绪论
近几年来,在边缘设备上运行AI算法模型的研究以及相关设计层出不穷。笔者的课题也与该方向有一定关联,因此写下此文记录并分享,方便以后回看。一般来说,实现AI模型的运行需要2个核心部件,即控制单元和计算单元。前者一般就是MCU或者状态机等等,后者一般是DPU, VPU, TPU等叫法不一,专业名词并不重要,但其实本质都是一个高通量的阵列计算单元,包含卷积、池化、element-wise、batch-norm等operation,并具备存储和数据交互的能力。简单来说,用户配置控制单元后,控制单元将要计算的数据、与计算相关配置参数从外部存储器件读入至计算单元中,该单元计算完数据以后再将结果写入到外部存储器。若算力不支持一次算完,则调度多次即可。近几年RISC-V发展火爆,因此,本文采用计划采用一个开源的RISC-V核作为控制单元,又由于笔者此前调试过蜂鸟E203,所以控制单元采用该核,该核的具体移植使用方法和环境配置请参考《一、RISC-V 蜂鸟E203 FPGA完全移植手册》。关于计算单元,本文将采用实验室产品,由笔者所在实验室开发的多精度(支持1bit,2bit,4bit,8bit的整型乘法)脉动阵列(32×32)AI加速器。本文仅大致介绍开发思路,无开发细节。(PS. 本工程不开源,不出售,maybe以后会有流片计划)。当然,为了让读者也能够部署类似的环境,笔者会分享一些开源的设计,有兴趣的读者可以魔改拼接实现。链接如下:
risc-v:https://github.com/riscv-mcu/e203_hbirdv2
加速器:https://github.com/dhm2013724/yolov2_xilinx_fpga
该AI加速器采用HLS开发,用AXI bus控制,在Xilinx家的开发板上移植较便利。
环境搭建
⭐系统框架
系统框架如下图所示:
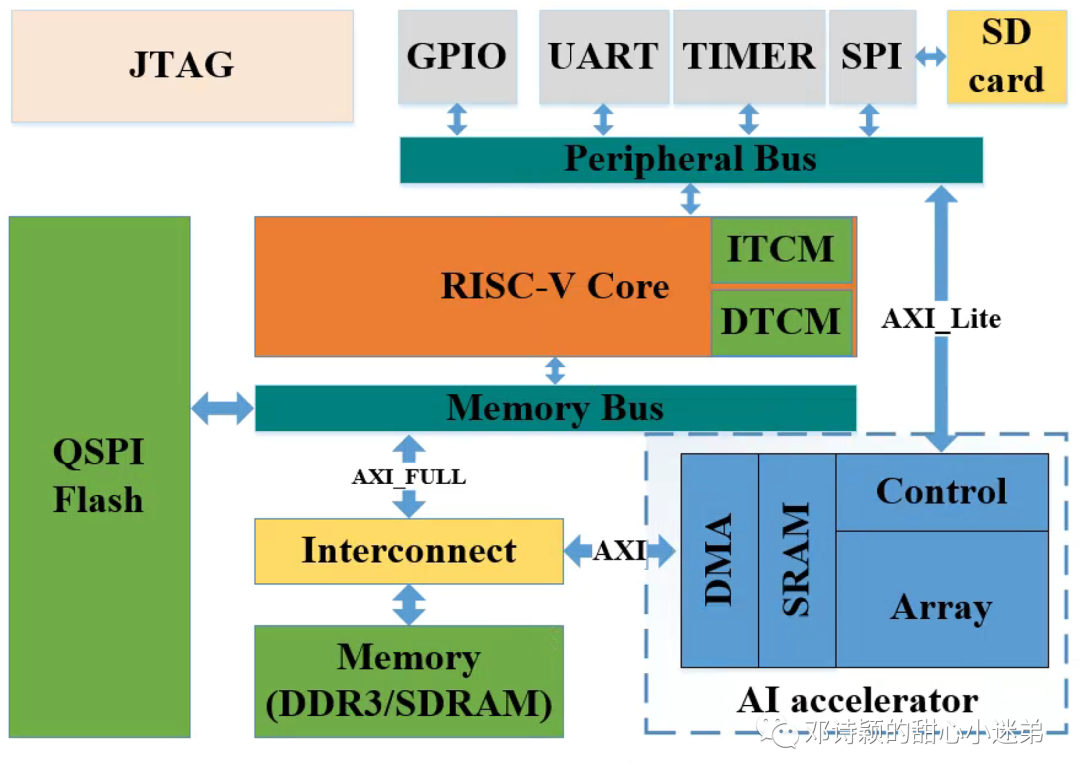
