
1 代码实现
通过高级API更简洁地实现多层感知机 import torch from torch import nn from d2l import torch as d2l
与softmax回归的简洁实现相比,唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。第一层是[隐藏层],它(包含256个隐藏单元,并使用了ReLU激活函数)。第二层是输出层 net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights);
[训练过程]的实现与我们实现softmax回归时完全相同,这种模块化设计使我们能够将与和模型架构有关的内容独立出来。 batch_size, lr, num_epochs = 256, 0.1, 10 loss = nn.CrossEntropyLoss() trainer = torch.optim.SGD(net.parameters(), lr=lr) train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
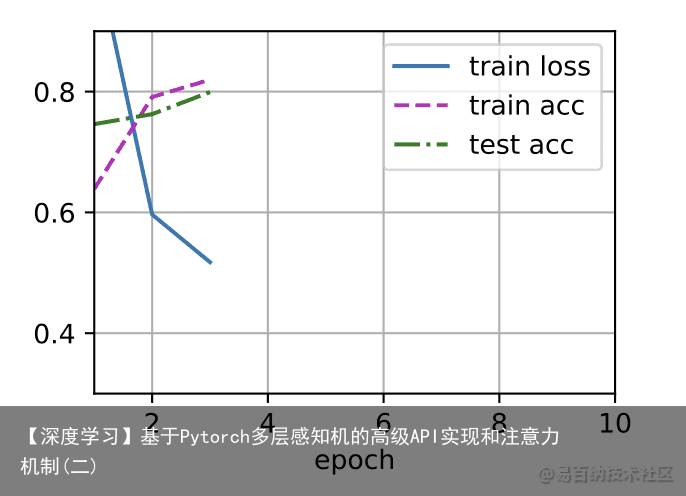
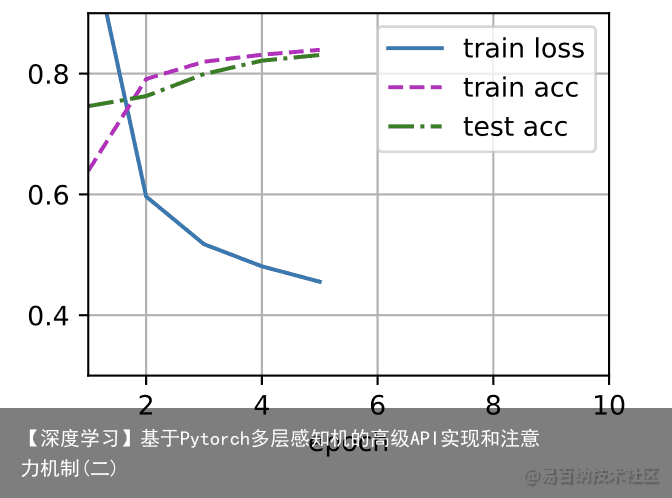
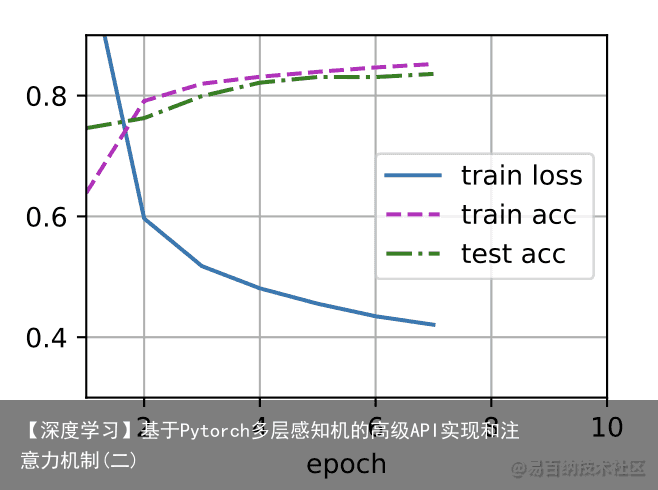
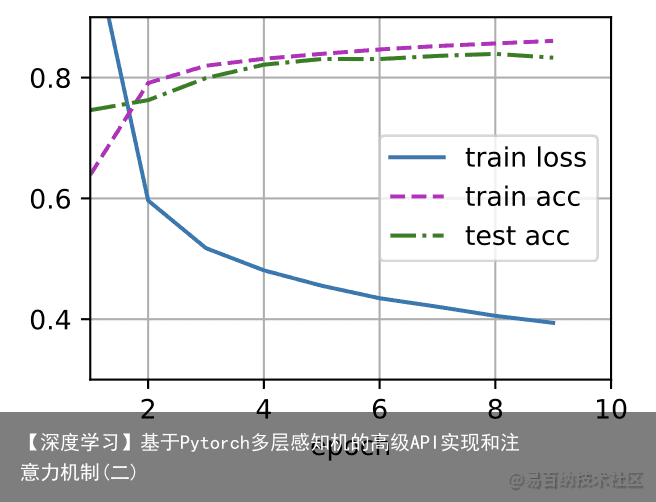
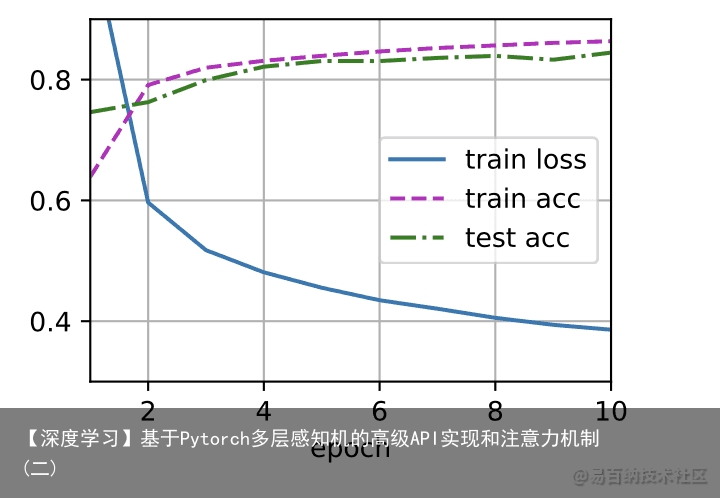
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save animator = Animator(xlabel=epoch, xlim=[1, num_epochs], ylim=[0.3, 0.9], legend=[train loss, train acc, test acc]) for epoch in range(num_epochs): train_metrics = train_epoch_ch3(net, train_iter, loss, updater) test_acc = evaluate_accuracy(net, test_iter) animator.add(epoch + 1, train_metrics + (test_acc,)) train_loss, train_acc = train_metrics assert train_loss < 0.5, train_loss assert train_acc <= 1 and train_acc > 0.7, train_acc assert test_acc <= 1 and test_acc > 0.7, test_acc def train_epoch_ch3(net, train_iter, loss, updater): #@save ” # 训练损失总和、训练准确度总和、样本数 metric = Accumulator(3) if isinstance(updater, gluon.Trainer): updater = updater.step for X, y in train_iter: # 计算梯度并更新参数 with autograd.record(): y_hat = net(X) l = loss(y_hat, y) l.backward() updater(X.shape[0]) metric.add(float(l.sum()), accuracy(y_hat, y), y.size) # 返回训练损失和训练准确率 return metric[0] / metric[2], metric[1] / metric[2] 2 训练误差和泛化误差 *训练误差*(training error)是指,我们的模型在训练数据集上计算得到的误差。*泛化误差*(generalization error)是指,当我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望。
问题是,我们永远不能准确地计算出泛化误差。这是因为无限多的数据样本是一个虚构的对象。在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的、未曾在训练集中出现的数据样本构成。
下面的三个思维实验将有助于更好地说明这种情况。假设一个大学生正在努力准备期末考试。一个勤奋的学生会努力做好练习,并利用往年的考试题目来测试自己的能力。尽管如此,在过去的考试题目上取得好成绩并不能保证他会在真正考试时发挥出色。例如,学生可能试图通过死记硬背考题的答案来做准备。他甚至可以完全记住过去考试的答案。另一名学生可能会通过试图理解给出某些答案的原因来做准备。在大多数情况下,后者会考得更好。
类似地,考虑一个简单地使用查表法来回答问题的模型。如果允许的输入集合是离散的并且相当小,那么也许在查看许多训练样本后,该方法将执行得很好。但当面对这个模型从未见过的例子时,它表现的可能比随机猜测好不到哪去。这是因为输入空间太大了,远远不可能记住每一个可能的输入所对应的答案。例如,考虑$28\times28$的灰度图像。如果每个像素可以取$256$个灰度值中的一个,则有$256^{784}$个可能的图像。这意味着指甲大小的低分辨率灰度图像的数量比宇宙中的原子要多得多。即使我们可能遇到这样的数据,我们也不可能存储整个查找表。
最后,考虑尝试根据一些可用的上下文特征对掷硬币的结果(类别0:正面,类别1:反面)进行分类的问题。假设硬币是公平的。无论我们想出什么算法,泛化误差始终是$\frac{1}{2}$。然而,对于大多数算法,我们应该期望训练误差会更低(取决于运气)。考虑数据集{0,1,1,1,0,1}。我们的算法不需要额外的特征,将倾向于总是预测多数类,从我们有限的样本来看,它似乎是1。在这种情况下,总是预测类1的模型将产生$\frac{1}{3}$的误差,这比我们的泛化误差要好得多。当我们逐渐增加数据量,正面比例明显偏离$\frac{1}{2}$的可能性将会降低,我们的训练误差将与泛化误差相匹配。 3 模型复杂性
