
1 概述
我们之前描述了仿射变换,它是一个带有偏置项的线性变换。首先,回想一下softmax回归的模型结构。该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作。如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了。但是,仿射变换中的线性是一个很强的假设。
线性模型可能会出错 例如,线性意味着单调假设:特征的任何增大都会导致模型输出增大(如果对应的权重为正),或者导致模型输出减少(如果对应的权重为负)。有时这是有道理的。例如,如果我们试图预测一个人是否会偿还daikuan。我们可以认为,在其他条件不变的情况下,收入较高的申请人总是比收入较低的申请人更有可能偿还daik。但是,虽然收入与还款概率存在单调性,但它们不是线性相关的。收入从0增加到5万,可能比从100万增加到105万带来更大的还款可能性。处理这一问题的一种方法是对我们的数据进行预处理,使线性变得更合理,如使用收入的对数作为我们的特征。
我们可以很容易地找出违反单调性的例子。例如,我们想要根据体温预测死亡率。对于体温高于37摄氏度的人来说,温度越高风险越大。然而,对于体温低于37摄氏度的人来说,温度越高风险就越低。在这种情况下,我们也可以通过一些巧妙的预处理来解决问题。例如,我们可以使用与37摄氏度的距离作为特征。
但是,如何对猫和狗的图像进行分类呢?增加位置(13, 17)处像素的强度是否总是增加(或总是降低)图像描绘狗的可能性?对线性模型的依赖对应于一个隐含的假设,即区分猫和狗的唯一要求是评估单个像素的强度。在一个倒置图像保留类别的世界里,这种方法注定会失败。
与我们前面的例子相比,这里的线性很荒谬,而且我们难以通过简单的预处理来解决这个问题。这是因为任何像素的重要性都以复杂的方式取决于该像素的上下文(周围像素的值)。我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用。在此表示的基础上建立一个线性模型可能会是合适的,但我们不知道如何手动计算这么一种表示。对于深度神经网络,我们使用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。
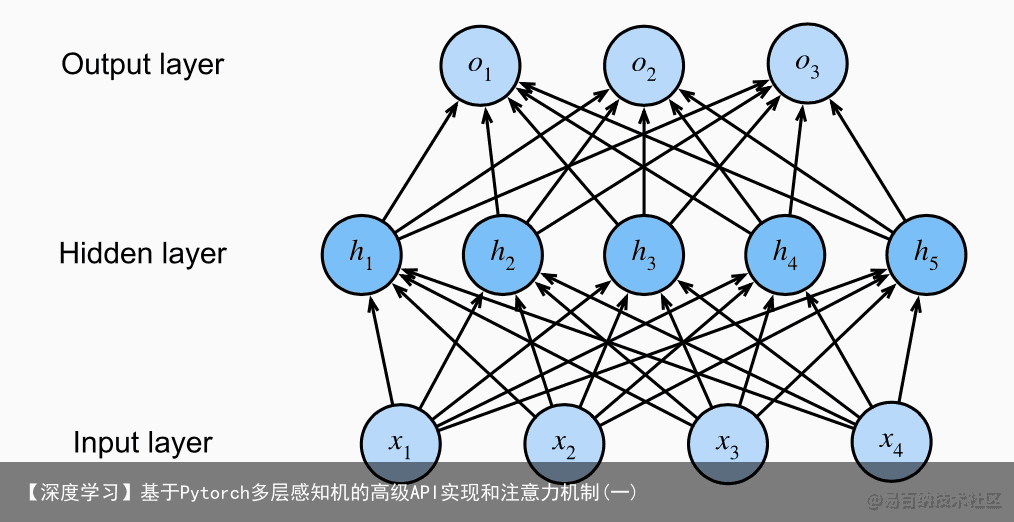