在搭建好硬件或者仿真平台,开发完C语言代码完成编译并将程序download以后,整个工作流程如下:
1.RISC-V core通过SPI接口驱动SD卡并将SD卡中的权重数据经Memory BUS通过AXI-FULL总线load进Memory中。
2.RISC-V core经Perip Bus通过AXI-lite总线配置AI加速器中的控制寄存器以完成不同的AI算子计算。
3.AI加速器根据寄存器中的信息控制DMA从Memory中读取相应的数据到加速器的SRAM中。
4.SRAM中数据Ready以后,Array计算阵列从SRAM中获取数据并完成计算。
5.计算结果通过DMA输出至Memory中。
6.若计算的数据量过大,Array算力不够,则重复步骤3,4,5直到计算完毕。
7.RISC-V core会在计算过程中轮询加速器中的一个状态寄存器的数值来判断计算是否结束,结束以后退出轮询,输出最终结果,即计算完毕。
P.S. Memory单元根据具体实际硬件选择,有资源当然选性能最好的DDR。
⭐RISC-V环境搭建
细节请参考《一、RISC-V 蜂鸟E203 FPGA完全移植手册》,主要有RTL的仿真环境和C代码编译环境。另外补充一点,官方在github链接上有命令为tb的文件夹。笔者后续均以此文件夹下的testbench为蓝本做设计,并且在VCS平台下仿真。具体关注tb文件夹和vsim文件夹中的脚本。
⭐加速器环境搭建
加速器的设计细节不便细说。本设计为了兼容流片和一般的仿真,在RTL仿真平台下采用宏定义区别了2种情况。第一种就是用reg模拟SRAM,方便直接部署进FPGA中,第二种就是用第三方memory compiler生成对应流片工艺节点的SRAM macro。在设计中,主要通过Slave-AXI-Lite总线读写加速器的寄存器,Master-AXI-FULL总线从Memory中读写数据(权重、特征图等)。本设计支持多精度(1bit,2bit,4bit,8bit)的整型数计算,并支持可拆分,Array阵列的大小为32×32(INT8*INT8)。读者可去Github上折腾一个开源的加速器替代即可。
