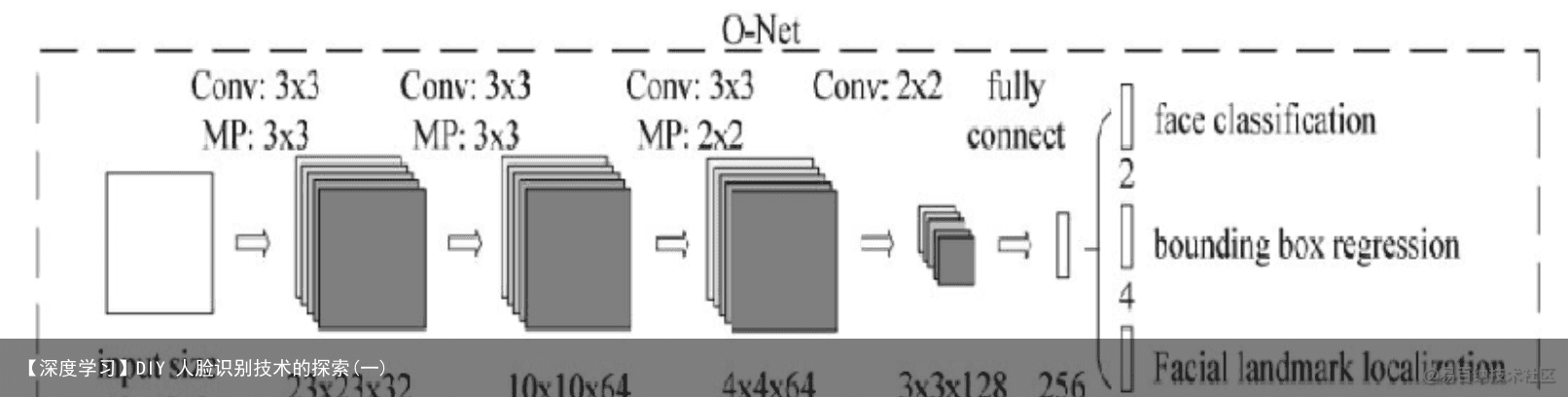
图 7 ONet 样本集
ONet 也为卷积+全连接网络,但是层数更深为 5 层为了提取更细节的特征,
回归候选框更精确。训练时输入为(N,3,48,48)N 为 48*48(包含正、部分、负样 本)的所有样本图片数输出为(N,1,1,1)置信度,图片中使用的是 softmax 输出 函数,而我使用的是 Sigmoid 输出函数和(N,4,1,1)4 个坐标点的偏移量侦测时 输入为(m,3,48,48)m 为 RNet 输出的所有候选框经过筛选、反算、NMS、正方形转换、裁剪、变形后的图片数输出为(m,1,1,1)置信度和(m,4,1,1)4 个坐标点的 偏移量。 模型评价与推广6.1 模型的优点
(1)Haar 分类器速度快,效率比较高,可以在同一张图片上识别出多张人脸。 (2)Adaboost 是一种有很高精度的分类器, 可以使用各种方法构建子分类器, 不用做特征筛选。
(3)KNN 算法简单且容易实现,比较适用于样本容量比较大的类域和类域的交 叉或重叠较多的待分样本集的自动分类。
(4)KNN 对于随机分布的数据集分类效果较差,对于类内间距小,类间间距大 的数据集分类效果好,而且对于边界不规则的数据效果好于线性分类器。
6.2 模型的缺点
(1)基于 Haar 如果图片中存在相似的两张脸,无法匹配正确的人脸。 (2)人脸在图片中有较大的倾斜度,无法标记并识别出人脸。 (3)当训练数据很大时,需要大量的存储空间,而且需要计算待测样本和 练数据 集中所有样本的距离,所以非常耗时。
(4)KNN 对于随机分布的数据集分类效果较差。
6.3 模型的推广
(1)全文所有的人脸识别模型都是基于 Adaboost 算法决策树的 Haar 特征值 分类器,该模型和方法可以推广到人脸各个特征识别,甚至是其他的图片动 物植物物体的特征分类选区。
(2)SVM 和 KNN 是机器学习的简单特征分类器,可以用到机器学习的其他方 面。 参考[1]刘长伟.基于 MTCNN 和 Facenet 的人脸识别[J].邮电设计技术,2020(02):32-38. [2]用于人脸识别的图像预处理方法研究与实现[J]. 王虹,董雅丽. 武汉理工大学学报(交 通科学与工程版). 2007(05)
[3]丁宏伟. 基于 OpenCV 的实时人脸识别系统的设计与实现[D].吉林大学,2020.
[4] Face detection with the faster R-CNN. Jiang H,Learned-Miller E. 12- (th)IEEE International Conference on Automatic Face&Gesture Recognition . 2017
[5] Similarity of color images. Stricker M,Orengo M. Proceedings of SPIE:Storage and retrieval for Images and Video database III . 1995
[6]孙大瑞,吴乐南.基于非线性特征提取和 SVM 的人脸识别算法[J].电子与信息学 报,2004(02):307-311.
[7]刘禹欣,朱勇,孙结冰,王一博.Haar-like 特征双阈值 Adaboost 人脸检测[J].中国图象图 形学报,2020,25(08):1618-1626.
[8]李燕,王玲.基于肤色和 Haar 方差特征的人脸检测[J].计算机工程与科 学,2015,37(01):146-151.
[9]程培培,陈典典,马军山.基于 Haar 分类器和 AAM 算法的人脸基准点定位[J].光学仪 器,2018,40(06):48-53.
[10] Face recognition algorithm based on VGG network model and SVM. Chen H L,Chen H Y. Journal of Physics:Conference Series . 2019
[11]Machine vision quality assessment for robust face detection[J] . Rajiv Soundararajan,Soma Biswas. Signal Processing: Image Communication . 2018免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】DIY 人脸识别技术的探索(一) https://www.yhzz.com.cn/a/11818.html