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算;因此,这个多层感知机中的层数为2。注意,这两个层都是全连接的。每个输入都会影响隐藏层中的每个神经元,而隐藏层中的每个神经元又会影响输出层中的每个神经元。 2 从线性到非线性-激活函数
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活。它们是将输入信号转换为输出的可微运算。大多数激活函数都是非线性的。由于激活函数是深度学习的基础,下面(简要介绍一些常见的激活函数)。
2.1 ReLU函数
最受欢迎的选择是线性整流单元(Rectified linear unit,ReLU),因为它实现简单,同时在各种预测任务中表现良好。 [ReLU提供了一种非常简单的非线性变换
]。 给定元素$x$,ReLU函数被定义为该元素与$0$的最大值:
($$\operatorname{ReLU}(x) = \max(x, 0).$$)
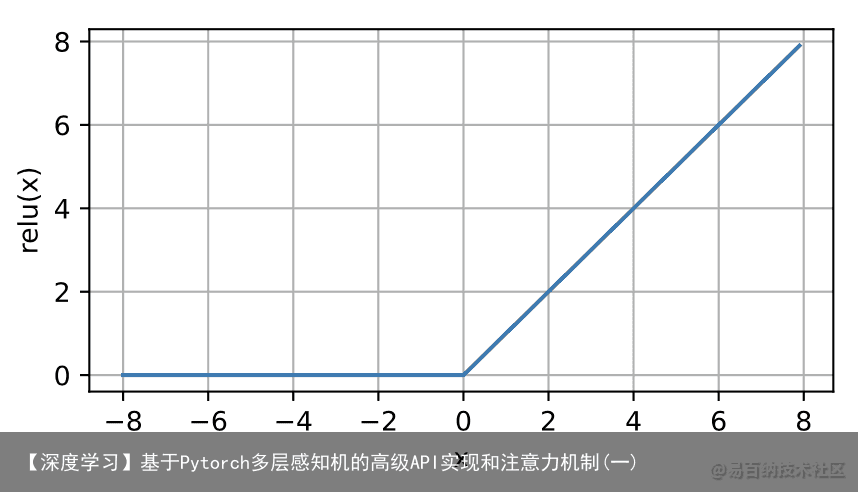
通俗地说,ReLU函数通过将相应的激活值设为0来仅保留正元素并丢弃所有负元素。为了直观感受一下,我们可以画出函数的曲线图。正如从图中所看到,激活函数是分段线性的。 x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True) y = torch.relu(x) d2l.plot(x.detach(), y.detach(), x, relu(x), figsize=(5, 2.5))
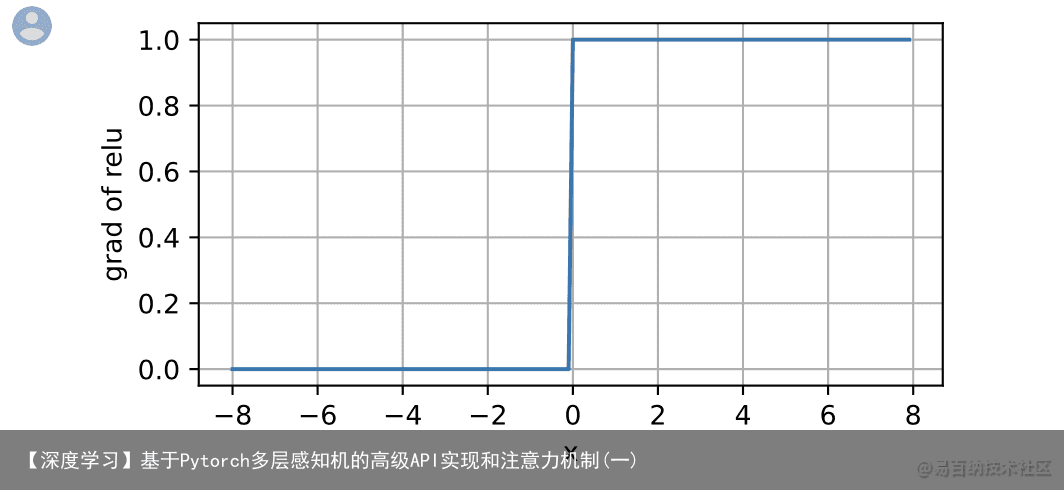
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。注意,当输入值精确等于0时,ReLU函数不可导。在此时,我们默认使用左侧的导数,即当输入为0时导数为0。我们可以忽略这种情况,因为输入可能永远都不会是0。这里用上一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”,这个观点正好适用于这里。下面我们绘制ReLU函数的导数。 y.backward(torch.ones_like(x), retain_graph=True) d2l.plot(x.detach(), x.grad, x, grad of relu, figsize=(5, 2.5))
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题(稍后将详细介绍)。