当我们有简单的模型和大量的数据时,我们期望泛化误差与训练误差相近。当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。模型复杂性由什么构成是一个复杂的问题。一个模型是否能很好地泛化取决于很多因素。例如,具有更多参数的模型可能被认为更复杂。参数有更大取值范围的模型可能更为复杂。通常,对于神经网络,我们认为需要更多训练迭代的模型比较复杂,而需要“提前停止”(early stopping)的模型(意味着具有较少训练迭代周期)就不那么复杂。
很难比较本质上不同大类的模型之间(例如,决策树与神经网络)的复杂性。就目前而言,一条简单的经验法则相当有用:统计学家认为,能够轻松解释任意事实的模型是复杂的,而表达能力有限但仍能很好地解释数据的模型可能更有现实用途。在哲学上,这与波普尔的科学理论的可证伪性标准密切相关:如果一个理论能拟合数据,且有具体的测试可以用来证明它是错误的,那么它就是好的。这一点很重要,因为所有的统计估计都是事后归纳,也就是说,我们在观察事实之后进行估计,因此容易受到相关谬误的影响。目前,我们将把哲学放在一边,坚持更切实的问题。
在本节中,为了给你一些直观的印象,我们将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。 训练样本的数量。即使你的模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。 4 多项式回归 import math import numpy as np import torch from torch import nn from d2l import torch as d2l
4.1 生成数据集
首先,我们需要数据。给定$x$,我们将[使用以下三阶多项式来生成训练和测试数据的标签:]
(
$$y = 5 + 1.2x – 3.4\frac{x^2}{2!} + 5.6 \frac{x^3}{3!} + \epsilon \text{ where } \epsilon \sim \mathcal{N}(0, 0.1^2).$$ )