⭐Memory环境搭建
Xilinx家的中高端FPGA开发板都集成了板载DDR3,一般通过MIG IP配置,支持AXI总线,所以在FPGA中部署十分方便。为了既能支持FPGA平台,又能支持一般的RTL仿真。笔者采用宏定义区别以上2种情况,在VCS仿真环境下用reg模拟一个大Size的Memory替代MIG IP,支持AXI bus。当然,直接使用vivado下的仿真环境就不用考虑上述问题。Moreover,使用reg替代DDR仿真也不可能流片,主要是DDR PHY IP贵的离谱。
⭐RSIC-V & AI加速器系统级联
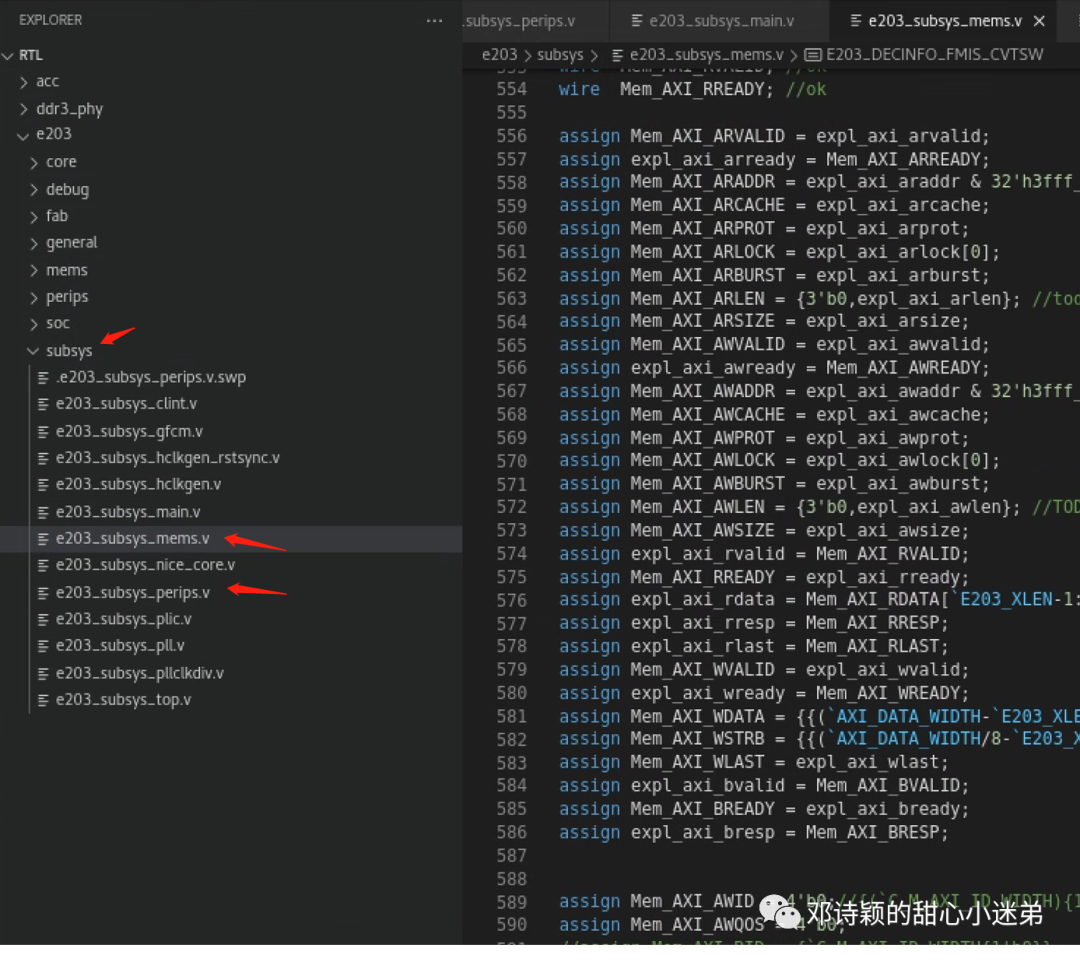
如下图所示,Memory Bus和 Peri Bus主要通过subsys文件夹下的红色箭头处的2个文件配置。此处,笔者可细心查阅一下地址分配,在Peri Bus上有一段初始为0x10041000的地址已预留好现成的AXI总线,通过一些修改后可以连到加速器的Slave-AXI-Lite接口上;在Memory Bus上有一段初始为0x40000000的地址同样如此,加速器的Master-AXI-FULL接口和RISC-V都需连接到上述Memory环境中进行读写操作,如上述系统图所示。note:由于RISC-V和加速器均要访问这块Memory,所以笔者魔改了一个axi的interconnect的设计(纯RTL的简单设计,不是vivado自带的axi-interconnect IP),即一个2Master1Slave的设计。
开发样例测试
⭐RTL代码
在上述步骤完成以后,整理出3个部分的RTL代码。分别是AI加速器,Memory单元(Reg替代),修改后的e203。将vsim文件夹下仿真脚本修改,添加对应的文件。