注意,ReLU函数有许多变体,包括参数化ReLU(Parameterized ReLU,pReLU)函数 :cite:He.Zhang.Ren.ea.2015。该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
$$\operatorname{pReLU}(x) = \max(0, x) + \alpha \min(0, x).$$
2.2 sigmoid函数
[对于一个定义域在$\mathbb{R}$中的输入,sigmoid函数将输入变换为区间(0, 1)上的输出]。因此,sigmoid通常称为挤压函数(squashing function):它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
($$\operatorname{sigmoid}(x) = \frac{1}{1 + \exp(-x)}.$$)
在最早的神经网络中,科学家们感兴趣的是对“激发”或“不激发”的生物神经元进行建模。因此,这一领域的先驱,如人工神经元的发明者麦卡洛克和皮茨,从他们开始就专注于阈值单元。阈值单元在其输入低于某个阈值时取值0,当输入超过阈值时取值1。
当人们的注意力逐渐转移到基于梯度的学习时,sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。当我们想要将输出视作二分类问题的概率时,sigmoid仍然被广泛用作输出单元上的激活函数(你可以将sigmoid视为softmax的特例)。然而,sigmoid在隐藏层中已经较少使用,它在大部分时候已经被更简单、更容易训练的ReLU所取代。在后面关于循环神经网络的章节中,我们将描述利用sigmoid单元来控制时序信息流动的结构。
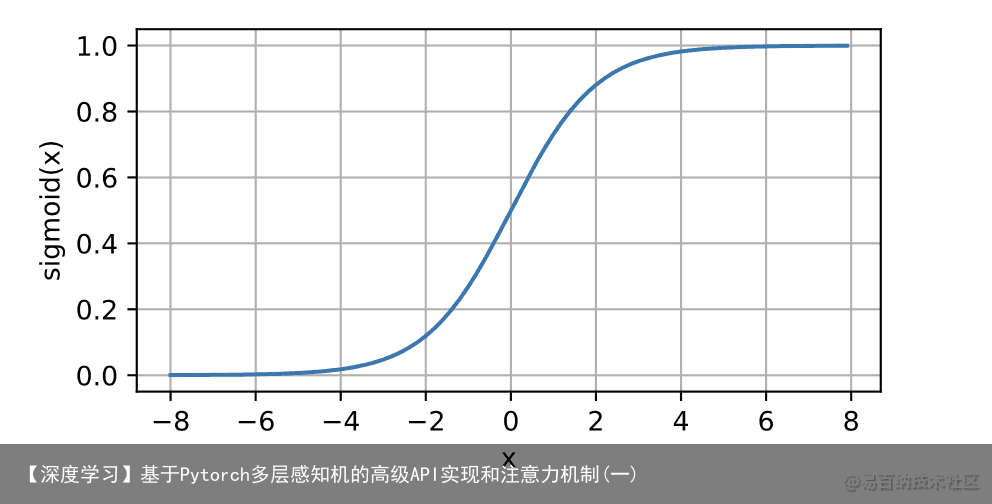
下面,我们绘制sigmoid函数。注意,当输入接近0时,sigmoid函数接近线性变换。
sigmoid函数的导数为下面的公式:
$$\frac{d}{dx} \operatorname{sigmoid}(x) = \frac{\exp(-x)}{(1 + \exp(-x))^2} = \operatorname{sigmoid}(x)\left(1-\operatorname{sigmoid}(x)\right).$$
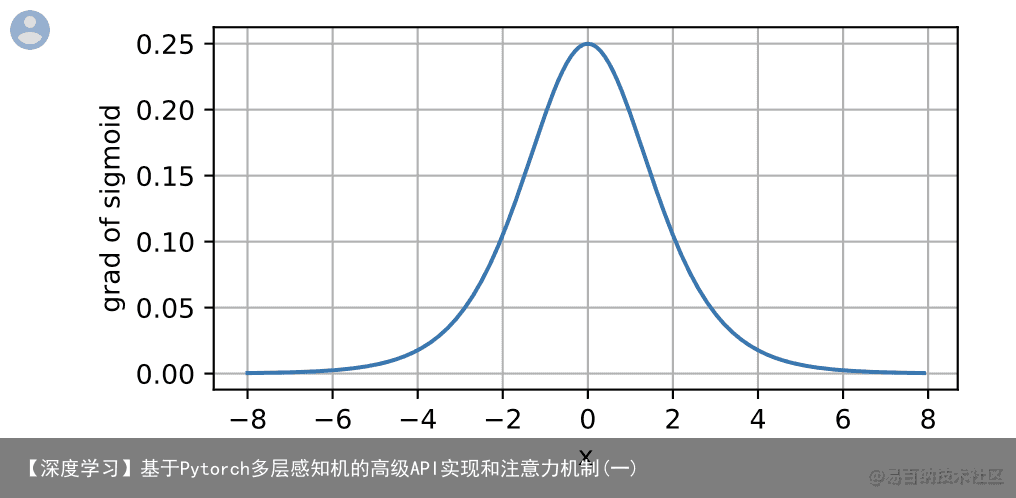