噪声项$\epsilon$服从均值为0且标准差为0.1的正态分布。在优化的过程中,我们通常希望避免非常大的梯度值或损失值。这就是我们将特征从$x^i$调整为$\frac{x^i}{i!}$的原因,这样可以避免很大的$i$带来的特别大的指数值。我们将为训练集和测试集各生成100个样本。 max_degree = 20 # 多项式的最大阶数 n_train, n_test = 100, 100 # 训练和测试数据集大小 true_w = np.zeros(max_degree) # 分配大量的空间 true_w[0:4] = np.array([5, 1.2, -3.4, 5.6]) features = np.random.normal(size=(n_train + n_test, 1)) np.random.shuffle(features) poly_features = np.power(features, np.arange(max_degree).reshape(1, -1)) for i in range(max_degree): poly_features[:, i] /= math.gamma(i + 1) # `gamma(n)` = (n-1)! # `labels`的维度: (`n_train` + `n_test`,) labels = np.dot(poly_features, true_w) labels += np.random.normal(scale=0.1, size=labels.shape) # NumPy ndarray转换为tensor true_w, features, poly_features, labels = [torch.tensor(x, dtype= torch.float32) for x in [true_w, features, poly_features, labels]]
4.2 对模型进行训练和测试
def evaluate_loss(net, data_iter, loss): #@save “””评估给定数据集上模型的损失。””” metric = d2l.Accumulator(2) # 损失的总和, 样本数量 for X, y in data_iter: out = net(X) y = y.reshape(out.shape) l = loss(out, y) metric.add(l.sum(), l.numel()) return metric[0] / metric[1] def train(train_features, test_features, train_labels, test_labels, num_epochs=400): loss = nn.MSELoss() input_shape = train_features.shape[-1] # 不设置偏置,因为我们已经在多项式特征中实现了它 net = nn.Sequential(nn.Linear(input_shape, 1, bias=False)) batch_size = min(10, train_labels.shape[0]) train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)), batch_size) test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)), batch_size, is_train=False) trainer = torch.optim.SGD(net.parameters(), lr=0.01) animator = d2l.Animator(xlabel=epoch, ylabel=loss, yscale=log, xlim=[1, num_epochs], ylim=[1e-3, 1e2], legend=[train, test]) for epoch in range(num_epochs): d2l.train_epoch_ch3(net, train_iter, loss, trainer) if epoch == 0 or (epoch + 1) % 20 == 0: animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss), evaluate_loss(net, test_iter, loss))) print(weight:, net[0].weight.data.numpy())
4.3 三阶多项式函数拟合(正态)
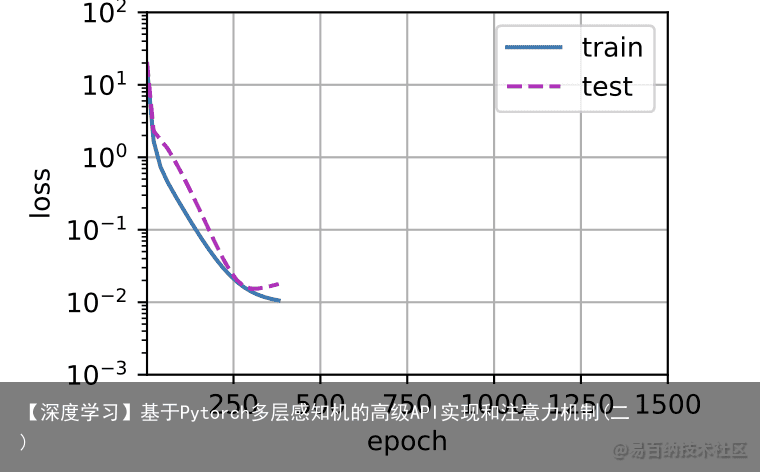
我们将首先使用三阶多项式函数,它与数据生成函数的阶数相同。结果表明,该模型能有效降低训练损失和测试损失。学习到的模型参数也接近真实值$w = [5, 1.2, -3.4, 5.6] # 从多项式特征中选择前4个维度,即 1, x, x^2/2!, x^3/3! train(poly_features[:n_train, :4], poly_features[n_train:, :4], labels[:n_train], labels[n_train:])
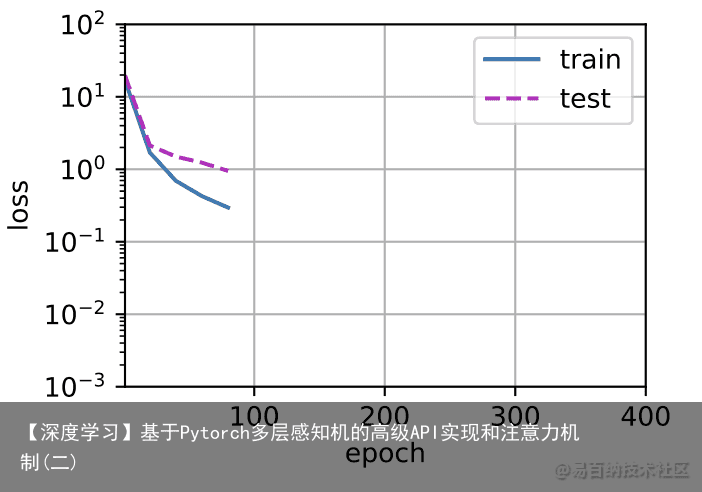
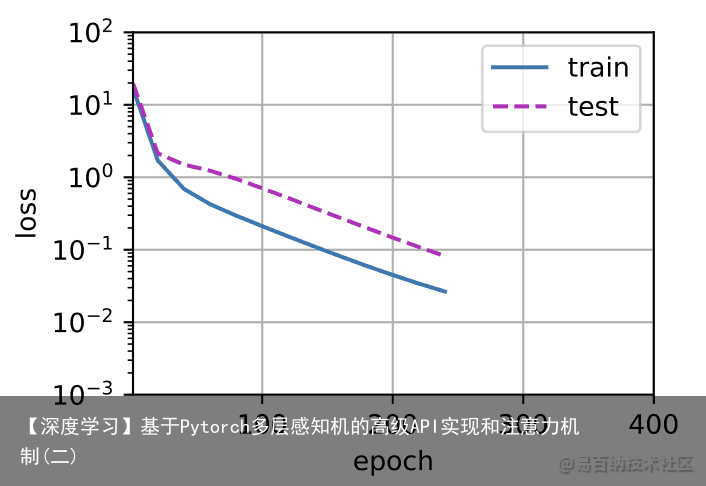
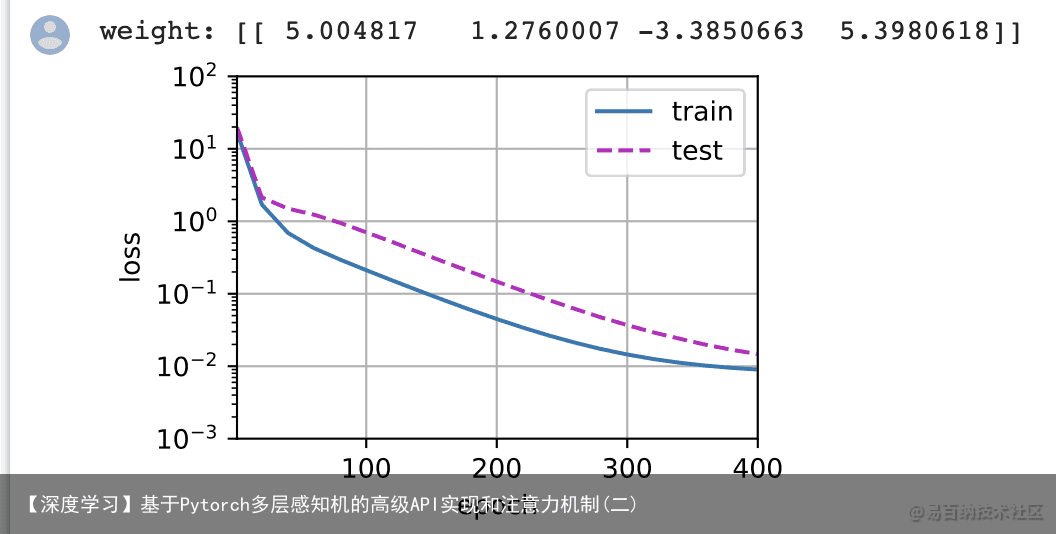
4.4 线性函数拟合(欠拟合)
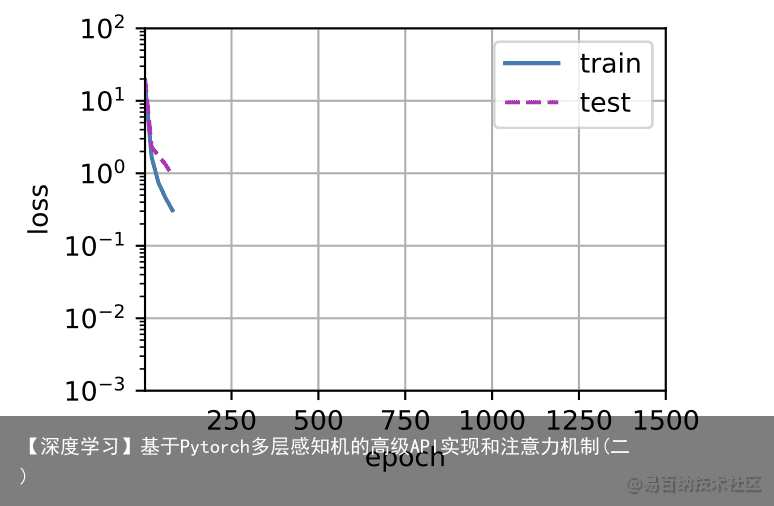
让我们再看看线性函数拟合。在经历了早期的下降之后,进一步减少该模型的训练损失变得困难。在最后一个迭代周期完成后,训练损失仍然很高。当用来拟合非线性模式(如这里的三阶多项式函数)时,线性模型容易欠拟合。 # 从多项式特征中选择前2个维度,即 1, x train(poly_features[:n_train, :2], poly_features[n_train:, :2], labels[:n_train], labels[n_train:])
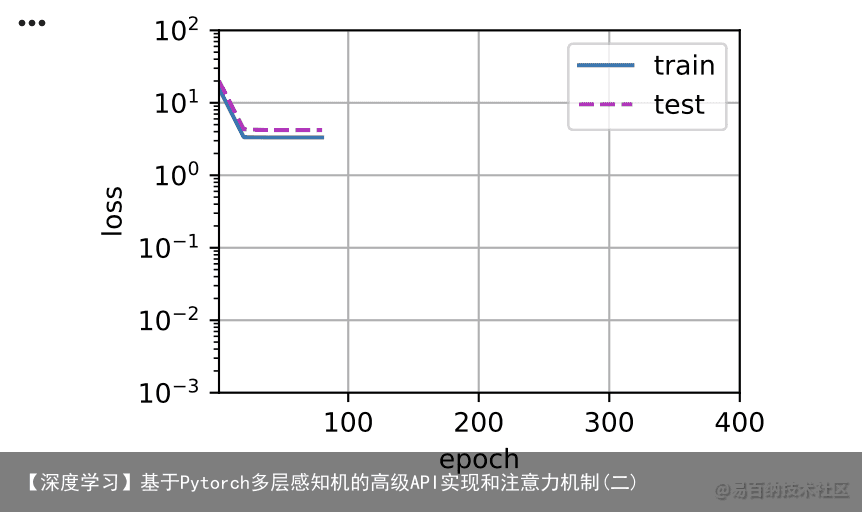
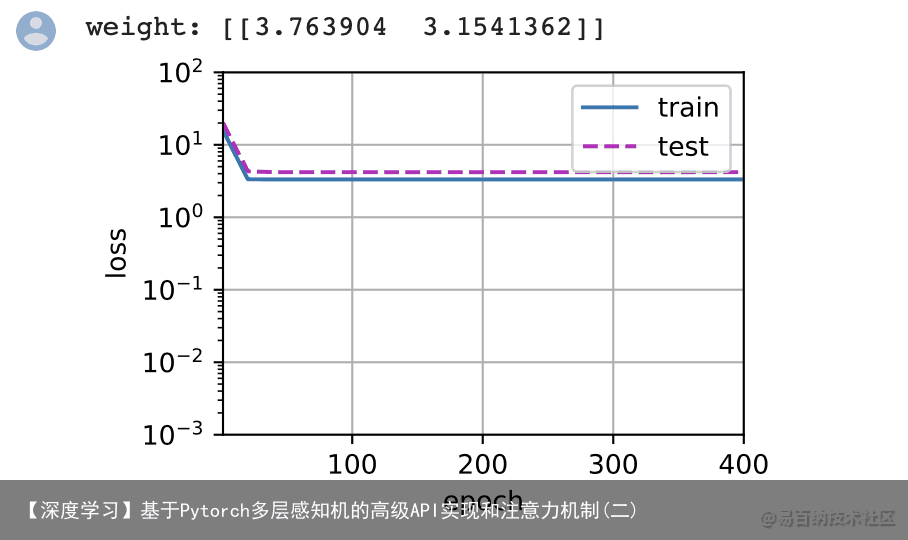
4.5 高阶多项式函数拟合(过拟合)
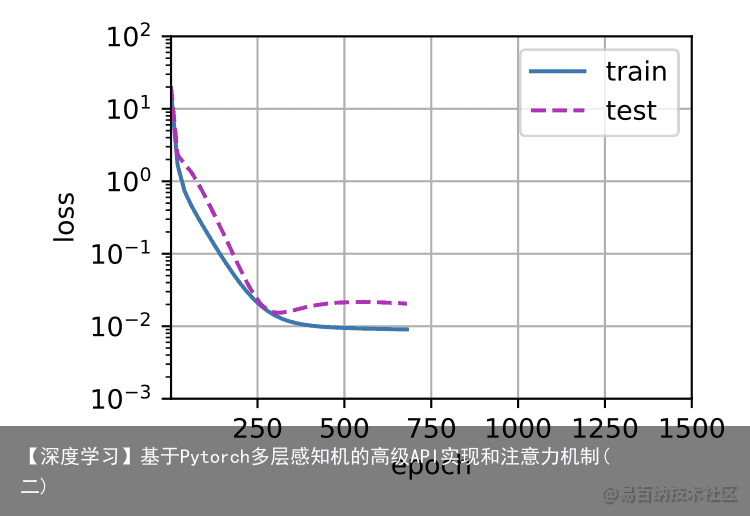
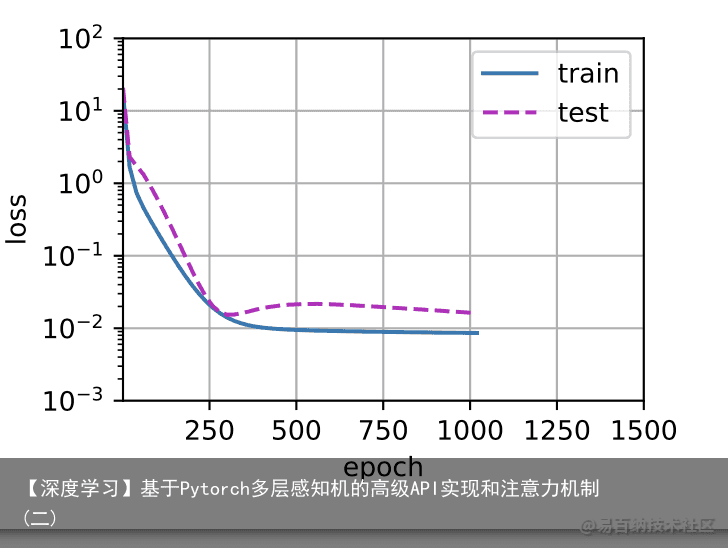
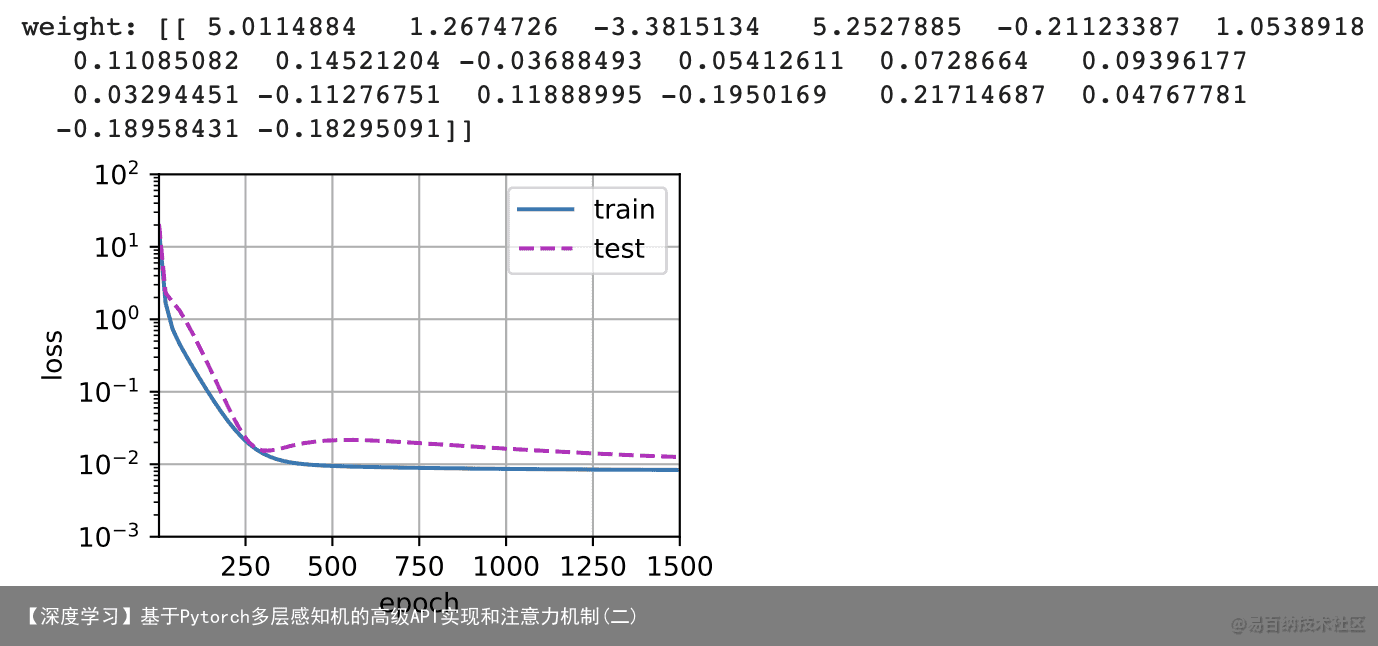
