【深度学习】梯度和方向导数概念解析(代码基于Pytorch实现)

方向导数的本质是一个数值,简单来说其定义为:
一个函数沿指定方向的变化率。因此,构建方向导数需要有两个元素:
1) 函数
2) 指定方向
当然,与普通函数的导数类似,方向导数也不是百分之百存在的,需要函数满足在某点处可微,才能计算出该函数在该点的方向导数。
至于其物理含义,这里采用最常用的下山图来表示。
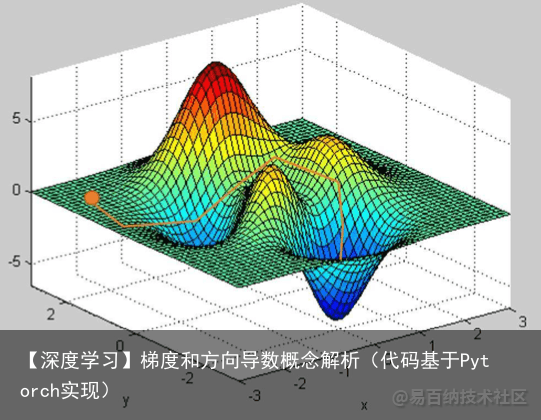 简单将上图看作是一座山的模型,我们处在山上的某一点处,需要走到山下。理论上来说,这座山的表面是可以通过一个函数的描述的(虽然想要找到这个函数可能很难),而这个函数可以在不同的方向上都确定出一个方向导数,这就好比于如果我们想下山,道路并不是唯一的,而是可以沿任何方向移动。区别在于有些方向可以让我们下山速度更快,有些方向让我们下山速度更慢,有些方向甚至引导我们往山顶走(也可以理解为下山速度时负的)。在这里,速度的值就是方向导数的直观理解。
简单将上图看作是一座山的模型,我们处在山上的某一点处,需要走到山下。理论上来说,这座山的表面是可以通过一个函数的描述的(虽然想要找到这个函数可能很难),而这个函数可以在不同的方向上都确定出一个方向导数,这就好比于如果我们想下山,道路并不是唯一的,而是可以沿任何方向移动。区别在于有些方向可以让我们下山速度更快,有些方向让我们下山速度更慢,有些方向甚至引导我们往山顶走(也可以理解为下山速度时负的)。在这里,速度的值就是方向导数的直观理解。
梯度与方向导数是有本质区别的,梯度其实是一个向量,其定义为: 一个函数对于其自变量分别求偏导数,这些偏导数所组成的向量就是函数的梯度
。
这句话记住背下来!!! 在很多资料中可以看到如下的梯度定义方法:在一元函数中,导数就是函数的变化率。对于二元函数的“变化率”,由于自变量多了一个,情况就要复杂的多。
在 xOy 平面内,当动点由 P(x0,y0) 沿不同方向变化时,函数 f(x,y) 的变化快慢一般来说是不同的,因此就需要研究 f(x,y) 在 (x0,y0) 点处沿不同方向的变化率。
在这里我们只学习函数 f(x,y) 沿着平行于 x 轴和平行于 y 轴两个特殊方位变动时, f(x,y) 的变化率。
偏导数的表示符号为:∂。
偏导数反映的是函数沿坐标轴正方向的变化率。表示固定面上一点的切线斜率。
偏导数 fx(x0,y0) 表示固定面上一点对 x 轴的切线斜率;偏导数 fy(x0,y0) 表示固定面上一点对 y 轴的切线斜率。
高阶偏导数:如果二元函数 z=f(x,y) 的偏导数 fx(x,y) 与 fy(x,y) 仍然可导,那么这两个偏导函数的偏导数称为 z=f(x,y) 的二阶偏导数。二元函数的二阶偏导数有四个:f”xx,f”xy,f”yx,f”yy。
注意:
f”xy与f”yx的区别在于:前者是先对 x 求偏导,然后将所得的偏导函数再对 y 求偏导;后者是先对 y 求偏导再对 x 求偏导。当 f”xy 与 f”yx 都连续时,求导的结果与先后次序无关。

诚然,这种定义方法更加权威,但是却不够直观,这也是为什么我在高等数学课堂上学习梯度概念时感觉云里雾里。这种定义方法只针对二元函数,所以公式中的i,j可分别表示为函数在x和y方向上的单位向量,这样的描述可以让我们更好理解(因为人类大脑可以比较轻松的理解三维世界的模型图),但是一旦到了更高维度的世界,单纯靠这个公式就不容易理解了。
3.梯度与方向导数的关系
梯度与方向导数的关系应该如何描述呢?
函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。以上描述非常好理解,那如何证明呢?