sigmoid函数的导数图像如下所示。注意,当输入为0时,sigmoid函数的导数达到最大值0.25。而输入在任一方向上越远离0点,导数越接近0。 # 清除以前的梯度。 x.grad.data.zero_() y.backward(torch.ones_like(x),retain_graph=True) d2l.plot(x.detach(), x.grad, x, grad of sigmoid, figsize=(5, 2.5))
2.3 tanh函数
与sigmoid函数类似,[tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上]。tanh函数的公式如下:
($$\operatorname{tanh}(x) = \frac{1 – \exp(-2x)}{1 + \exp(-2x)}.$$)
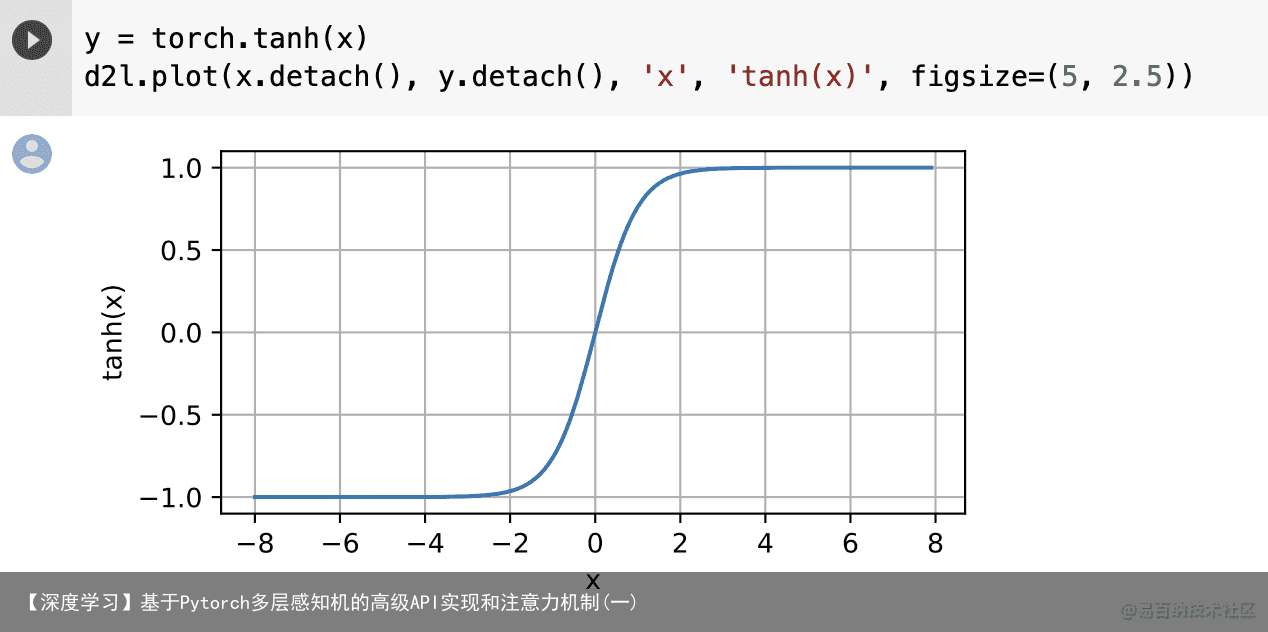
下面我们绘制tanh函数。注意,当输入在0附近时,tanh函数接近线性变换。函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。
tanh函数的导数是:
$$\frac{d}{dx} \operatorname{tanh}(x) = 1 – \operatorname{tanh}^2(x).$$
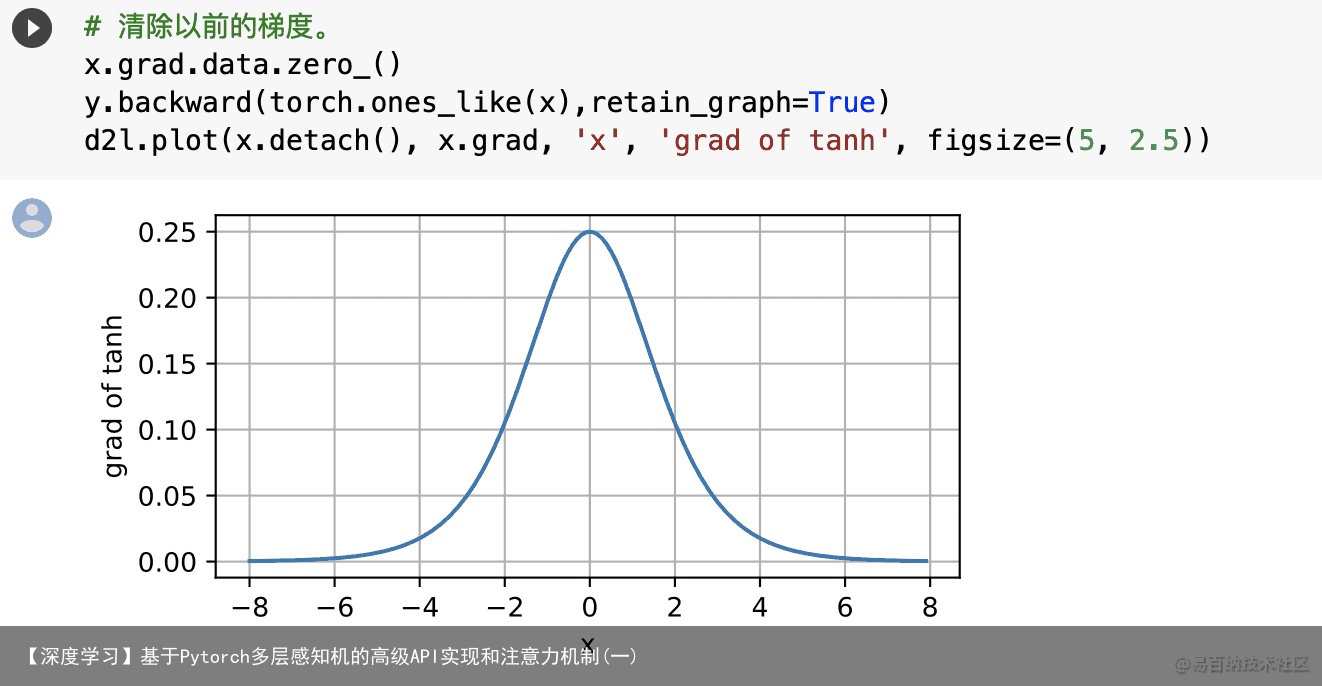
tanh函数的导数图像如下所示。当输入接近0时,tanh函数的导数接近最大值1。与我们在sigmoid函数图像中看到的类似,输入在任一方向上越远离0点,导数越接近0。
多层感知机在输出层和输入层之间增加一个或多个全连接的隐藏层,并通过激活函数转换隐藏层的输出。 这句话很重要哦,小本本记下来啦。 3 注意力机制PyTorch实现
注意力(Attention)机制最早在计算机视觉中应用,后来又在 NLP 领域发扬光大,该机制将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