⭐C代码开发
本文仅演示一个卷积层的运算。设置Image大小10*10,Kernel大小5*5,输入通道为1,输出通道为10,Stride为1,Padding为0。配置任意权重以及Image数据,通RISC-V核本身计算该卷积(soft)以及RISC-V控制AI加速器计算该卷积(hard)来比较输出是否正确。代码细节略过···

⭐C代码编译
细节请参考《一、RISC-V 蜂鸟E203 FPGA完全移植手册》。此处强调一下,编译后文件夹下会生成.verilog的文件,与.bin文件内容相似。testbench使用.verilog文件将程序load进RISC-V中。为了便捷,笔者此处使用ilm模式download,未使用flash/flashxip模式,此三种模式均已在FPGA上验证过,无问题。

⭐Testbench测试
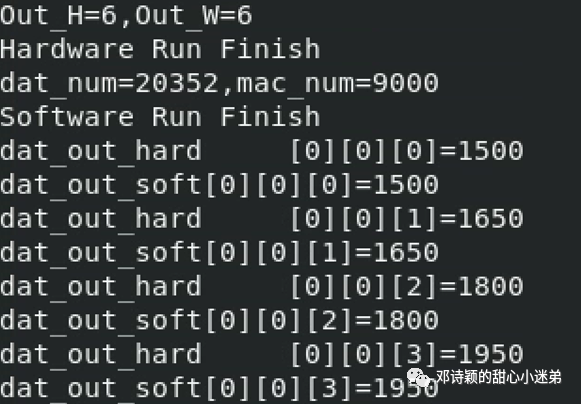
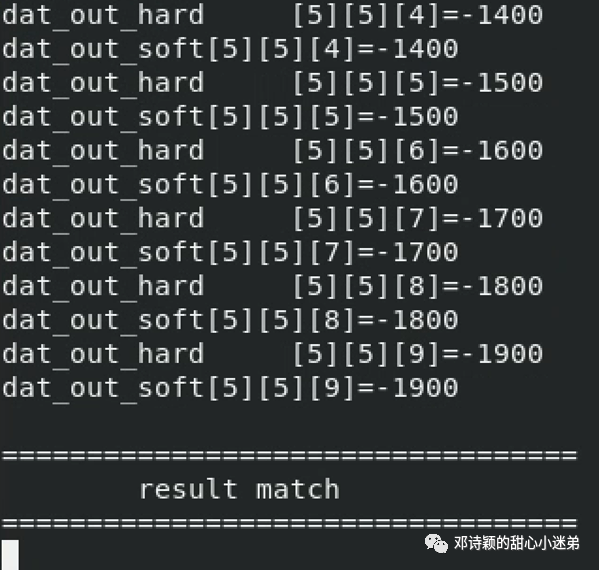
如上文所示,读者细读完vsim文件夹下脚本即可知如何修改脚本进行测试,此处略。VCS下运行部分结果如下。(PS. 仿真速度真的很慢,很慢,很慢。。。)
输出结果均匹配:
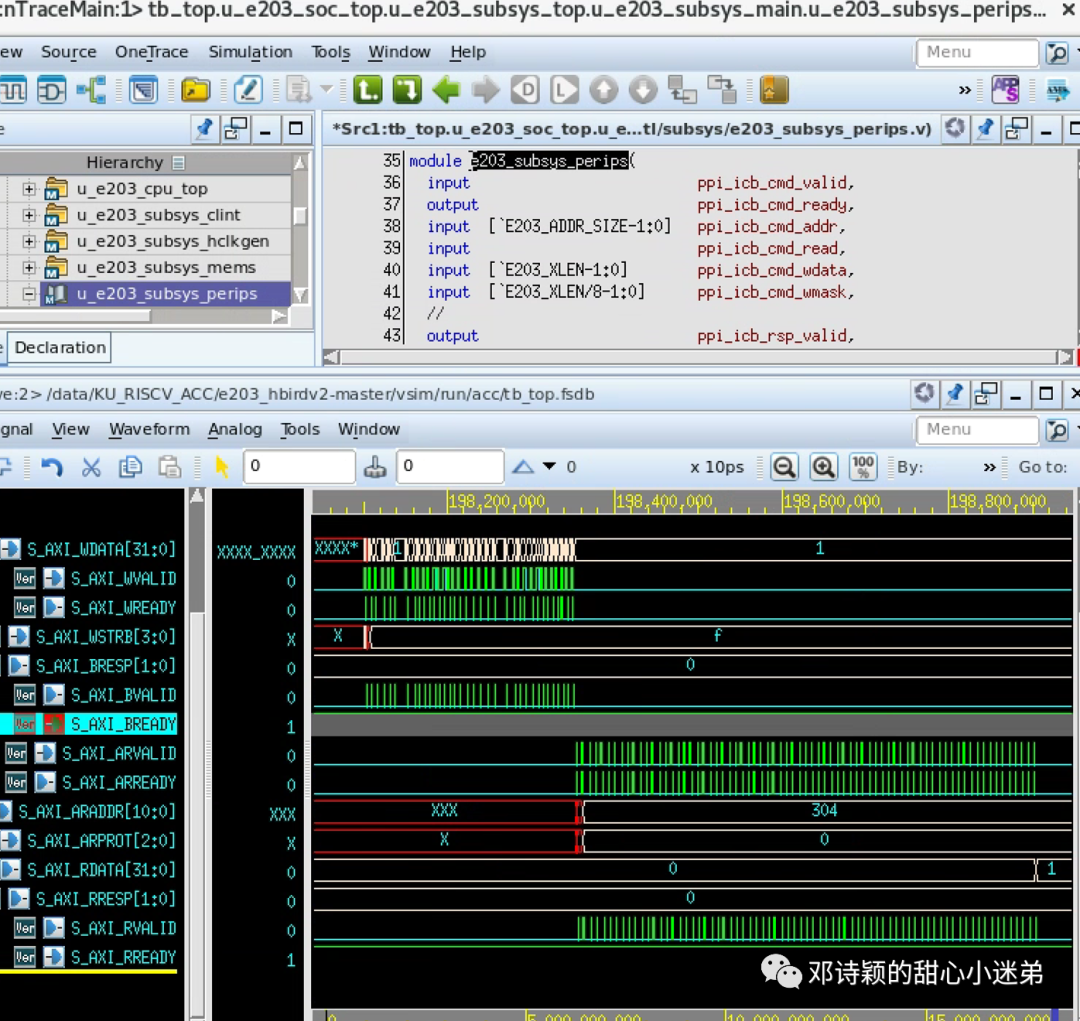
通过Verdi查看仿真波形:
总结
加速器已验证过的模型:MNIST, VGG16和Resnet。
哎,唉,😔。真没意思。
If you like my channel,please toss the coin, hit like, and favorite it.
转载:全栈芯片工程师
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:RISC-V + AI加速器-riot加速器 https://www.yhzz.com.cn/a/10038.html