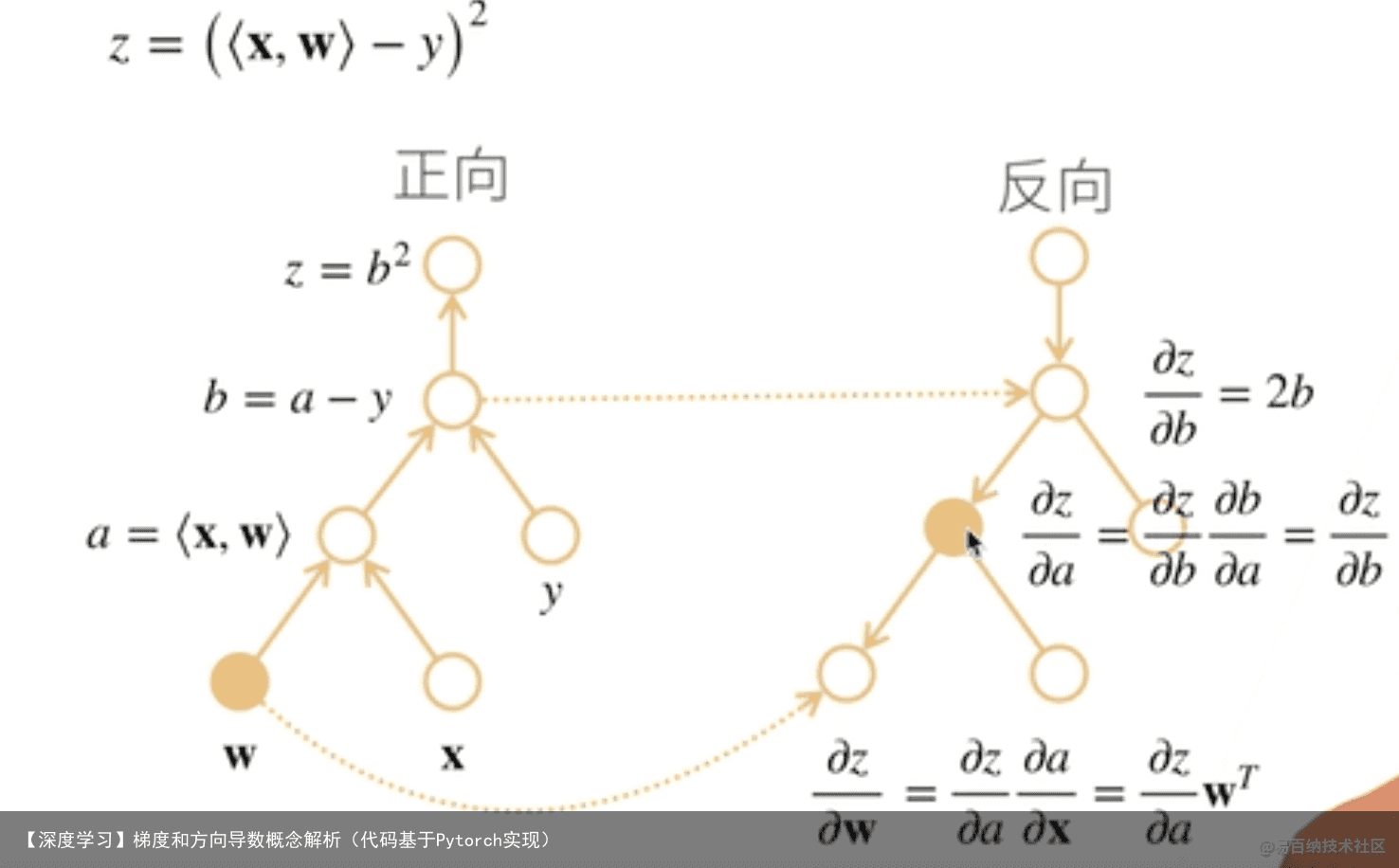
存储梯度:


通过调用反向传播函数来计算y关于x每个一分量的梯度。

 4 梯度下降
4 梯度下降
4.1 概述

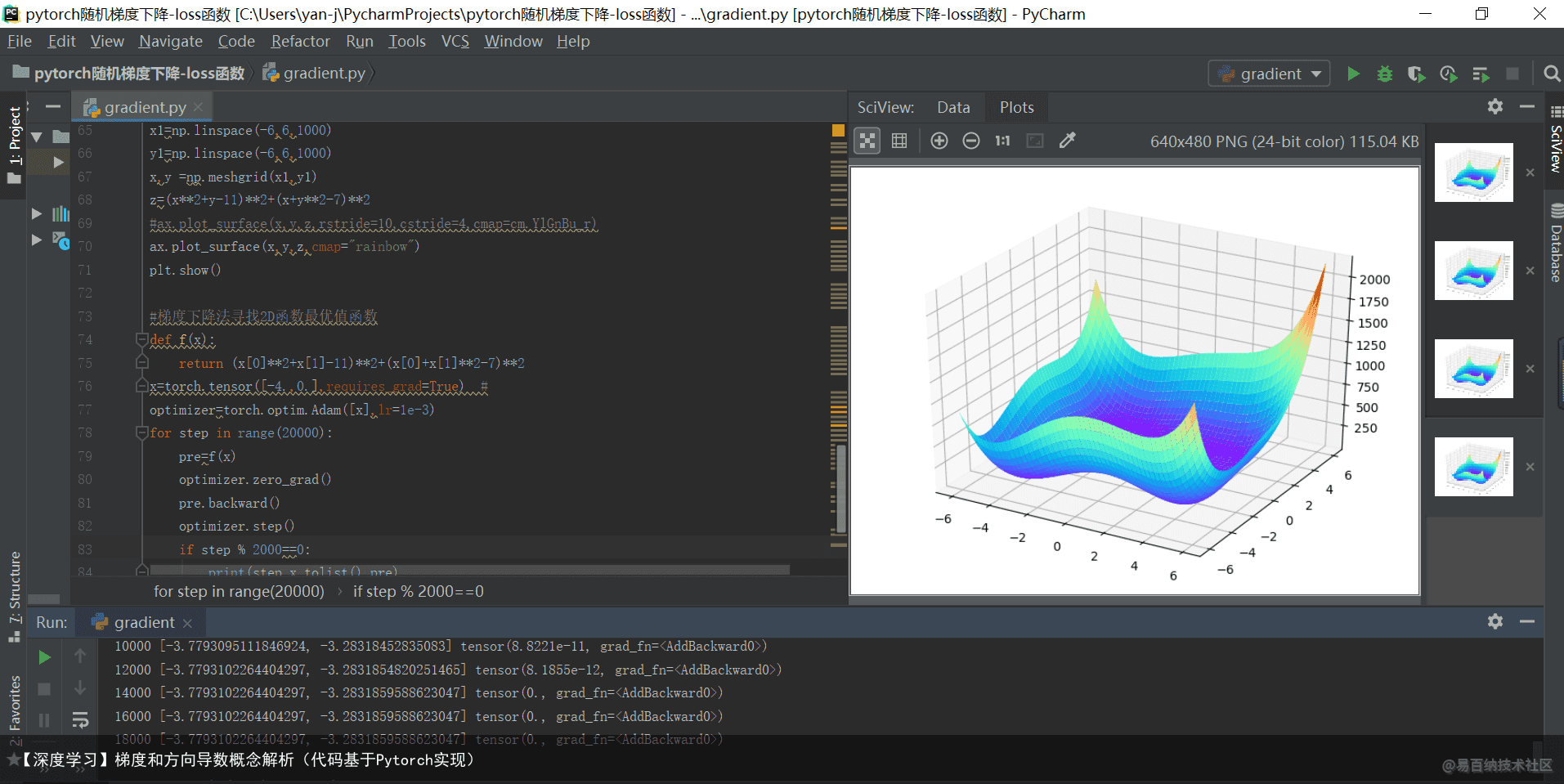
4.2 小批量梯度下降

输出结果如下所示:
 5 总结
5 总结
微分和积分是微积分的两个分支,其中前者可以应用于深度学习中无处不在的优化问题。
导数可以被解释为函数相对于其变量的瞬时变化率。它也是函数曲线的切线的斜率。
梯度是一个向量,其分量是多变量函数相对于其所有变量的偏导数。 链式法则使我们能够微分复合函数。1、梯度、偏微分以及梯度的区别和联系
(1)导数是指一元函数对于自变量求导得到的数值,它是一个标量,反映了函数的变化趋势;
(2)偏微分是多元函数对各个自变量求导得到的,它反映的是多元函数在各个自变量方向上的变化趋势,也是标量;