2014 年,Google DeepMind 发表《Recurrent Models of Visual Attention》,使注意力机制流行起来;2015 年,Bahdanau 等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将注意力机制首次应用在 NLP 领域;2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了 RNN 和 CNN 等网络结构,而仅仅采用注意力机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也因此成了研究热点。
经过几年的发展,领域内产生了众多的注意力机制论文研究,这些工作在 CV、NLP 领域取得了较好的效果。
项目地址:https://github.com/xmu-xiaoma666/External-Attention-pytorch
项目介绍
项目作者对注意力机制进行了分类,分为三个系列:Attention 系列、MLP 系列、ReP(Re-Parameter)系列。其中 Attention 系列中包含有大名鼎鼎的《Attention is All You Need》等 11 篇论文;最近比较热门的 MLP 系列包括谷歌的 MLP-Mixer、gMLP ,Facebook 的 ResMLP,清华的 RepMLP ;此外,ReP(Re-Parameter)系列包括清华等提出的 RepVGG、 ACNet。 4 使用Tensor来写多层感知机
我们使用Tensor构建一个两层神经网络
Tips:通常构建一个神经网络,我们有如下步骤
1、构建好网络模型
2、参数初始化
3、前向传播
4、计算损失
5、反向传播求出梯度
6、更新权重
在我们构建神经网络之前,我们先介绍一个Tensor的内置函数 clamp()
该函数的功能是:clamp(x,low,high )若X在[low,high]范围内,则等于X;如果X小于low,则返回low;如果X大于high,则返回high。返回结果到一个新的Tensor。
这样,我们就可以使用 x.clamp(min=0) 来代替 relu函数
使用nn和optim来构建多层感知机 我们之前已经学过了,使用 nn 快速搭建一个线性模型。
现在就用 nn 来快速的搭建一个多层感知机,同样的optim来为我们提供优化功能 import torch from torch.autograd import Variable import torch.nn as nn # M是样本数量,input_size是输入层大小 # hidden_size是隐含层大小,output_size是输出层大小 M, input_size, hidden_size, output_size = 64, 1000, 