现在,让我们尝试使用一个阶数过高的多项式来训练模型。在这种情况下,没有足够的数据用于学到高阶系数应该具有接近于零的值。因此,这个过于复杂的模型会轻易受到训练数据中噪声的影响。虽然训练损失可以有效地降低,但测试损失仍然很高。结果表明,复杂模型对数据造成了过拟合。 # 从多项式特征中选取所有维度 train(poly_features[:n_train, :], poly_features[n_train:, :], labels[:n_train], labels[n_train:], num_epochs=1500)
5 注意力机制与Transformer
严格来说,注意力机制更像是一种方法论。没有严格的数学定义,而是根据具体任务目标,对关注的方向和加权模型进行调整。
简单的理解就是,在神经网络的隐藏层,增加注意力机制的加权。
使不符合注意力模型的内容弱化或者遗忘。 Transformer由Google Brain团队于2017年在论文Attention is all you need中提出,其将自注意力作为网络结构中的一层,采用seq2seq模型中的encoder-decoder框架,仅仅使用自注意力和前馈网络来进行编码和解码。如图1(a)(b)所示,Transformer的编码器和解码器都由6个小块组成,最后一级编码块的输出就是每一级解码块的输入。
CNN或RNN只能表征输入信息的短距离相关,即使是引入门控机制的LSTM,所表征的也只是一种“长的短期记忆”(long short-term memory),换言之,LSTM只能表征与其结构如榫卯般契合的、特定的长距离相关。另一方面,全连接网络是一种非常直接的建模远距离依赖的模型,但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,使得权重与数据本身的重要性相关。

免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】基于Pytorch多层感知机的高级API实现和注意力机制(二) https://www.yhzz.com.cn/a/11707.html