(3)梯度是一个矢量,是有大小和方向的,其方向是指多元函数增大的方向,而大小是指增长的趋势快慢。
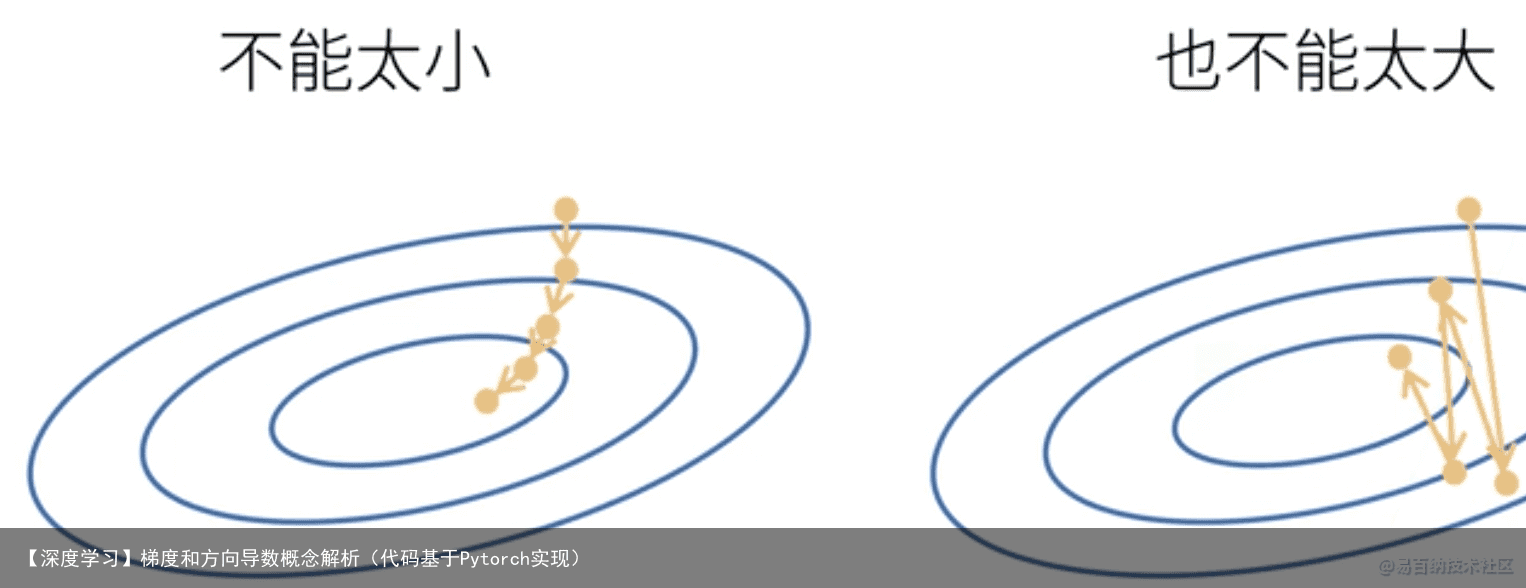
2、在寻找函数的最小值的时候可以利用梯度下降法来进行寻找,一般会出现以下两个问题局部最优解和铵点(不同自变量的变化趋势相反,一个处于极小,一个处于极大)
3、初始状态、学习率和动量(如何逃出局部最优解)是全部寻优的三个重要影响因素
4、常见函数的梯度计算基本和一元函数导数是一致的
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】梯度和方向导数概念解析(代码基于Pytorch实现) https://www.yhzz.com.cn/a/11775.html