100, 10 # 生成随机数当作样本,同时用Variable 来包装这些数据,设置 requires_grad=False 表示在方向传播的时候, # 我们不需要求这几个 Variable 的导数 x = Variable(torch.randn(M, input_size)) y = Variable(torch.randn(M, output_size)) # 使用 nn 包的 Sequential 来快速构建模型,Sequential可以看成一个组件的容器。 # 它涵盖神经网络中的很多层,并将这些层组合在一起构成一个模型. # 之后,我们输入的数据会按照这个Sequential的流程进行数据的传输,最后一层就是输出层。 # 默认会帮我们进行参数初始化 model = nn.Sequential( nn.Linear(input_size, hidden_size), nn.ReLU(), nn.Linear(hidden_size, output_size), ) # 定义损失函数 loss_fn = nn.MSELoss(reduction=sum) ## 设置超参数 ## learning_rate = 1e-4 EPOCH = 300 # 使用optim包来定义优化算法,可以自动的帮我们对模型的参数进行梯度更新。这里我们使用的是随机梯度下降法。 # 第一个传入的参数是告诉优化器,我们需要进行梯度更新的Variable 是哪些, # 第二个参数就是学习速率了。 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) ## 开始训练 ## for t in range(EPOCH): # 向前传播 y_pred= model(x) # 计算损失 loss = loss_fn(y_pred, y) # 显示损失 if (t+1) % 50 == 0: print(loss.data[0]) # 在我们进行梯度更新之前,先使用optimier对象提供的清除已经积累的梯度。 optimizer.zero_grad() # 计算梯度 loss.backward() # 更新梯度 optimizer.step()>
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】基于Pytorch多层感知机的高级API实现和注意力机制(一) https://www.yhzz.com.cn/a/11709.html